

目标检测算法——YOLOV8——算法详解

文章目录
一、主要贡献
主要的创新点:其实到了YOLOV5 基本创新点就不太多了,主要就是大家互相排列组合复用不同的网络模块、损失函数和样本匹配策略。
Yolo v8 主要涉及到:backbone 使用C2f模块,检测头使用了anchor-free + Decoupled-head,损失函数使用了分类BCE、回归CIOU + VFL(新增项目)的组合,框匹配策略由静态匹配改为了Task-Aligned Assigner匹配方式、最后 10 个 epoch 关闭 Mosaic 的操作、训练总 epoch 数从 300 提升到了 500。
二、主要思路
整理的算法框架图和流程如下,摘自OpenMMLab。算法版本20230118。
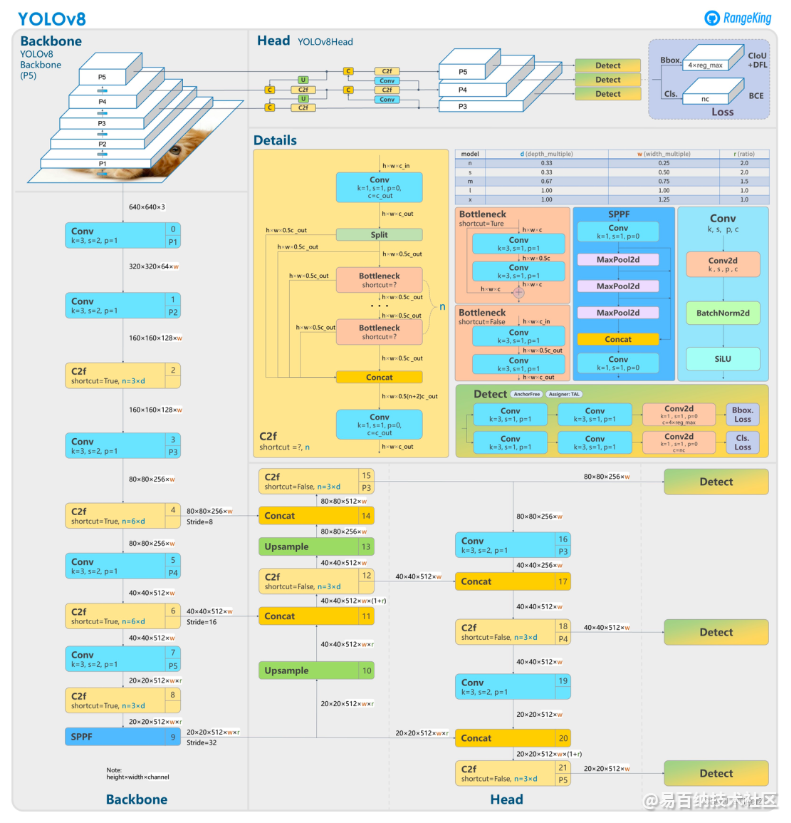
三、具体细节
1、input
输入要求以及预处理
基础输入仍然为640*640。
推理的预处理就是熟悉的letterbox(根据参数配置可以为不同的缩放填充模式,主要用于resize到640)+ 转换rgb、chw、int8(0-255)->float(0-1),注意没有归一化操作。
训练的预处理可选项比较多,可以参考这个配置文件:ultralytics/default.yaml at main · ultralytics/ultralytics · GitHub,需要注意的是作者实现的mosaic和网上看到的不同,对比如下图(左边网上版本,右边是YOLO的实现)。并且在YOLOV8 中,作者添加了可选项目,就是在最后10轮关闭mosaic增强。具体原因个人的经验如我的这篇文章:yolov5 mosaic相关
2、backbone
主干网络以及改进
这里不去特意强调对比YOLOv5等等的改进,因为各个系列都在疯狂演进,个人认为没必要花费时间看差异,着重看看一些比较重要的模块即可。
1)连续使用两个3*3卷积直接降低了4倍分辨率。
这个还是比较猛的,敢在如此小的感受野下连续两次仅仅用一层卷积就下采样。当然作为代价它的特征图还是比较厚的分别为64、128。
2)c2f 模块
这个其实也就是仿照YOLOv7 的ELAN 结构,通过更多的分支夸层链接,丰富了模型的梯度流。注意这里作者的结构没有问题,确实split 一共等价出了3个分支,只能归根于源代码为什么这么写:相当于前一半+后一半(等价全部)的原始特征图都跳层链接到了最后的concat,然后后一半的特征图又经过了后面一系列的操作。C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了。需要针对自己的硬件进行测试看对最终推理速度的影响。源代码如下:
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
3)sppf 模块
对比spp,将简单的并行max pooling 改为串行+并行的方式。对比如下(左边是SPP,右边是SPPF):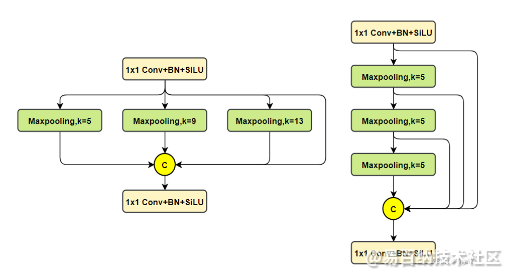
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
3、neck & head
检测头以及匹配机制
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。这个对于不了解anchor free 和 YOLOV6 这种的确实还是比较困惑的。这里展开叙述一下:

如上面图,左边是YOLOV5 的结构,右面是YOLOv8 的结构。
Yolov5: 检测和分类共用一个卷积(coupled head)并且是anchor based ,其 卷积输出为(5+N class)*3,其中 5为bbox 四个值(具体代表什么不同版本略有不同,官方git有说明,历史版本见 目标检测算法——YOLOV5 )+ 一个obj 值 (是否有目标,这个是从YOLO V1 传承下来的,个人感觉有点绕),N class 为类别数,3为anchor 的数量,默认是3个。
YOLOv8:检测和分类的卷积是解耦的(decoupled),如右图,上面一条支路是框的卷积,框的特征图channel为4*regmax,关于这个regmax 后面我们详细的解释,并不是anchor;分类的channel 为类别数。
因此主要的变化可以认为有三个:1)coupled head -> decoupled head ;2)obj 分支消失;3)anchor based——> anchor free
1)coupled head -> decoupled head
这个解耦操作,看YOLO x 的论文,约有1% 的提升。逻辑和实现都比较直观易懂,不再赘述。
2)obj 分支消失;
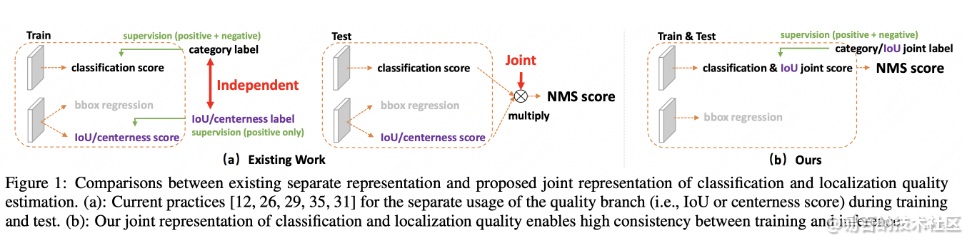
这个其实我自己再看YOLO V1 的时候就有疑问,它存在的意义。后来人们发现,其实obj 的在训练和推理过程中存在逻辑不一致性。具体而言(摘自“大白话 Generalized Focal Loss - 知乎”)
A。用法不一致。训练的时候,分类和质量估计各自训记几个儿的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap。(个人认为还好,就是两个监督信号)
B。对象不一致。借助Focal Loss的力量,分类分支能够使得少量的正样本和大量的负样本一起成功训练,但是质量估计通常就只针对正样本训练。那么,对于one-stage的检测器而言,在做NMS score排序的时候,所有的样本都会将分类score和质量预测score相乘用于排序,那么必然会存在一部分分数较低的“负样本”的质量预测是没有在训练过程中有监督信号的,对于大量可能的负样本,他们的质量预测是一个未定义行为。这就很有可能引发这么一个情况:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面。问题一如图所示:
3)anchor based——> anchor free
这里主要涉及怎么定义回归内容以及如何匹配GT框的问题。
A。回归的内容当前版本就是回归的ltrb四个值(这四个值是距离匹配到的anchor 点的距离值!不是图片的绝对位置)。后面推理阶段通过 dist2bbox函数转换为需要的格式:
https://github.com/ultralytics/ultralytics/blob/cc3c774bde86ffce694d202b7383da6cc1721c1b/ultralytics/nn/modules.py#L378
https://github.com/ultralytics/ultralytics/blob/cc3c774bde86ffce694d202b7383da6cc1721c1b/ultralytics/yolo/utils/tal.py#L196。
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
"""Transform distance(ltrb) to box(xywh or xyxy)."""
lt, rb = torch.split(distance, 2, dim)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
if xywh:
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
return torch.cat((c_xy, wh), dim) # xywh bbox
return torch.cat((x1y1, x2y2), dim) # xyxy bbox
B。匹配策略
YOLOv5 采用静态的匹配策略,V8采用了动态的TaskAlignedAssigner,其余常见的动态匹配还有: YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner。
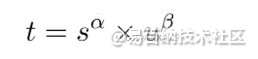
TaskAligned使用分类得分和IoU的高阶组合来衡量Task-Alignment的程度。使用上面公式来对每个实例计算Anchor-level 的对齐程度:s 和 u 分别为分类得分和 IoU 值,α 和 β 为权重超参。t 可以同时控制分类得分和IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。采用一种简单的分配规则选择训练样本:对每个实例,选择m个具有最大t值的Anchor作为正样本,选择其余的Anchor作为负样本。然后,通过损失函数(针对分类与定位的对齐而设计的损失函数)进行训练。
默认参数如下(当前版本这些超参没有提供修改的接口,如需修改需要在源码上进行修改):
4、loss function
损失函数设计
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
分类分支依然采用 BCE Loss。回归分支使用了 Distribution Focal Loss(DFL Reg_max默认为16)+ CIoU Loss。3 个 Loss 采用一定权重比例加权即可(默认如下:https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/configs/default.yaml#L83)。

这里重点介绍一下DFL损失。目前被广泛使用的bbox表示可以看作是对bbox方框坐标建模了单一的狄拉克分布。但是在复杂场景中,一些检测对象的边界并非十分明确。如下图左面所示,对于滑板左侧被水花模糊,引起对左边界的预测分布是任意而扁平的,对右边界的预测分布是明确而尖锐的。对于这个问题,有学者提出直接回归一个任意分布来建模边界框,使用softmax实现离散的回归,将狄拉克分布的积分形式推导到一般形式的积分形式来表示边界框。
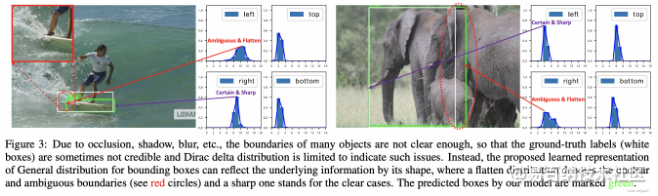
狄拉克分布可以认为在一个点概率密度为无穷大,其他点概率密度为0,这是一种极端地认为离散的标签时绝对正确的。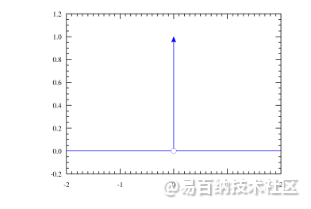
因为标签是一个离散的点,如果把标签认为是绝对正确的目标,那么学习出的就是狄拉克分布,概率密度是一条尖锐的竖线。然而真实场景,物体边界并非是十分明确的,因此学习一个宽范围的分布更为合理。我们需要获得的分布虽然不再像狄拉克分布那么极端(只存在标签值),但也应该在标签值附近。因此学者提出Distribution Focal Loss损失函数,目的让网络快速聚焦到标签附近的数值,是标签处的概率密度尽量大。思想是使用交叉熵函数,来优化标签y附近左右两个位置的概率,是网络分布聚焦到标签值附近。如下公式。Si 是网络的sigmod 输出,yi 和 yi+1 是上图的区间顺序,y是label 值。
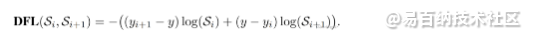
具体而言,针对我们将DFL的超参数Reg_max 设置为16的情况下:
A。训练阶段:我们以回归left为例:目标的label 转换为ltrb后,y = ( left - 匹配到的anchor 中心点 x 坐标)/ 当前的下采样倍数,假设求得3.2。那么i 就应该为3,yi = 3 ,yi+1 = 4。
B。推理阶段:因为没有label,直接将16个格子进行积分(离散变量为求和,也就是期望)结果就是最终的坐标偏移量(再乘以下采样倍数+ 匹配到的anchor的对应坐标)

DFL的实现方式其实就是一个卷积:https://github.com/ultralytics/ultralytics/blob/cc3c774bde86ffce694d202b7383da6cc1721c1b/ultralytics/nn/modules.py#L67
class DFL(nn.Module):
# Integral module of Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
NOTE:作者代码中的超参数Reg_max是写死的——16,如果要修改需要修改源码,如果你的输入是640,最大下采样到2020,那么16是够用的,如果输入没有resize或者超过了640一定要自己设置这个Reg_max参数,否则如果目标尺寸还大,将无法拟合到这个偏移量。 比如12801280的图片,目标1280*960,最大下采样32倍,1280/32/2=20 > 16(除以2是因为是一半的偏移量),超过了dfl 滑板右侧那个图的范围。至于为什么叫focal loss的变体,有兴趣看一下这个深入理解一下Generalized Focal Loss v1 & v2 - 知乎和大白话 Generalized Focal Loss - 知乎就可以,这里不再赘述是因为,如果先看这些,很容易犯晕,反而抓不住DFL 我认为的重点(离散的分布形式)
5、trics
单独训练trick或者重点重复概述上述所有trick
C2f模块、Decoupled-Head、Anchor-Free、BCE Loss作为分类损失 VFL Loss + CIOU Loss作为回归损失、Task-Aligned Assigner匹配方式、最后 10 个 epoch 关闭 Mosaic 的操作。
6、inference
测试阶段(非训练阶段)过程
可以参考:YOLOv8 深度详解!一文看懂,快速上手 - 掘金 主要就是多了DFL的积分/求和/解码(其实上面解释过就是一个卷积操作)过程。
四、结果
算法结果
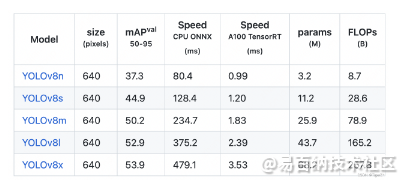
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5656次2024-05-22 15:23:49
-
浏览量:1945次2023-09-08 15:20:45
-
浏览量:4116次2023-12-16 11:15:45
-
浏览量:1042次2023-12-18 18:07:01
-
浏览量:4455次2024-02-02 18:15:06
-
浏览量:5991次2021-08-09 16:11:19
-
浏览量:1144次2023-12-14 17:05:19
-
浏览量:1546次2024-02-18 14:24:39
-
浏览量:1614次2023-12-15 17:15:27
-
浏览量:1313次2023-12-11 16:56:37
-
2023-09-07 13:53:43
-
2024-12-10 11:13:53
-
浏览量:4862次2024-03-05 15:05:36
-
浏览量:2889次2024-03-06 16:15:59
-
2024-12-10 10:34:18
-
浏览量:3513次2023-12-19 17:25:07
-
浏览量:1410次2023-02-02 13:12:40
-
浏览量:2307次2023-12-14 17:15:07
-
浏览量:3814次2024-11-13 14:14:36






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

小菜很菜

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
