

项目实战|文档扫描|OCR识别

文章目录
1.引言
今天我们来看一个OCR相关的文档扫描项目。首先我们先来介绍一些相关理论
1.1 什么是光学字符识别 (OCR)
OCR(即光学字符识别)是识别图像中的文本并将其转换为电子形式的过程。这些图像可以是手写文本、打印文本(如文档、收据、名片等),甚至是自然场景照片。
简单来说,OCR 有两个部分。第一部分是文本检测,确定图像内的文本部分。第二部分文本识别,从图像中提取文本。 结合使用这些技术可以从任何图像中提取文本。具体的流程如下图所示
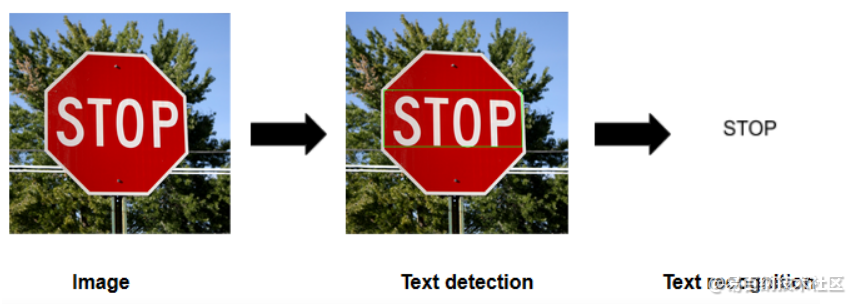
OCR 在各个行业都有广泛的应用(主要目的是减少人工操作)。它已经融入我们的日常生活,并且有很多的应用。
1.2 应用领域
OCR 越来越多地被各行业用于数字化,以减少人工工作量。这使得从商业文档、收据、发 票、护照等中提取和存储信息变得非常容易和高效,几十年前,OCR 系统的构建非常昂贵且繁琐。但计算机视觉和深度学习领域的进步使得我们现在自己就可以构建一个OCR 系统。但构建 OCR 系统需要利用到我们之前介绍的一系列方法。
2.项目背景介绍
背景:我们有一张随手拍的发 票照片如下,我们希望识别出文档信息并扫描
思考:我们如何实现上述需求呢?
首先,我们的算法应该能够正确的对齐文档,检测图像的边界,获得目标文本图像
其次,我们能对目标文本图像的文档进行扫描
下面我们来看一下具体如何在Opencv中处理
这里一共需要四大步
第一步,边缘检测,
第二步,提取轮廓。
第三步,透视变换,使得图像对齐,从上图可以看出,我们的图片是一个倾斜的,我们需要通过各种转换方法将其放平。
第四步,OCR识别
3.边缘检测
3.1 原始图像读取
首先,我们读取要扫描的图像。
下述代码我们计算了一个ratio比例,这是因为我们后续要对图像进行resize操作,里面每一个点的坐标也会有相同的一个变化,因此,我们先算出来这样一个比例,可以推导出resize完之后图像的坐标变化,然后方便我们后续在原图上进行修改。
# 读取输入
image = cv2.imread('images/receipt.jpg')
#坐标也会相同变化
ratio = image.shape[0] / 500.0 #这里我们首先得到一个比例,方便后续操作
orig = image.copy()
- 1
- 2
- 3
- 4
- 5
3.2 预处理
下面我们对图形进行一些基本的预处理工作,包含resize、灰度处理、二值处理。
第一,我们定义了一个resize()函数,它的基本逻辑是根据输入的高度或宽度,自动的计算出宽度或高度。
第二,我们将图形进行灰度处理
第三,我们使用gaussian滤波器去除噪音点
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
image = resize(orig, height = 500) #
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度处理
gray = cv2.GaussianBlur(gray, (5, 5), 0) # 高斯滤波器
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.3 结果展示
经过上述得到预处理后的图片,经过canny边缘检测。
# 展示预处理结果
edged = cv2.Canny(gray, 75, 200) # canny边缘检测,得到边缘
print("STEP 1: 边缘检测")
cv2.imshow("Image", image) #原始图像
cv2.imshow("Edged", edged) #边缘结果
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8


现在我们得到边缘检测的结果,可以看到有很多个边缘,我们做文档扫描,需要的是最外面的结果,接下来我们来具体如何实现。
3.轮廓检测
我们先来思考一下最外面这个轮廓它有什么特点。
首先,它是最大的,因此,我们可以根据它的面积或者周长进行排序,这里我们对面积进行排序。然后我们要去找轮廓,这里我们遍历每一个轮廓,然后去计算轮廓的一个近似,因为直接算轮廓的时候不太好算,往往是一个不规则形状,我们做一个矩形近似,然后此时就只需要确定四个点就行。具体代码如下:
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[1]
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:5] #按照面积排序
# 遍历轮廓
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True)
# C表示输入的点集
# epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
# True表示封闭的
approx = cv2.approxPolyDP(c, 0.02 * peri, True) #轮廓近似
# 4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break
# 展示结果
print("STEP 2: 获取轮廓")
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv2.imshow("Outline", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

4.透视变换
透视变换(Perspective Transformation),也称为投影变换,它可以用于纠正图像畸变、实现视角变换和图像合成等应用。借助透视变换,我们可以从不同视角获得准确的图像数据,并进行更精确的分析、处理和识别。
它的基本原理是基于相机的投影模型,通过处理图像中的四个控制点,将原始图像上的任意四边形区域映射到新的位置和形状上,我们需要得到四个输入坐标和四个输出坐标。通常情况下,透视变换会改变图像中的视角、缩放和旋转等属性。它有几个关键步骤如下:
控制点选择:为了进行透视变换,我们需要选择原始图像中的四个控制点(例如四个角点),以定义目标区域的形状和位置。这些控制点应该在原始图像和目标图像之间有明确的对应关系,然后通过高度和宽度信息,我们计算出目标图像的四个控制点
透视变换矩阵:通过使用控制点的坐标,可以计算出透视变换矩阵,透视变换矩阵是一个3x3的矩阵。它包含了图像变换所需的所有信息。这里需要输入坐标和输出坐标,然后利用cv2.getPerspectiveTransform函数获取变换矩阵。通过将透视变换矩阵应用于原始图像上的点,可以得到它们在目标图像中的对应位置。
接下来我们来看一下具体是如何实现的,首先我们定义了一个ordr_points()函数来获取坐标点,然后我们定义four_point_transform函数来实现透视变换。具体代码如下:
# 获取坐标点
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst) #通过输入和输出坐标,可以计算出M矩阵
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
定义好上述函数之后,接下来看一下经过同时变换之后的结果,为了方便展示,我们再进行二值化处理
# 透视变换
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio) #这里乘ratio是为了恢复我们原始图像坐标
# 二值处理
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', ref)
# 展示结果
print("STEP 3: 变换")
cv2.imshow("Scanned", resize(ref, height = 650))
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

可以看到我们现在就得到了扫描之后得到的结果,并且我们保存为scan.jpg操作
5.OCR识别
得到扫描后的文档之后,我们需要对其中的字符进行识别,这里我们要用到tesseract工具包,我们先来看一下如何安装相关环境。
5.1 tesseract安装
安装地址:https://digi.bib.uni-mannheim.de/tesseract/
首先选择一个合适的版本进行安装就行,我这里选择最新的w64版本,如何安装时一直点击下一步就行,但是我们要记住安装的路径。
注意:我们需要进行环境变量配置
把刚刚安装的路径添加到环境变量中即可
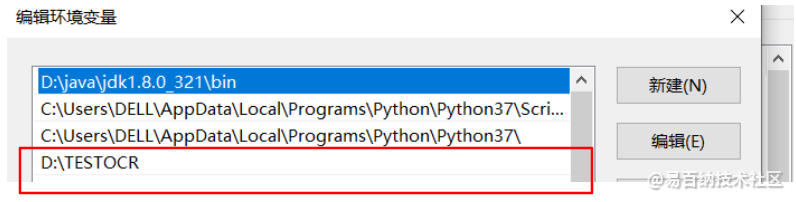
接下来我们希望在python中使用它,因此要下载对应的python工具包。
安装命令如下:pip install pytesseract
5.2 字符识别
我们刚刚已经得到了扫描后的图像,并保存为scan.jpg如下所示

接下来我们希望把其中的文本字符全部提取出来,我们来看一下具体代码吧
from PIL import Image
import pytesseract
import cv2
import os
# 读取图片
image = cv2.imread('scan.jpg')
# 灰度处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值处理
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
# OCR识别,提取字符
text = pytesseract.image_to_string(Image.open(filename))
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
x * KK KK K KR KH KR RK KK
WHOLE
FOODS
TM AR K CE T)
WHOLE FOODS MARKET ~ WESTPORT, CT 06880
399 POST RD WEST - (203) 227-6858
365 BACUN LS NP 499
$65 BACON LS NP 4.99
365 BACON LS NP 4.99
365 BACON LS NP 4.99
BROTH CHTC NP 2.19
FLOUR ALMUND NP 11.99
CHKN BRST BNLSS SK NP 18.80
HEAVY CREAM NP 3.39
BALSMC REDUCT NP 6.49
BEEF GRND 85/15 NP 5.04
JUICE COF CASHEW L NP = 8.99
DOCS PINT ORGANIC NF 14.49
HNY ALMOND BUTTER NP 9.99
xeee TAX = 00 9 BAL 101.33
TTA AATDA ABH HH oy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
对比一下可以看到识别的字符都比较准确。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1213次2022-12-09 16:00:38
-
浏览量:11629次2020-12-16 17:38:28
-
浏览量:4176次2020-09-26 22:23:39
-
浏览量:1875次2023-05-18 22:55:16
-
浏览量:2211次2017-11-17 14:46:14
-
浏览量:1965次2023-11-14 13:55:50
-
浏览量:758次2023-06-21 14:07:39
-
浏览量:3632次2018-01-05 15:19:01
-
浏览量:104次2023-08-30 20:18:28
-
浏览量:171次2023-08-15 23:15:48
-
浏览量:192次2023-08-16 17:42:24
-
浏览量:1521次2022-01-14 09:00:12
-
浏览量:126次2023-09-14 22:04:44
-
浏览量:216次2023-08-03 15:58:40
-
浏览量:2654次2021-12-03 17:42:05
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:157次2023-08-30 15:28:02
-
浏览量:775次2023-06-08 10:35:09
-
浏览量:1520次2023-12-18 17:48:09








-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

blakmi

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
