

一步步实现人脸识别<2>

接下来要做的, 就是把分割好的数据清洗一下, 因为爬虫或者购买的数据集, 有时候会有些偏差, 这些脏数据如果进入到了后面的训练阶段, 会影响最终模型的精度, 说人话就是, 如果一个目录中出现了一个不属于这个标签的人, 例如:

陈佩斯这个目录中, 有一张鲁豫的照片, 这个数据就是脏数据.
解决办法就是需要将同一个目录中的所有人脸, 先提取特征点, 然后相互比较, 计算出每个图片, 相对其他所有图片欧氏距离的平均值, 距离高于阈值的, 会被当作脏数据移除目录.
说人话就是, 拿陈佩斯图片0, 跟鲁豫的照片, 以及陈佩斯图片1, 2, 3,…的特征点做欧氏距离算平均值:

即便有这个脏数据在中间, 拉高了一点点平均值, 但是总体还是偏低的水平
但是鲁豫跟其他陈佩斯的图片做对比的时候, 所有距离值都会偏大, 平均值也会较大, 超过某个阈值, 就会被当做脏数据了.
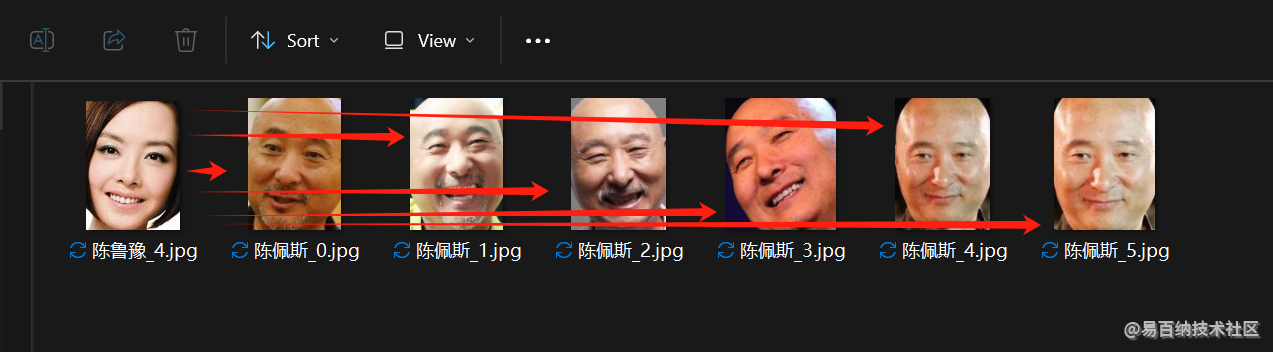
ok, 知道原理了, 开始具体操作, 这里使用shape_predictor_68_face_landmarks提取关键点, 使用dlib_face_recognition_resnet_model_v1来组织特征描述符
先用conda安装dlib
conda install -c conda-forge dlib
然后:
# 导入包
import cv2
import numpy as np
import matplotlib.pyplot as plt
import dlib
# %matplotlib inline
plt.rcParams['figure.dpi'] = 200
# 关键点 检测模型
shape_detector = dlib.shape_predictor('./weights/shape_predictor_68_face_landmarks.dat')
# resnet模型
face_descriptor_extractor = dlib.face_recognition_model_v1('./weights/dlib_face_recognition_resnet_model_v1.dat')
定义一个函数获取特征描述符:
# 提取单张图片的特征描述符
def getFaceFeat(fileName):
#读取
img=cv2.imdecode(np.fromfile(fileName,dtype=np.uint8),-1)
if img is None:
return None
# 转为RGB
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# 初始化
face_descriptor = None
# 整个裁剪图就是人脸,无需再检测
h,w = img.shape[:2]
l,t,r,b = 0,0,w,h
# 构造DLIB类型
face = dlib.rectangle(l,t,r,b)
# 获取关键点
points = shape_detector(img,face)
# 获取特征描述符
face_descriptor = face_descriptor_extractor.compute_face_descriptor(img,points)
# 转为numpy 格式的数组
face_descriptor = [f for f in face_descriptor]
face_descriptor = np.asarray(face_descriptor,dtype=np.float64)
face_descriptor = np.reshape(face_descriptor,(1,-1))
return face_descriptor
测试:
feat_test = getFaceFeat('C:\\Users\\zunly\\OneDrive\\media_sample\\FACE\\chinese_faces_cleaned\\陈佩斯\\陈佩斯_5.jpg')
输出:
print(feat_test.shape)
结果是1,128, 即提取出64个特征点的xy坐标.
接下来就以陈佩斯(我还挺喜欢这个演员的, 真正的演员, 而不是戏子)这个目录内, 挨个计算欧氏距离, 并剔除脏数据-鲁豫的照片(我说数据脏哈, 人只是瘦了点, 不脏)
# 初始化特征列表,记录文件名
feature_list = None
record_file = []
# 获取该人名下的所有图片
# file_name = person+'/*.jpg'
img_list = glob.glob("C:\\Users\\zunly\\OneDrive\\media_sample\\FACE\\chinese_faces_cleaned\\陈佩斯\\*")
# 遍历图片
for img_file in img_list:
# 获取每一张图片的特征
feat = getFaceFeat(img_file)
#过滤数据
if feat is not None:
if feature_list is None:
feature_list = feat
else:
# 特征列表
feature_list = np.concatenate((feature_list,feat),axis=0)
# 记录一下文件名
record_file.append(img_file)
# 计算欧式距离
# 依次计算一个特征描述符与所有特征的距离
for i in range(len(feature_list)):
dist_list = np.linalg.norm((feature_list[i]-feature_list),axis=1)
dist_average = np.average(dist_list)
# print(dist_average)
#如果大于特征阈值,说明它与其他不同
if dist_average > 0.6:
remove_file = record_file[i]
# 先复制到chinese_faces_mislabeled下,再在路径中删除
# person_class = person.split('\\')[-1]
# 创建需要保存的目录
save_dir = 'C:\\Users\\zunly\\OneDrive\\media_sample\\FACE\\chinese_faces_mislabeled\\陈佩斯\\'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 复制
shutil.copy(remove_file, save_dir)
# 删除
os.remove(remove_file)
print('删除'+remove_file)
windows下面目录要用双斜杠 “\“ , linux是用反斜杠 “/“ 即可.

可以成功找到不是这个类别的图片, 并移动到其他地方.
接下来用同样的办法, 把所有数据都过滤一遍.
# 遍历每个人的文件夹
for person in tqdm.tqdm(person_list):
# 初始化特征列表,记录文件名
feature_list = None
record_file = []
# 获取该人名下的所有图片
file_name = person+'\\*.jpg'
img_list = glob.glob(file_name)
# 遍历图片
for img_file in img_list:
# 获取每一张图片的特征
feat = getFaceFeat(img_file)
#过滤数据
if feat is not None:
if feature_list is None:
feature_list = feat
else:
# 特征列表
feature_list = np.concatenate((feature_list,feat),axis=0)
# 记录一下文件名
record_file.append(img_file)
if feature_list is None:
continue
# 计算欧式距离
# 依次计算一个特征描述符与所有特征的距离
for i in range(len(feature_list)):
dist_list = np.linalg.norm((feature_list[i]-feature_list),axis=1)
dist_average = np.average(dist_list)
# print(dist_average)
#如果大于特征阈值,说明它与其他不同
if dist_average > 0.6:
remove_file = record_file[i]
# 先复制到chinese_faces_mislabeled下,再在路径中删除
person_class = person.split('\\')[-1]
# 创建需要保存的目录
save_dir = 'C:\\Users\\zunly\\OneDrive\\media_sample\\FACE\\chinese_faces_mislabeled\\'+person_class
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 复制
shutil.copy(remove_file, save_dir)
# 删除
os.remove(remove_file)
print('删除'+remove_file)
# break
成功筛选出脏数据:
不过仔细观察脏数据发现, 倒不是真的标签问题, 而是数据特征可能不够明显, 比如人物闭眼了
或者角度太偏:

但是对最终的训练肯定是不利的.
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:995次2023-11-13 11:08:23
-
浏览量:1027次2023-07-26 09:40:01
-
浏览量:1725次2024-01-24 16:33:36
-
浏览量:1790次2024-02-04 10:08:58
-
浏览量:1099次2023-08-30 18:29:45
-
浏览量:883次2023-08-18 08:57:27
-
浏览量:1878次2023-03-09 09:38:33
-
浏览量:2137次2023-03-09 15:39:13
-
浏览量:2928次2019-06-28 10:35:50
-
浏览量:2787次2018-04-21 14:25:30
-
浏览量:2363次2024-01-22 17:02:06
-
浏览量:2420次2019-10-26 10:21:25
-
浏览量:1834次2024-03-14 17:53:46
-
浏览量:1403次2024-03-05 16:31:54
-
2021-06-22 16:27:28
-
浏览量:6367次2021-07-28 14:21:28
-
浏览量:2291次2022-12-16 09:12:30
-
浏览量:1981次2023-11-09 15:33:49
-
浏览量:1681次2018-04-26 21:12:55






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

Marc

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
