

基于YOLOv8的自定义数据姿势估计

在不断发展的计算机视觉领域中,姿势估计凭借其重要的创新而脱颖而出,彻底改变了我们理解和与视觉数据交互的方式。Ultralytics YOLOv8 处于这一转变的前沿,提供了一种强大的工具,捕捉图像中物体方向和运动的微妙之处。
传统上,在图像中跟踪物体的关键点一直是复杂的,但使用 YOLOv8,这变得简便而直观。这种进步不仅令人振奋 —— 它在包括体育分析、医疗保健和零售等各个领域打开了无数可能性。
在本文中,我们将探讨使用YOLOv8进行姿势估计的过程。以下是我们将涵盖的内容:
- 使用CVAT进行姿势估计的数据注释:我们将从将数据集上传到CVAT平台开始,配置工具,注释关键点并导出数据。
- 将注释转换为Ultralytics YOLOv8兼容的格式:在注释之后,我们将将数据转换为与YOLOv8兼容的格式,确保我们的模型能够正确解释它。
- 数据分割:对数据进行结构化是至关重要的,因此我们将其分成训练、验证和测试集,以便进行有效的模型训练。
- 训练用于姿势估计的YOLOv8模型:有了组织好的数据,我们将训练YOLOv8模型以识别和估计姿势。
- 使用YOLOv8执行推断:最后,我们将使用训练好的模型对新数据进行姿势估计,看到我们努力的成果。您还可以在YouTube上查看我们关于使用Ultralytics YOLOv8进行姿势估计的视频。
使用CVAT进行姿势估计的数据注释
数据注释的过程在计算机视觉领域至关重要。在本教程中,我们将使用虎类数据集演示如何准确注释关键点,这是为了训练我们的姿势估计模型而不可或缺的步骤。
注意:可以从Ultralytics虎类姿势数据集获取的虎类数据集应当被下载并解压,为即将进行的任务做好准备。这些图像将成为我们训练过程的基础,因此确保它们被方便地存储。
如果您是CVAT的新手,花时间熟悉其功能是值得的,可以通过查阅CVAT文档来了解。这将为更加流畅的注释过程奠定基础。
上传数据集
在下载虎类图像后,请确保解压文件。接下来,将所有图像作为一个新任务上传到CVAT平台,并点击“提交并打开”。
完成后,您将被引导至下方显示的页面。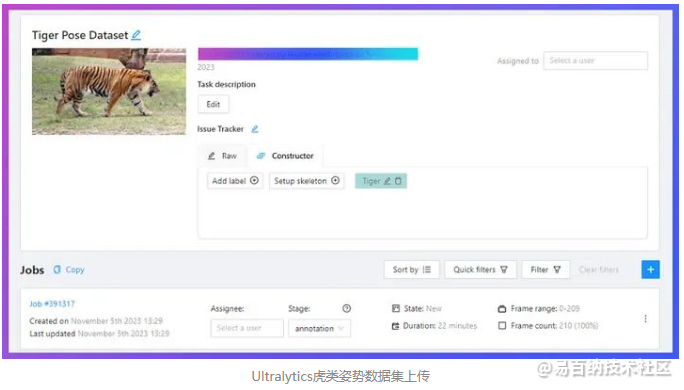
设置注释工具CVAT
在CVAT中打开任务后,您将被提示选择一个特定的作业,这将成为您进行注释的工作区。作业编号,例如这里提到的“作业 #391317”,对每个用户都会有所不同。这将引导您进入注释界面,设置将完成,您可以开始为数据打标签。
数据注释
在CVAT中,您可以选择使用不同的格式进行注释。对于虎类数据集,我们将利用点注释来标记关键点。该过程在教程中提供的详细GIF中进行了可视化,引导您完成注释的每一步。
数据导出
完成注释后,可以使用“CVAT for images 1:1”格式导出数据集,这将适用于后续工作流程中转换为YOLOv8格式。
将注释转换为Ultralytics YOLOv8格式
一旦从CVAT导出了注释,您将收到一个zip文件。解压缩该文件,显示出一个“annotations.xml”文件,其中包含了您分配的关键点和标签。这个文件非常关键,因为它包含了YOLOv8将学习的结构化数据。
要与YOLOv8集成,将“annotations.xml”文件放入与图像数据集相同的目录中。如果需要重新下载数据集,可以在Ultralytics虎类姿势数据集中找到。确保在下载后解压缩文件,为下一步做好准备。
现在,创建一个名为“cvat_to_ultralytics_yolov8.py”的Python脚本。将提供的代码复制到这个新文件中。运行此脚本将把您的注释转换为YOLOv8格式,为训练模型铺平道路。
import ast
import os.path
from xml.dom import minidom
out_dir = './out'
if not os.path.exists(out_dir):
os.makedirs(out_dir)
file = minidom.parse('annotations.xml')
images = file.getElementsByTagName('image')
for image in images:
width = int(image.getAttribute('width'))
height = int(image.getAttribute('height'))
name = image.getAttribute('name')
elem = image.getElementsByTagName('points')
bbox = image.getElementsByTagName('box')[0]
xtl = int(float(bbox.getAttribute('xtl')))
ytl = int(float(bbox.getAttribute('ytl')))
xbr = int(float(bbox.getAttribute('xbr')))
ybr = int(float(bbox.getAttribute('ybr')))
w = xbr - xtl
h = ybr - ytl
label_file = open(os.path.join(out_dir, name + '.txt'), 'w')
for e in elem:
label_file.write('0 {} {} {} {} '.format(
str((xtl + (w / 2)) / width),
str((ytl + (h / 2)) / height),
str(w / width),
str(h / height)))
points = e.attributes['points']
points = points.value.split(';')
points_ = []
for p in points:
p = p.split(',')
p1, p2 = p
points_.append([int(float(p1)), int(float(p2))])
for p_, p in enumerate(points_):
label_file.write('{} {}'.format(p[0] / width, p[1] / height))
if p_ < len(points_) - 1:
label_file.write(' ')
else:
label_file.write('\n')
运行脚本后,删除“annotations.xml”以避免在后续步骤中可能的混淆。
数据分割(训练、验证、测试)
在对数据集进行注释和转换后,下一步是将图像和注释组织成用于训练和评估的不同集合。
- 在项目中创建两个目录:一个命名为“images”,另一个命名为“labels”。
- 分别将图像及其相应的注释文件分发到这些文件夹中。
- 为了便于这个数据分割过程,创建一个名为“splitdata.py”的Python文件。
- 将提供的代码复制并粘贴到“splitdata.py”文件中。
- 通过运行该文件执行Python脚本。
- 此过程确保您的数据被适当地分成训练和测试子集,为Ultralytics YOLOv8的训练做好准备。
import splitfolders
input_fol_path = "path to folder, that includes images and labels folder"
splitfolders.ratio(input_fold_path, output="output",
seed=1337, ratio=(.8, .2, .0), group_prefix=None, move=False)
结果将是一个包含两个不同目录的输出文件夹:“train”和“test”。这些文件夹已准备好在您的YOLOv8训练过程中使用。
训练YOLOv8模型进行姿势估计
接下来的步骤涉及创建一个“data.yaml”文件,它充当YOLOv8的路线图,指导其对数据集进行训练并定义训练的类别。将必要的代码插入到 ‘data.yaml’ 中,自定义路径以指向您的数据集目录。
有关配置虎类姿势数据集的详细指导,请参阅Ultralytics文档:https://docs.ultralytics.com/datasets/pose/tiger-pose/#dataset-yaml
请记住根据需要调整数据集目录路径。配置好 ‘data.yaml’ 后,您就可以开始训练模型了。
path: "path to the dataset directory"
train: train
val: val
kpt_shape: [12, 2]
flip_idx: [0,1,2,3,4,5,6,7,8,9,10,11]
names:
0: tiger
完成后,您已经准备好开始了!您可以使用提供的命令开始训练YOLOv8模型进行虎类姿势估计。
yolo task=pose mode=train data="path/data.yaml" model=yolov8n.pt imgsz=640
训练持续时间会有所不同,取决于您的GPU设备。
使用YOLOv8进行推断
在训练完成后,通过在新数据上执行推断来测试您的模型。运行提供的命令,将您的姿势估计模型应用于检测和分析姿势。
# Run inference using a tiger-pose trained model
yolo task=pose mode=predict \
source="https://www.youtube.com/watch?v=MIBAT6BGE6U" \
show=True model="path/to/best.pt"
推断结果将显示出模型将其学到的应用于现实场景的能力。请参阅下文:
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3334次2024-02-28 16:15:25
-
浏览量:6135次2024-02-28 15:36:09
-
浏览量:3513次2023-12-19 17:25:07
-
浏览量:2307次2023-12-14 17:15:07
-
浏览量:2500次2020-08-03 12:02:37
-
浏览量:4230次2020-09-20 21:19:24
-
浏览量:15741次2020-11-12 21:55:56
-
浏览量:1685次2023-09-07 09:50:10
-
浏览量:2200次2020-08-03 12:01:28
-
浏览量:6689次2020-09-23 23:07:37
-
浏览量:3788次2023-11-25 17:47:33
-
浏览量:8813次2020-12-12 17:47:04
-
浏览量:8585次2020-12-12 17:55:00
-
浏览量:5171次2021-06-28 15:59:34
-
浏览量:36145次2021-03-03 17:25:19
-
浏览量:3409次2020-05-06 15:52:54
-
浏览量:4857次2021-09-13 13:47:51
-
浏览量:2542次2020-08-14 18:33:44
-
浏览量:5185次2021-09-08 16:03:36





-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

么得钱钱

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
