

YOLO-NAS:最高效的目标检测算法之一

介绍
YOLO(You Only Look Once)是一种目标检测算法,它使用深度神经网络模型,特别是卷积神经网络,来实时检测和分类对象。该算法首次在2016年的论文《You Only Look Once:统一的实时目标检测》被提出。自发布以来,由于其高准确性和速度,YOLO已成为目标检测和分类任务中最受欢迎的算法之一。它在各种目标检测基准测试中实现了最先进的性能。

就在2023年5月的第一周,YOLO-NAS模型被引入到机器学习领域,它拥有无与伦比的精度和速度,超越了其他模型如YOLOv7和YOLOv8。
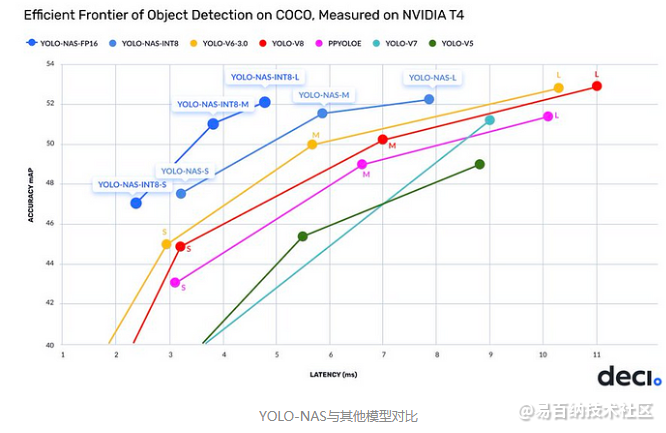
YOLO-NAS模型是在COCO和Objects365等数据集上进行预训练的,这使得它适用于现实世界的应用。它目前可以在Deci的SuperGradients上使用,这是一个基于PyTorch的库,包含近40个预训练模型,用于执行不同的计算机视觉任务,如分类、检测、分割等。
那么,让我们开始安装SuperGradients库,以便开始使用YOLO-NAS吧!
# Installing supergradients lib
!pip install super-gradients==3.1.0
导入和加载YOLO-NAS
#importing models from supergradients' training module
from super_gradients.training import models
下一步是初始化模型。YOLO-NAS有不同的模型可供选择,对于本文,我们将使用 yolo_nas_l,其中pretrained_weights = 'coco'。
你可以在这个GitHub页面上获取有关不同模型的更多信息。
# Initializing model
yolo_nas = models.get("yolo_nas_l", pretrained_weights = "coco")
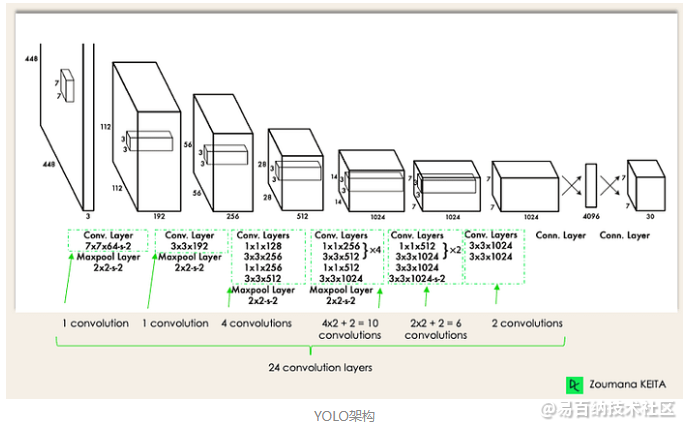
模型架构
在下面的代码单元格中,我们使用torchinfo的summary来获取YOLO-NAS的架构,这对于深入了解模型的运作方式非常有用。
# Yolo NAS architecture
!pip install torchinfo
from torchinfo import summary
summary(model = yolo_nas,
input_size = (16,3,640,640),
col_names = ['input_size',
'output_size',
'num_params',
'trainable'],
col_width = 20,
row_settings = ['var_names'])
=================================================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param # Trainable
=================================================================================================================================================
YoloNAS_L (YoloNAS_L) [16, 3, 640, 640] [16, 8400, 4] -- True
├─NStageBackbone (backbone) [16, 3, 640, 640] [16, 96, 160, 160] -- True
│ └─YoloNASStem (stem) [16, 3, 640, 640] [16, 48, 320, 320] -- True
│ │ └─QARepVGGBlock (conv) [16, 3, 640, 640] [16, 48, 320, 320] 3,024 True
│ └─YoloNASStage (stage1) [16, 48, 320, 320] [16, 96, 160, 160] -- True
│ │ └─QARepVGGBlock (downsample) [16, 48, 320, 320] [16, 96, 160, 160] 88,128 True
│ │ └─YoloNASCSPLayer (blocks) [16, 96, 160, 160] [16, 96, 160, 160] 758,594 True
│ └─YoloNASStage (stage2) [16, 96, 160, 160] [16, 192, 80, 80] -- True
│ │ └─QARepVGGBlock (downsample) [16, 96, 160, 160] [16, 192, 80, 80] 351,360 True
│ │ └─YoloNASCSPLayer (blocks) [16, 192, 80, 80] [16, 192, 80, 80] 2,045,315 True
│ └─YoloNASStage (stage3) [16, 192, 80, 80] [16, 384, 40, 40] -- True
│ │ └─QARepVGGBlock (downsample) [16, 192, 80, 80] [16, 384, 40, 40] 1,403,136 True
│ │ └─YoloNASCSPLayer (blocks) [16, 384, 40, 40] [16, 384, 40, 40] 13,353,733 True
│ └─YoloNASStage (stage4) [16, 384, 40, 40] [16, 768, 20, 20] -- True
│ │ └─QARepVGGBlock (downsample) [16, 384, 40, 40] [16, 768, 20, 20] 5,607,936 True
│ │ └─YoloNASCSPLayer (blocks) [16, 768, 20, 20] [16, 768, 20, 20] 22,298,114 True
│ └─SPP (context_module) [16, 768, 20, 20] [16, 768, 20, 20] -- True
│ │ └─Conv (cv1) [16, 768, 20, 20] [16, 384, 20, 20] 295,680 True
│ │ └─ModuleList (m) -- -- -- --
│ │ └─Conv (cv2) [16, 1536, 20, 20] [16, 768, 20, 20] 1,181,184 True
├─YoloNASPANNeckWithC2 (neck) [16, 96, 160, 160] [16, 96, 80, 80] -- True
│ └─YoloNASUpStage (neck1) [16, 768, 20, 20] [16, 192, 20, 20] -- True
│ │ └─Conv (reduce_skip1) [16, 384, 40, 40] [16, 192, 40, 40] 74,112 True
│ │ └─Conv (reduce_skip2) [16, 192, 80, 80] [16, 192, 80, 80] 37,248 True
│ │ └─Conv (downsample) [16, 192, 80, 80] [16, 192, 40, 40] 332,160 True
│ │ └─Conv (conv) [16, 768, 20, 20] [16, 192, 20, 20] 147,840 True
│ │ └─ConvTranspose2d (upsample) [16, 192, 20, 20] [16, 192, 40, 40] 147,648 True
│ │ └─Conv (reduce_after_concat) [16, 576, 40, 40] [16, 192, 40, 40] 110,976 True
│ │ └─YoloNASCSPLayer (blocks) [16, 192, 40, 40] [16, 192, 40, 40] 2,595,716 True
│ └─YoloNASUpStage (neck2) [16, 192, 40, 40] [16, 96, 40, 40] -- True
│ │ └─Conv (reduce_skip1) [16, 192, 80, 80] [16, 96, 80, 80] 18,624 True
│ │ └─Conv (reduce_skip2) [16, 96, 160, 160] [16, 96, 160, 160] 9,408 True
│ │ └─Conv (downsample) [16, 96, 160, 160] [16, 96, 80, 80] 83,136 True
│ │ └─Conv (conv) [16, 192, 40, 40] [16, 96, 40, 40] 18,624 True
│ │ └─ConvTranspose2d (upsample) [16, 96, 40, 40] [16, 96, 80, 80] 36,960 True
│ │ └─Conv (reduce_after_concat) [16, 288, 80, 80] [16, 96, 80, 80] 27,840 True
│ │ └─YoloNASCSPLayer (blocks) [16, 96, 80, 80] [16, 96, 80, 80] 2,546,372 True
│ └─YoloNASDownStage (neck3) [16, 96, 80, 80] [16, 192, 40, 40] -- True
│ │ └─Conv (conv) [16, 96, 80, 80] [16, 96, 40, 40] 83,136 True
│ │ └─YoloNASCSPLayer (blocks) [16, 192, 40, 40] [16, 192, 40, 40] 1,280,900 True
│ └─YoloNASDownStage (neck4) [16, 192, 40, 40] [16, 384, 20, 20] -- True
│ │ └─Conv (conv) [16, 192, 40, 40] [16, 192, 20, 20] 332,160 True
│ │ └─YoloNASCSPLayer (blocks) [16, 384, 20, 20] [16, 384, 20, 20] 5,117,700 True
├─NDFLHeads (heads) [16, 96, 80, 80] [16, 8400, 4] -- True
│ └─YoloNASDFLHead (head1) [16, 96, 80, 80] [16, 68, 80, 80] -- True
│ │ └─ConvBNReLU (stem) [16, 96, 80, 80] [16, 128, 80, 80] 12,544 True
│ │ └─Sequential (cls_convs) [16, 128, 80, 80] [16, 128, 80, 80] 147,712 True
│ │ └─Conv2d (cls_pred) [16, 128, 80, 80] [16, 80, 80, 80] 10,320 True
│ │ └─Sequential (reg_convs) [16, 128, 80, 80] [16, 128, 80, 80] 147,712 True
│ │ └─Conv2d (reg_pred) [16, 128, 80, 80] [16, 68, 80, 80] 8,772 True
│ └─YoloNASDFLHead (head2) [16, 192, 40, 40] [16, 68, 40, 40] -- True
│ │ └─ConvBNReLU (stem) [16, 192, 40, 40] [16, 256, 40, 40] 49,664 True
│ │ └─Sequential (cls_convs) [16, 256, 40, 40] [16, 256, 40, 40] 590,336 True
│ │ └─Conv2d (cls_pred) [16, 256, 40, 40] [16, 80, 40, 40] 20,560 True
│ │ └─Sequential (reg_convs) [16, 256, 40, 40] [16, 256, 40, 40] 590,336 True
│ │ └─Conv2d (reg_pred) [16, 256, 40, 40] [16, 68, 40, 40] 17,476 True
│ └─YoloNASDFLHead (head3) [16, 384, 20, 20] [16, 68, 20, 20] -- True
│ │ └─ConvBNReLU (stem) [16, 384, 20, 20] [16, 512, 20, 20] 197,632 True
│ │ └─Sequential (cls_convs) [16, 512, 20, 20] [16, 512, 20, 20] 2,360,320 True
│ │ └─Conv2d (cls_pred) [16, 512, 20, 20] [16, 80, 20, 20] 41,040 True
│ │ └─Sequential (reg_convs) [16, 512, 20, 20] [16, 512, 20, 20] 2,360,320 True
│ │ └─Conv2d (reg_pred) [16, 512, 20, 20] [16, 68, 20, 20] 34,884 True
=================================================================================================================================================
Total params: 66,976,392
Trainable params: 66,976,392
Non-trainable params: 0
Total mult-adds (T): 1.04
=================================================================================================================================================
Input size (MB): 78.64
Forward/backward pass size (MB): 27238.60
Params size (MB): 178.12
Estimated Total Size (MB): 27495.37
=================================================================================================================================================
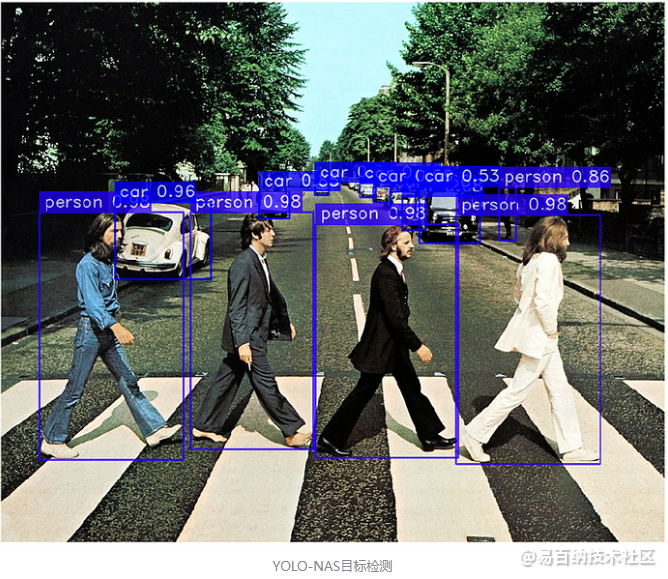
图像上的目标检测
现在我们可以测试模型在不同图像上检测对象的能力。
在下面的代码中,我们初始化了一个名为image的变量,该变量接收包含图像的URL。然后,我们可以使用predict和show方法来显示带有模型预测的图像。
image = "https://i.pinimg.com/736x/b4/29/48/b42948ef9202399f13d6e6b3b8330b20.jpg"
yolo_nas.predict(image).show()

在上面的图像中,我们可以看到为每个对象做出的检测以及模型对其自身预测的置信度分数。例如,我们可以看到模型对地板上的白色物体是一个杯子有97%的置信度。然而,这个图像中有许多对象,我们可以看到模型将任天堂64游戏主机误认为是一辆汽车。
我们可以通过使用conf参数来改善结果,该参数用作检测的阈值。例如,我们可以将此值更改为conf = 0.50,以便模型仅显示置信度高于50%的检测。让我们试一试。
image = "https://i.pinimg.com/736x/b4/29/48/b42948ef9202399f13d6e6b3b8330b20.jpg"
yolo_nas.predict(image, conf = 0.50).show()

现在,模型只显示在其检测中至少有50%置信度的对象,这些对象是杯子、电视和遥控器。
我们可以测试更多图像。

在视频上进行目标检测
我们还可以使用YOLO-NAS模型在视频上执行实时目标检测!
在下面的代码中,我使用IPython库中的YouTubeVideo模块选择并保存任何我喜欢的YouTube视频。
from IPython.display import YouTubeVideo # Importing YouTubeVideo from IPython's display module
video_id = "VtK2ZMlcCQU" # Selecting video ID
video = YouTubeVideo(video_id) # Loading video
display(video) # Displaying video
现在我们已经选择了一个视频,我们将使用youtube-dl库以.mp4格式下载视频。
完成后,我们将视频保存到input_video_path变量,该变量将作为我们的模型执行检测的输入。
# Downloading video
video_url = f'https://www.youtube.com/watch?v={video_id}'
!pip install -U "git+https://github.com/ytdl-org/youtube-dl.git"
!python -m youtube_dl -f 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/mp4' "$video_url"
print('Video downloaded')
# Selecting input and output paths
input_video_path = f"/kaggle/working/Golf Rehab 'Short Game' Commercial-VtK2ZMlcCQU.mp4"
output_video_path = "detections.mp4"
然后,我们导入PyTorch并启用GPU。
import torch
device = 'cuda' if torch.cuda.is_available() else "cpu"
然后,我们使用to()方法在GPU上运行YOLO-NAS模型,并使用predict()方法在input_video_path变量中存储的视频上执行预测。save()方法用于保存带有检测结果的视频,保存路径由output_video_path指定。
yolo_nas.to(device).predict(input_video_path).save(output_video_path) # Running predictions on video
Video downloaded
Predicting Video: 100%|██████████| 900/900 [33:15<00:00, 2.22s/it]
完成后,我们再次使用IPython来显示一个包含以.gif格式下载的视频的.gif文件,以便在此Kaggle笔记本中查看。
from IPython.display import Image
with open('/kaggle/input/detection-gif/detections.gif','rb') as f:
display(Image(data=f.read(), format='png'))
结论
我们使用新发布的YOLO-NAS模型执行了图像和视频上的初始目标检测任务。你可以使用自定义数据集来对该模型进行微调,以提高其在某些对象上的性能。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1279次2023-12-20 16:31:10
-
浏览量:8337次2024-02-02 17:13:35
-
浏览量:1946次2023-09-08 15:20:45
-
浏览量:1144次2023-12-14 17:05:19
-
浏览量:5993次2021-08-09 16:11:19
-
浏览量:9009次2020-12-16 13:01:00
-
浏览量:2524次2023-12-01 14:35:39
-
浏览量:1292次2023-05-13 21:35:31
-
浏览量:3021次2024-02-20 10:27:52
-
浏览量:1314次2023-12-11 16:56:37
-
浏览量:9524次2021-03-06 16:14:26
-
浏览量:2889次2024-03-06 16:15:59
-
浏览量:1427次2023-02-22 09:08:28
-
浏览量:11651次2021-04-27 00:28:09
-
2023-09-07 13:53:43
-
浏览量:5657次2024-05-22 15:23:49
-
浏览量:2455次2023-12-18 17:48:09
-
浏览量:1547次2024-02-18 14:24:39
-
浏览量:3454次2018-12-11 13:07:35




-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

搬砖中~

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
