

win10环境实现yolov5 TensorRT加速试验(环境配置+训练+推理)

文章目录
1、环境安装
参考上一篇博客WIN10安装配置TensorRT详解
对于高版本的cuda/cudnn,需要注意在环境变量里面新建CUDA_MODULE_LOADING环境变量,如下所示: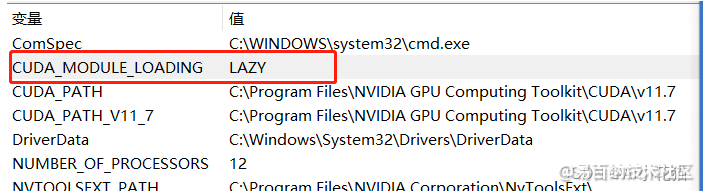
2、模型训练
本文的模型训练主要使用的git仓库版本为yolov5-6.1
模型训练主要分为如下几步:
2.1 数据准备
参考yolov5的数据集格式,准备数据集如下:
生成txt文件转换的代码如下所示:
import os
import shutil
import xml.etree.ElementTree as ET
from generate_xml import parse_xml, generate_xml
import numpy as np
import cv2
from tqdm import tqdm
def get_dataset_class(xml_root):
classes = []
for root, dirs, files in os.walk(xml_root):
if files is not None:
for file in files:
if file.endswith('.xml'):
xml_path = os.path.join(root, file)
dict_info = parse_xml(xml_path)
classes.extend(dict_info['cat'])
return list(set(classes))
def convert(size, bbox):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
center_x = (bbox[0] + bbox[2]) / 2.0
center_y = (bbox[1] + bbox[3]) / 2.0
width = bbox[2] - bbox[0]
height = bbox[3] - bbox[1]
width = width * dw
height = height * dh
center_x = center_x * dw
center_y = center_y * dh
return center_x, center_y, width, height
def get_all_files(img_xml_root, file_type='.xml'):
img_paths = []
xml_paths = []
# get all files
for root, dirs, files in os.walk(img_xml_root):
if files is not None:
for file in files:
if file.endswith(file_type):
file_path = os.path.join(root, file)
if file_type in ['.xml']:
img_path = file_path[:-4] + '.jpg'
if os.path.exists(img_path):
xml_paths.append(file_path)
img_paths.append(img_path)
elif file_type in ['.jpg']:
xml_path = file_path[:-4] + '.xml'
if os.path.exists(xml_path):
img_paths.append(file_path)
xml_paths.append(xml_path)
elif file_type in ['.json']:
img_path = file_path[:-5] + '.jpg'
if os.path.exists(img_path):
img_paths.append(img_path)
xml_paths.append(file_path)
return img_paths, xml_paths
def train_test_split(img_paths, xml_paths, test_size=0.2):
img_xml_union = list(zip(img_paths, xml_paths))
np.random.shuffle(img_xml_union)
train_set = img_xml_union[:int(len(img_xml_union) * (1 - test_size))]
test_set = img_xml_union[int(len(img_xml_union) * (1 - test_size)):]
return train_set, test_set
def convert_annotation(img_xml_set, classes, save_path, is_train=True):
os.makedirs(os.path.join(save_path, 'images', 'train' if is_train else 'val'), exist_ok=True)
img_root = os.path.join(save_path, 'images', 'train' if is_train else 'val')
os.makedirs(os.path.join(save_path, 'labels', 'train' if is_train else 'val'), exist_ok=True)
txt_root = os.path.join(save_path, 'labels', 'train' if is_train else 'val')
for item in tqdm(img_xml_set):
img_path = item[0]
txt_file_name = os.path.split(img_path)[-1][:-4] + '.txt'
shutil.copy(img_path, img_root)
img = cv2.imread(img_path)
size = (img.shape[1], img.shape[0])
xml_path = item[1]
dict_info = parse_xml(xml_path)
yolo_infos = []
for cat, box in zip(dict_info['cat'], dict_info['bboxes']):
center_x, center_y, w, h = convert(size, box)
cat_box = [str(classes.index(cat)), str(center_x), str(center_y), str(w), str(h)]
yolo_infos.append(' '.join(cat_box))
if len(yolo_infos) > 0:
with open(os.path.join(txt_root, txt_file_name), 'w', encoding='utf_8') as f:
for info in yolo_infos:
f.writelines(info)
f.write('\n')
if __name__ == '__main__':
xml_root = r'dataset\man'
save_path = r'dataset\man\yolo'
os.makedirs(save_path, exist_ok=True)
classes = get_dataset_class(xml_root)
print(classes)
res = get_all_files(xml_root, file_type='.xml')
train_set, test_set = train_test_split(res[0], res[1], test_size=0.2)
convert_annotation(train_set, classes, save_path, is_train=True)
convert_annotation(test_set, classes, save_path, is_train=False)
新建一个demo.yaml,依据coco128.yaml的格式进行编写,具体如下所示:
选择需要用到的模型,并更新里面的类别数量为自己的训练集数量,具体如下所示:
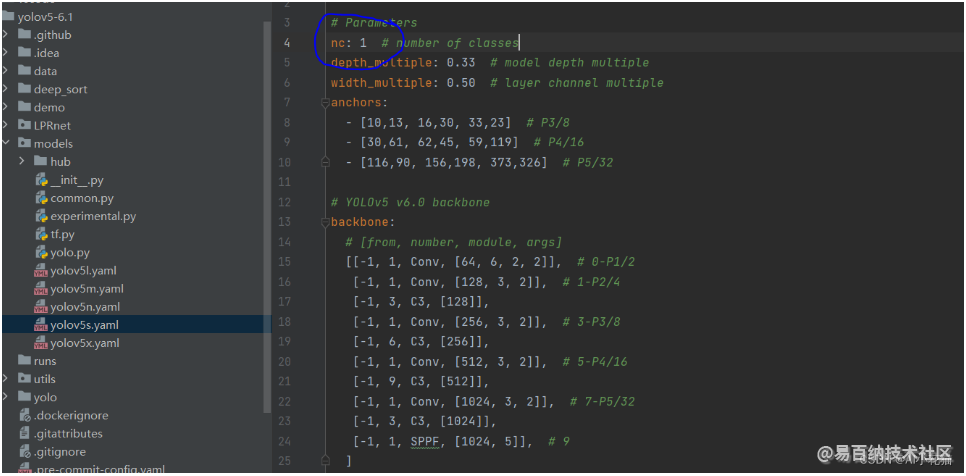
2.2 模型训练
打开yolov5-6.1的的train.py的训练代码,以下为args中的参数解析:
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='/home/ubuntu/cb/workspace/yolov5-6.1/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='/home/ubuntu/cb/workspace/deepsort_yolov5/yolov5-6.1/models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='/home/ubuntu/cb/workspace/deepsort_yolov5/yolov5-6.1/data/jiaotong.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=200)
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
本文使用如下命令进行训练
python train.py --weights yolov5s.pt --cfg models/yolov5s.yaml --data data/jiaotong.yaml --batch-size 64 --multi-scale --device 0,1
3、模型转换
本文实现路线为:
model.pt->model.onnx->model.engine的方式
3.1 模型转换为onnx
模型的pt文件转换为onnx需要考虑如下几点:
1、是否要将后处理放在转换为onnx的过程中,这个可以参考yolov8-TensorRT end2end的实现上
2、输出结果是三个scale的,是否需要预先合并输出,方便后续编码
本文模型导出使用的是如下链接的export的代码:https://github.com/linghu8812/yolov5
转换成功后可以使用使用netron进行结构可视化,具体地址如下:netron
本文转换好的onnx部分截图如下所示: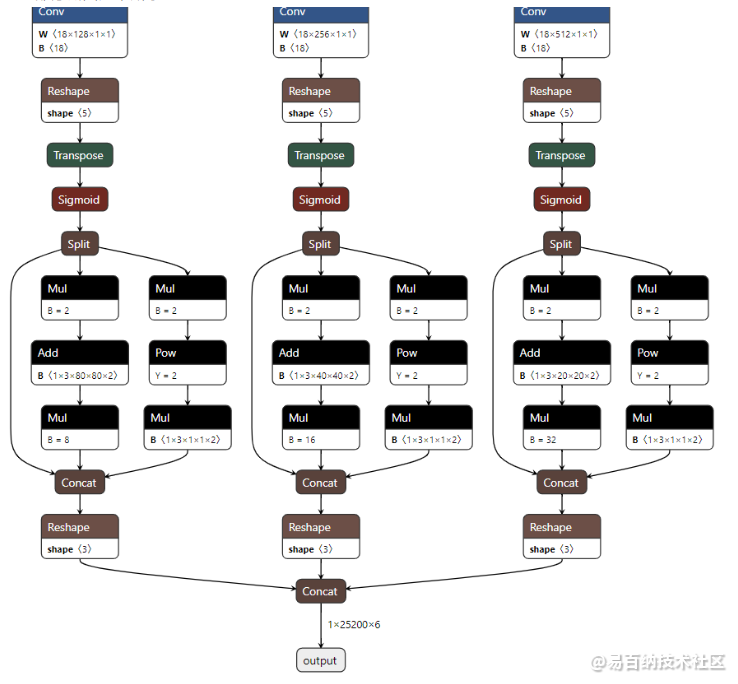
3.2 模型转换为engine
onnx模型转换为engine的方式有如下几种:
1、最简单的方式是使用TensorRT的bin文件夹下的trtexec.exe可执行文件
2、使用python/c++代码生成engine,具体参考英伟达官方TensorRT的engine生成
本文使用最简单的进行engine的生成,具体如下:
将ONNX模型转换为静态batchsize的TensorRT模型,如下所示:
trtexec.exe --onnx=best.onnx --saveEngine=best.engine
时间大概需要三五分钟才能完成构建。
上述没有指定精度,默认为32位,可以额外指定其他精度,把模型内的计算转换成 fp16 或者 int8 的类型,可以只开一个也可以两个都开,trtexec 会倾向于速度最快的方式(有些网络模块不支持 int8)
trtexec.exe --onnx=best.onnx --saveEngine=best.engine --fp16

trtexec命令的参数具体设定以及应用请参看TensorRT: TensorRT Command-Line Wrapper: trtexec (ccoderun.ca)
当然使用c++转换的的方式也是很简单的,代码如下所示:
int get_trtengine_yolo(Parameters_yolo& cfg) {
cout << "\n\n\n" << "\tbuilding yolo engine ,please wait .......\n\n" << endl;
IHostMemory* modelStream{ nullptr };
APIToModel(cfg, &modelStream);
assert(modelStream != nullptr);
std::ofstream p(cfg.engine_path, std::ios::binary);
if (!p)
{
std::cerr << "could not open plan output file" << std::endl;
return -1;
}
p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
modelStream->destroy();
cout << "\n\n" << "\tfinished yolo engine created" << endl;
return 0;
}
void APIToModel(Parameters_yolo& cfg, IHostMemory** modelStream)
{
// Create builder
IBuilder* builder = createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();
// Create model to populate the network, then set the outputs and create an engine
ICudaEngine* engine = createEngine(cfg, builder, config);
assert(engine != nullptr);
// Serialize the engine
(*modelStream) = engine->serialize();
// Close everything down
engine->destroy();
builder->destroy();
config->destroy();
}
转换后的生成的文件如下所示:
4、具体实现如下
实现方式可以参看之前的文章: onnx模型转engine并进行推理全过程解析
具体代码可以参看我的仓库:yolov5-6.1 c++ TensorRT加速推理代码
5、实际运行效果
实际运行效果如下图所示。
6、Python 版本实现TensorRT推理
上述为c++版本实现代码,为了方便理解和实现加速推理整个过程,文末附上python的实现过程,以方便理解c++代码
6.1、创建context
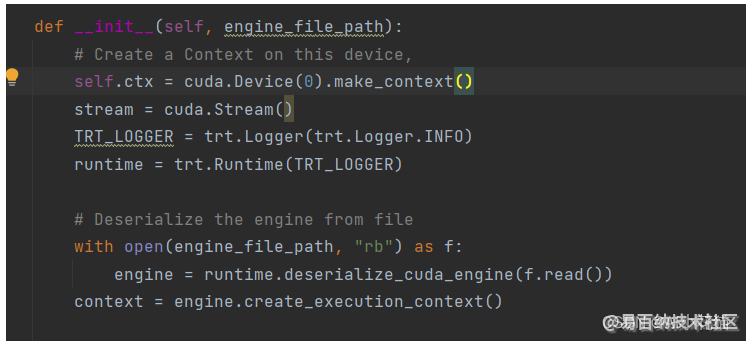
6.2 输入输出在host和device上分配内存

6.3 推理过程
推理主要包含:
1、图片获取并按照leterbox的方案进行resize和padding
2、图像从BGR->RGB,通道转换为nchw,并做归一化
3、图像数据copy到host buffer,迁移到GPU上进行推理

4、后处理首先获取所有的结果,并按照leterbox的方式进行还原,使用NMS去除低置信度的框,最终绘制到原图输出
需要注意的是推理前需要预热一下,以便推理的时间相对比较平稳
完整代码如下:
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import shutil
import random
import sys
import threading
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.4
LEN_ALL_RESULT = 151200 ##(20*20+40*40+80*80)*3*(num_cls+5) 一个batch长度
NUM_CLASSES = 1
OBJ_THRESH = 0.4
def get_img_path_batches(batch_size, img_dir):
ret = []
batch = []
for root, dirs, files in os.walk(img_dir):
for name in files:
if len(batch) == batch_size:
ret.append(batch)
batch = []
batch.append(os.path.join(root, name))
if len(batch) > 0:
ret.append(batch)
return ret
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
class YoLov5TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# Create a Context on this device,
self.ctx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
print('bingding:', binding, engine.get_tensor_shape(binding))
size = trt.volume(engine.get_tensor_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_tensor_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
self.input_w = engine.get_tensor_shape(binding)[-1]
self.input_h = engine.get_tensor_shape(binding)[-2]
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = engine.max_batch_size
def infer(self, raw_image_generator):
threading.Thread.__init__(self)
# Make self the active context, pushing it on top of the context stack.
self.ctx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# Do image preprocess
batch_image_raw = []
batch_origin_h = []
batch_origin_w = []
batch_input_image = np.empty(shape=[self.batch_size, 3, self.input_h, self.input_w])
for i, image_raw in enumerate(raw_image_generator):
input_image, image_raw, origin_h, origin_w = self.preprocess_image(image_raw)
batch_image_raw.append(image_raw)
batch_origin_h.append(origin_h)
batch_origin_w.append(origin_w)
np.copyto(batch_input_image[i], input_image)
batch_input_image = np.ascontiguousarray(batch_input_image)
# Copy input image to host buffer
np.copyto(host_inputs[0], batch_input_image.ravel())
start = time.time()
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# context.execute_async(batch_size=self.batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
end = time.time()
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# Do postprocess
for i in range(self.batch_size):
result_boxes, result_scores, result_classid = self.post_process(
output[i * LEN_ALL_RESULT: (i + 1) * LEN_ALL_RESULT], batch_origin_h[i], batch_origin_w[i],
batch_input_image[i]
)
if result_boxes is None:
continue
# Draw rectangles and labels on the original image
for j in range(len(result_boxes)):
box = result_boxes[j]
plot_one_box(
box,
batch_image_raw[i],
label="{}:{:.2f}".format(
categories[int(result_classid[j])], result_scores[j]
),
)
return batch_image_raw, end - start
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
def get_raw_image(self, image_path_batch):
"""
description: Read an image from image path
"""
for img_path in image_path_batch:
yield cv2.imread(img_path)
def get_raw_image_zeros(self, image_path_batch=None):
"""
description: Ready data for warmup
"""
for _ in range(self.batch_size):
yield np.zeros([self.input_h, self.input_w, 3], dtype=np.uint8)
def preprocess_image(self, raw_bgr_image):
"""
description: Convert BGR image to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = raw_bgr_image
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# Calculate widht and height and paddings
r_w = self.input_w / w
r_h = self.input_h / h
if r_h > r_w:
tw = self.input_w
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((self.input_h - th) / 2)
ty2 = self.input_h - th - ty1
else:
tw = int(r_h * w)
th = self.input_h
tx1 = int((self.input_w - tw) / 2)
tx2 = self.input_w - tw - tx1
ty1 = ty2 = 0
# Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, None, (128, 128, 128)
)
image = image.astype(np.float32)
# Normalize to [0,1]
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes numpy, each row is a box [center_x, center_y, w, h]
return:
y: A boxes numpy, each row is a box [x1, y1, x2, y2]
"""
y = np.zeros_like(x)
r_w = self.input_w / origin_w
r_h = self.input_h / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def post_process(self, output, origin_h, origin_w, img_pad):
# Reshape to a two dimentional ndarray
c, h, w = img_pad.shape
ratio_w = w / origin_w
ratio_h = h / origin_h
num_anchors = int(((h / 32) * (w / 32) + (h / 16) * (w / 16) + (h / 8) * (w / 8)) * 3)
pred = np.reshape(output, (num_anchors, 5 + NUM_CLASSES))
results = []
for detection in pred:
score = detection[5:]
classid = np.argmax(score)
confidence = score[classid]
if confidence > CONF_THRESH and detection[4] > OBJ_THRESH:
if ratio_h > ratio_w:
center_x = int(detection[0] / ratio_w)
center_y = int((detection[1] - (h - ratio_w * origin_h) / 2) / ratio_w)
width = int(detection[2] / ratio_w)
height = int(detection[3] / ratio_w)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
else:
center_x = int((detection[0] - (w - ratio_h * origin_w) / 2) / ratio_h)
center_y = int(detection[1] / ratio_h)
width = int(detection[2] / ratio_h)
height = int(detection[3] / ratio_h)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
results.append([x1, y1, x2, y2, confidence * detection[4], classid])
results = np.array(results)
if len(results) <= 0:
return None, None, None
# Do nms
boxes = self.non_max_suppression(results, origin_h, origin_w, conf_thres=CONF_THRESH, nms_thres=IOU_THRESHOLD)
result_boxes = boxes[:, :4] if len(boxes) else np.array([])
result_scores = boxes[:, 4] if len(boxes) else np.array([])
result_classid = boxes[:, 5] if len(boxes) else np.array([])
return result_boxes, result_scores, result_classid
def bbox_iou(self, box1, box2, x1y1x2y2=True):
"""
description: compute the IoU of two bounding boxes
param:
box1: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
box2: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
x1y1x2y2: select the coordinate format
return:
iou: computed iou
"""
if not x1y1x2y2:
# Transform from center and width to exact coordinates
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# Get the coordinates of the intersection rectangle
inter_rect_x1 = np.maximum(b1_x1, b2_x1)
inter_rect_y1 = np.maximum(b1_y1, b2_y1)
inter_rect_x2 = np.minimum(b1_x2, b2_x2)
inter_rect_y2 = np.minimum(b1_y2, b2_y2)
# Intersection area
inter_area = np.clip(inter_rect_x2 - inter_rect_x1 + 1, 0, None) * \
np.clip(inter_rect_y2 - inter_rect_y1 + 1, 0, None)
# Union Area
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
return iou
def non_max_suppression(self, prediction, origin_h, origin_w, conf_thres=0.5, nms_thres=0.4):
"""
description: Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
param:
prediction: detections, (x1, y1,x2, y2, conf, cls_id)
origin_h: original image height
origin_w: original image width
conf_thres: a confidence threshold to filter detections
nms_thres: a iou threshold to filter detections
return:
boxes: output after nms with the shape (x1, y1, x2, y2, conf, cls_id)
"""
# Get the boxes that score > CONF_THRESH
boxes = prediction[prediction[:, 4] >= conf_thres]
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
# boxes[:, :4] = self.xywh2xyxy(origin_h, origin_w, boxes[:, :4])
# clip the coordinates
boxes[:, 0] = np.clip(boxes[:, 0], 0, origin_w)
boxes[:, 2] = np.clip(boxes[:, 2], 0, origin_w)
boxes[:, 1] = np.clip(boxes[:, 1], 0, origin_h)
boxes[:, 3] = np.clip(boxes[:, 3], 0, origin_h)
# Object confidence
confs = boxes[:, 4]
# Sort by the confs
boxes = boxes[np.argsort(-confs)]
# Perform non-maximum suppression
keep_boxes = []
while boxes.shape[0]:
large_overlap = self.bbox_iou(np.expand_dims(boxes[0, :4], 0), boxes[:, :4]) > nms_thres
label_match = boxes[0, -1] == boxes[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
keep_boxes += [boxes[0]]
boxes = boxes[~invalid]
boxes = np.stack(keep_boxes, 0) if len(keep_boxes) else np.array([])
return boxes
def img_infer(yolov5_wrapper, image_path_batch):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image(image_path_batch))
for i, img_path in enumerate(image_path_batch):
parent, filename = os.path.split(img_path)
save_name = os.path.join('output', filename)
# Save image
cv2.imwrite(save_name, batch_image_raw[i])
print('input->{}, time->{:.2f}ms, saving into output/'.format(image_path_batch, use_time * 1000))
def warmup(yolov5_wrapper):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image_zeros())
print('warm_up->{}, time->{:.2f}ms'.format(batch_image_raw[0].shape, use_time * 1000))
if __name__ == "__main__":
engine_file_path = "yolov5s.engine"
categories = ['man']
if os.path.exists('output/'):
shutil.rmtree('output/')
os.makedirs('output/')
# a YoLov5TRT instance
yolov5_wrapper = YoLov5TRT(engine_file_path)
try:
print('batch size is', yolov5_wrapper.batch_size)
image_dir = r"dataset\ceshi"
image_path_batches = get_img_path_batches(yolov5_wrapper.batch_size, image_dir)
for i in range(5):
warmup(yolov5_wrapper)
for batch in image_path_batches:
img_infer(yolov5_wrapper, batch)
finally:
yolov5_wrapper.destroy()
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2733次2024-02-19 15:29:34
-
浏览量:1827次2023-07-20 11:05:58
-
浏览量:4863次2024-03-05 15:05:36
-
浏览量:1972次2023-12-29 14:41:17
-
浏览量:2536次2023-12-27 15:46:55
-
2024-12-10 10:34:18
-
浏览量:1399次2023-10-09 19:30:42
-
浏览量:5283次2021-09-30 15:04:23
-
浏览量:1520次2024-07-15 18:31:13
-
浏览量:4029次2022-03-05 15:51:50
-
浏览量:2005次2023-07-26 13:44:05
-
浏览量:4179次2024-02-20 13:54:36
-
浏览量:2500次2024-01-10 15:17:17
-
浏览量:1241次2023-06-03 16:03:04
-
浏览量:2627次2023-12-19 16:06:28
-
2024-02-02 14:41:10
-
浏览量:1606次2023-07-22 09:54:51
-
浏览量:3954次2024-01-18 18:05:38
-
2024-02-23 16:20:11

miko
不想加班~~~~




-
12篇
- 海思NNIE Hi3559量化部署Mobilefacenet与RetinaFace
- YOLOv8 AS-One:目标检测AS-One 来了!(YOLO就是名副其实的卷王之王)
- YOLOv5s部署在瑞芯微电子RK3399Pro中使用NPU进行加速推理
- AX620A运行yolov5s自训练模型全过程记录(windows)
- XGBoost算法调参技巧!!
- yolox 训练自己的数据集 (COCO格式)
- 边缘计算系列-YOLOV5在海思HI3516DV300部署
- 计算的局限性:一位计算机科学家解释了为什么即使在人工智能时代,有些问题也太难了
- 研究完llama.cpp,我发现手机跑大模型竟这么简单
- 估算图像间的投影关系
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
miko

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
