

OpenCV学习SVM图像分类

SVM图像分类我们从理论部分和代码实现两部分进行讲解,注重基本概念和核心算法的理解。
一、图像分类
图像分类属于图像识别的部分,图像分类是指利用计算机对图像进行定量分析,把图像中的每个像元或区域划归为若干个类别中的一种,以代替人工视觉判读的技术。从目视角度来说对图像进行预处理如提高对比度、增加视觉维数、进行空间滤波或变换等处理使人们能够凭借知识和经验,根据图像亮度、色调、位置、纹理和结构等特征,准确地对图像景物类型或目标做出正确的判读和解释。另外一个很重要的概念就是特征提取,它是指使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。
二、SVM图像分类的基本流程
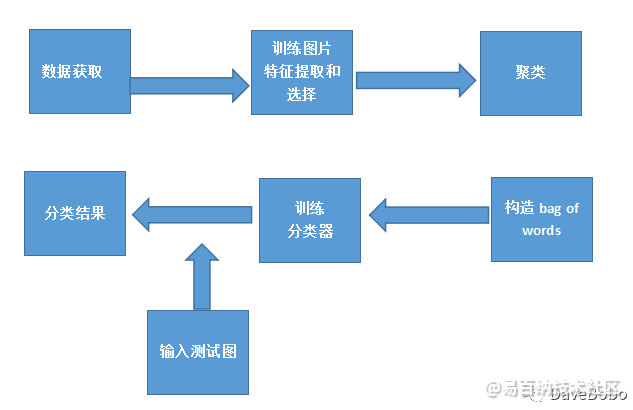
1.获取数据
图像可以是通过摄像机或视频头采样获得的数据,也可以是一般的统计数据集,其中的数据以向量或矩阵形式表示,或者是已经准备好的待检测的图片
2.训练图片 特征提取和选择
特征提取是指从对象本身获取各种对于分类有用的度量或属性。特征选择是指如何从描述对象的多种特征中找出对于那些分类最有效的特征。特征提取我们用到surf算法,surf具有比sift快的检测速度。
对某一类模式的识别,其关键在于对模式特征的描述以及如何去提取这些特征。特征描述直接影响到特征提取以及特征向量库的建立,并影响到最后分类别图像的特征提取和分类别精度的高低 。从理论上讲,个体的特征是唯一的,这是因为不存在完全相同的两个个体。但是由于客观条件限制的存在,往往使得选取的特征并不是描述个体的特征全集,而只是特征的一个子集。因此,确定物体的本质特征是识别任务成功的关键。为了提高特征提取时计算的鲁棒性,往往又要求用尽可能少的特征来描述物体,这使得在实际应用中特征描述的不完全性是不可避免的。
3.将这些feature聚成n类。这n类中的每一类就相当于是图片的“单词”,所有的n个类别构成“词汇表”。我的实现中n取1000,如果训练集很大,应增大取值。
4.对训练集中的图片构造bag of words,就是将所有训练图片中的feature归到不同的类中,然后统计每一类的feature的频率。这相当于统计一个文本中每一个单词出现的频率。
5.分类器的设计
利用样本数据来确定分类器的过程称为分类器设计。训练一个多类分类器,将每张图片的bag of words作为feature vector,将该张图片的类别作为label。支持向量机(Support Vector Machines,SVM)应用的典型流程是首先提取图形的局部特征所形成的特征单词的直方图来作为特征,最后被通过SVM进行训练得到模型。
在图像分类中用到了一种模型叫做BOW (bag of words) 模型。Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是将每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
最后通过训练好的模型,再次读取未经分类的图片,就可以对其分类。
流程图如图所示:
三、实验
实验主要是先将一些已经归类好的图片作为输入,再对一些未知类别的图片进行预测分类。本模块在该项目中可以分出二维码、logo、以及文字 。例如:给定图像,检测并读取其中所有的条码、logo、文字,即使他们处于任意的位置及角度,如果图像中可能有任意数量及格式的条码、logo和文字,输出所有的条码、logo和文字(1个或多个)。
理论部分我们谈到了使用BOW模型,但是BOW模型如何构建以及整个步骤是怎么样的呢?可以参考博客http://www.cnblogs.com/yxy8023ustc/p/3369867.html从这篇博客中我们可以知道BOW模型的步骤主要包括四步:
1.提取训练集中图片的feature
2.将这些feature聚成n类。这n类中的每一类就相当于是图片的“单词”,所有的n个类别构成“词汇表”。我的实现中n取1000,如果训练集很大,应增大取值。
3.对训练集中的图片构造bag of words,就是将图片中的feature归到不同的类中,然后统计每一类的feature的频率。这相当于统计一个文本中每一个单词出现的频率
4.训练一个多类分类器,将每张图片的bag of words作为feature vector,将该张图片的类别作为label。
对于未知类别的图片,计算它的bag of words,使用训练的分类器进行分类。上面整个工程步骤所涉及到的函数,我都放在一个类categorizer里, 下面按步骤说明具体实现,程序示例有所省略,完整的程序可看工程源码。
NO1 特征提取
对图片特征的提取包括对每张训练图片的特征提取和每张待检测图片特征的提取,我使用的是surf,所以使用OpenCV的SurfFeatureDetector检测特征点,然后再用SurfDescriptorExtractor抽取特征点描述符。对于特征点的检测和特征描述符的讲解可以参考中文opencv中文官网:
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_detection/feature_detection.html#feature-detection以及http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_description/feature_description.html#feature-description
我训练图片特征提取的示例代码如下:
Mat vocab_descriptors;
// 对于每一幅模板,提取SURF算子,存入到vocab_descriptors中
multimap<string,Mat> ::iterator i=train_set.begin();
for(;i!=train_set.end();i++)
{
vector<KeyPoint>kp;
Mat templ=(*i).second;
Mat descrip;
featureDecter->detect(templ,kp);
descriptorExtractor->compute(templ,kp,descrip);
//push_back(Mat);在原来的Mat的最后一行后再加几行,元素为Mat时, 其类型和列的数目 必须和矩阵容器是相同的
vocab_descriptors.push_back(descrip);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意:上述代码只是工程的一个很小的部分,有些变量在类中已经定义,在这里没有贴出来,例如上述的train_set训练图片的映射,定义为:
/从类目名称到训练图集的映射,关键字可以重复出现
multimap<string,Mat> train_set; - 1
将每张图片的特征描述符存储起来vocab_descriptors,然后为后面聚类和构造训练图片词典做准备。
NO2 feature聚类
由于opencv封装了一个类BOWKMeansExtractor[2],这一步非常简单,将所有图片的feature vector丢给这个类,然后调用cluster()就可以训练(使用KMeans方法)出指定数量(步骤介绍中提到的n)的类别。输入vocab_descriptors就是第1步计算得到的结果,返回的vocab是一千个向量,每个向量是某个类别的feature的中心点。
示例代码如下:
//将每一副图的Surf特征利用add函数加入到bowTraining中去,就可以进行聚类训练了
bowtrainer->add(vocab_descriptors);
// 对SURF描述子进行聚类
vocab=bowtrainer->cluster(); - 1
- 2
- 3
- 4
bowtrainer的定义如下:
bowtrainer=new BOWKMeansTrainer(clusters); - 1
NO.3 构造bag of words
对每张图片的特征点,将其归到前面计算的类别中,统计这张图片各个类别出现的频率,作为这张图片的bag of words。由于opencv封装了BOWImgDescriptorExtractor[2]这个类,这一步也走得十分轻松,只需要把上面计算的vocab丢给它,然后用一张图片的特征点作为输入,它就会计算每一类的特征点的频率。
allsamples_bow这个map的key就是某个类别,value就是这个类别中所有图片的bag of words,即Mat中每一行都表示一张图片的bag of words。
//对每张图片的特征点,统计这张图片各个类别出现的频率,作为这张图片的bag of words
bowDescriptorExtractor->setVocabulary(vocab);
}
// 对于每一幅模板,提取SURF算子,存入到vocab_descriptors中
multimap<string,Mat> ::iterator i=train_set.begin();
for(;i!=train_set.end();i++)
{
vector<KeyPoint>kp;
string cate_nam=(*i).first;
Mat tem_image=(*i).second;
Mat imageDescriptor;
featureDecter->detect(tem_image,kp);
bowDescriptorExtractor->compute(tem_image,kp,imageDescriptor);
//push_back(Mat);在原来的Mat的最后一行后再加几行,元素为Mat时, 其类型和列的数目 必须和矩阵容器是相同的
allsamples_bow[cate_nam].push_back(imageDescriptor);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上面部分变量的定义如下:
//存放所有训练图片的BOW
map<string,Mat> allsamples_bow;
//特征检测器detectors与描述子提取器extractors 泛型句柄类Ptr
Ptr<FeatureDetector> featureDecter;
Ptr<DescriptorExtractor> descriptorExtractor;
Ptr<BOWKMeansTrainer> bowtrainer;
Ptr<BOWImgDescriptorExtractor> bowDescriptorExtractor;
Ptr<FlannBasedMatcher> descriptorMacher; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
NO.4 训练分类器
我使用的分类器是svm,用经典的1 vs all方法实现多类分类。对每一个类别都训练一个二元分类器。训练好后,对于待分类的feature vector,使用每一个分类器计算分在该类的可能性,然后选择那个可能性最高的类别作为这个feature vector的类别。
训练二元分类器
llsamples_bow:第3步中得到的结果。
category_name:针对哪个类别训练分类器。
svmParams:训练svm使用的参数。
stor_svms:针对category_name的分类器。
属于category_name的样本,label为1;不属于的为-1。准备好每个样本及其对应的label之后,调用CvSvm的train方法就可以了。
示例代码如下:
stor_svms=new CvSVM[categories_size];
//设置训练参数
SVMParams svmParams;
svmParams.svm_type = CvSVM::C_SVC;
svmParams.kernel_type = CvSVM::LINEAR;
svmParams.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
cout<<"训练分类器..."<<endl;
for(int i=0;i<categories_size;i++)
{
Mat tem_Samples( 0, allsamples_bow.at( category_name[i] ).cols, allsamples_bow.at( category_name[i] ).type() );
Mat responses( 0, 1, CV_32SC1 );
tem_Samples.push_back( allsamples_bow.at( category_name[i] ) );
Mat posResponses( allsamples_bow.at( category_name[i]).rows, 1, CV_32SC1, Scalar::all(1) );
responses.push_back( posResponses );
for ( auto itr = allsamples_bow.begin(); itr != allsamples_bow.end(); ++itr )
{
if ( itr -> first == category_name[i] ) {
continue;
}
tem_Samples.push_back( itr -> second );
Mat response( itr -> second.rows, 1, CV_32SC1, Scalar::all( -1 ) );
responses.push_back( response );
}
stor_svms[i].train( tem_Samples, responses, Mat(), Mat(), svmParams );
//存储svm
string svm_filename=string(DATA_FOLDER) + category_name[i] + string("SVM.xml");
stor_svms[i].save(svm_filename.c_str());
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
对于SVM的参数以及函数调用的介绍可以参考中文官网http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html#introductiontosvms
部分变量的定义如下:
// 训练得到的SVM
CvSVM *stor_svms;
//类目名称,也就是TRAIN_FOLDER设置的目录名
vector<string> category_name;
//类目数目
int categories_size; - 1
- 2
- 3
- 4
- 5
- 6
NO.5 对未知图片进行分类
使用某张待分类图片的bag of words作为feature vector输入,使用每一类的分类器计算判为该类的可能性,然后使用可能性最高的那个类别作为这张图片的类别。prediction_category就是结果,test就是某张待分类图片的bag of words。示例代码如下:
Mat input_pic=imread(train_pic_path);
imshow("输入图片:",input_pic);
cvtColor(input_pic,gray_pic,CV_BGR2GRAY);
// 提取BOW描述子
vector<KeyPoint>kp;
Mat test;
featureDecter->detect(gray_pic,kp);
bowDescriptorExtractor->compute(gray_pic,kp,test);
float scoreValue = stor_svms[i].predict( test, true );
float classValue = stor_svms[i].predict( test, false );
sign = ( scoreValue < 0.0f ) == ( classValue < 0.0f )? 1 : -1;
curConfidence = sign * stor_svms[i].predict( test, true );
if(curConfidence>best_score)
{
best_score=curConfidence;
prediction_category=cate_na;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
上面就是四个主要步骤的部分示例代码,很多其他部分代码没有贴出来,比如说如何遍历文件夹下面的所有不同类别的图片,因为训练图片的样本比较多的话,训练图片是一个时间比较长久的,那么如何在对一张待测图片进行分类的时候,不需要每次都重复训练样本,而是直接读取之前已经训练好的BOW...很多很多。
我的main函数实现如下:
int main(void)
{
int clusters=1000;
//初始化
categorizer c(clusters);
//特征聚类
c.bulid_vacab();
//构造BOW
c.compute_bow_image();
//训练分类器
c.trainSvm();
//将测试图片分类
c.category_By_svm();
return 0;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1716次2023-07-14 14:36:03
-
浏览量:977次2023-11-09 13:45:46
-
浏览量:1118次2023-07-17 13:57:30
-
浏览量:1639次2020-08-29 19:46:28
-
浏览量:1078次2023-07-05 11:03:52
-
浏览量:1177次2023-09-25 10:59:14
-
浏览量:4347次2021-04-19 14:54:23
-
浏览量:13037次2021-05-11 15:08:10
-
浏览量:6292次2021-06-07 11:48:50
-
浏览量:780次2024-01-12 11:39:24
-
浏览量:1232次2024-03-14 18:20:47
-
浏览量:873次2024-03-05 16:55:32
-
浏览量:50076次2021-07-28 14:21:08
-
浏览量:4298次2021-05-25 16:44:59
-
浏览量:729次2023-12-19 11:06:03
-
浏览量:4807次2021-01-21 14:02:11
-
浏览量:718次2023-09-11 18:04:33
-
浏览量:4560次2021-01-12 18:43:19
-
浏览量:6109次2021-07-28 14:21:28






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

易木雨

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
