

超快速生成式视觉智能模型,只需 2 秒即可创建图像

ETRI的研究人员推出了一项技术,该技术结合了生成式AI和视觉智能,可在短短2秒内从文本输入中创建图像,从而推动了超快速生成式视觉智能领域的发展。
电子通信研究院(ETRI)表示,将向公众推出5种型号。其中包括三个“KOALA”模型,它从文本输入中生成图像的速度比现有方法快五倍,以及两个会话视觉语言模型“Ko-LLaVA”,它可以用图像或视频进行问答。
“KOALA”模型使用知识蒸馏技术将公共软件模型的参数从25.6 b(25.6亿)显著减少到700M(7亿)。大量的参数通常意味着更多的计算,从而导致更长的处理时间和更高的操作成本。研究人员将模型尺寸缩小了三分之一,并将高分辨率图像的生成速度提高到以前的两倍,比DALL-E 3快五倍。
ETRI已经设法大大减小了模型的尺寸(1.7B(大),1B(小),700M(小)),并将生成速度提高到2秒左右,使其能够在只有8GB内存的低成本gpu上运行,在国内外竞争激烈的文本到图像生成环境中。
ETRI内部开发的三种“KOALA”模型已经在HuggingFace环境中发布。
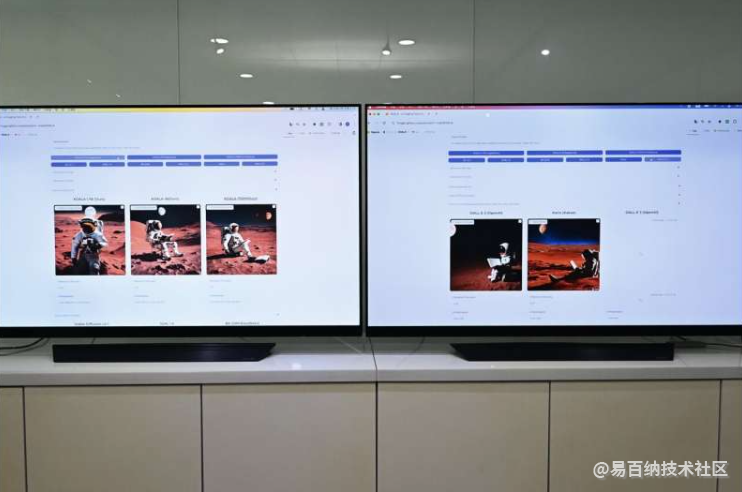
在实际操作中,etri开发的“KOALA 700M”模型在输入“宇航员在火星的月亮下看书的照片”这句话时,只需要1.6秒就能生成照片,比Kakao Brain的“Kallo”(3.8秒)、OpenAI的“DALL-E 2”(12.3秒)、“DALL-E 3”(13.7秒)快得多。
ETRI还推出了一个网站,用户可以直接比较和体验共9种模型,包括两种公开的稳定扩散模型,BK-SDM, Karlo, DALL-E 2, DALL-E 3和三种KOALA模型。
此外,研究小组还公布了会话视觉语言模型“Ko-LLaVA”,该模型为ChatGPT等会话人工智能添加了视觉智能。该模型可以检索图像或视频,并对其进行韩语问答。
“LLaVA”模型是在与 Wisconsin-Madison和ETRI的国际联合研究项目中开发的,并在著名的人工智能会议NeurIPS'23上发表,并利用开源的LLaVA(大型语言和视觉助理),具有GPT-4级别的图像解释能力。
研究小组正在进行扩展研究,以提高韩语理解能力,并引入以影像等多模态模型为基础的前所未有的视频解释能力。
此外,ETRI还预先发布了自己的基于韩语的紧凑语言理解生成模型(KEByT5)。已发布的型号(330M(小型),580M(基础),1.23B(大型))采用无标记技术,能够处理新词和未经训练的单词。训练速度提高2.7倍以上,推理速度提高1.4倍以上。
研究团队预计,生成式人工智能市场将从以文本为中心的生成模型逐渐转变为多模态生成模型,在模型大小的竞争格局中,新兴趋势是更小、更高效的模型。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3918次2020-01-10 09:30:20
-
浏览量:1130次2023-03-02 15:29:16
-
浏览量:2137次2023-03-09 15:39:13
-
浏览量:1595次2023-09-28 09:47:44
-
浏览量:1272次2023-09-07 10:24:09
-
浏览量:1603次2022-12-06 14:45:10
-
浏览量:1598次2019-09-12 14:00:08
-
浏览量:1196次2023-08-03 11:56:03
-
浏览量:1157次2023-02-15 22:48:47
-
浏览量:2001次2018-02-04 16:27:54
-
浏览量:2604次2022-03-20 09:01:16
-
2021-07-30 17:20:54
-
浏览量:1204次2023-07-08 11:04:21
-
浏览量:1626次2025-04-29 17:50:52
-
浏览量:3381次2020-10-20 15:40:55
-
浏览量:189次2023-07-30 17:57:28
-
2023-01-12 14:55:31
-
2022-12-26 10:26:11
-
浏览量:4592次2020-12-18 15:22:15


-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
V

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
