

h264解码器基础学习(1)

一、前言:
从这一节开始,我们真正进入了解码的过程。
相信很多人和我一样,刚开始的时候都会很好奇,为什么h264可以实现这么强大的压缩比,要知道,1张1080p的YUV420就是3MB,想实现1秒钟30帧,千兆网就基本跑满了,这也太可怕了,基本上只有条件很好的局域网才能达到这个水平。但是h264的出现把这个数据量降到了百分之一,2个数量级,这实在太可怕了,技术的发展真的是强大。
其实h264编解码,就是从YUV文件和h264文件中相互转化的过程。不同的是,YUV数据量大,结构简单,适合在本地显示使用,h264数据量小,无法直接显示,适合传输使用。这也就是编码器和解码器存在的意义。
二、基础知识:
2.1 为什么h264可以压缩:
本来没打算写这些,聊到这里感觉避不过去,就简单聊两句。
为什么h264可以实现压缩?
- 在我们的物理世界中,图像一般都是连续的,而且现在的帧率一般足够高,导致前后帧同一个位置的图像一般不会出现大的变化,这样前后帧的图像就有很多的相同之处,H264在编码的时候只需要去编那些少量不同的地方就行了。这就是时间冗余
- 同样,在物理世界中,物体也是连续的,大部分情况下,相邻像素的变化也不大,比如同一个物体,单独裁出一小部分的时候你很难看出是什么位置,在h264中,我们可以用已知的相邻像素来推断当前的像素,这就是空间冗余
- 在我们常规的编码中,都使用的是等长编码,这在所有字符出现概率未知的情况下是合理的,但是在h264中,明显部分数据的出现概率要更高,比如一些小数,1,0,-1 这些,给这些高概率的数据分配更短的码字,也同样有助于减小数据量,这就是编码冗余
- 根据研究表明,人眼对一些颜色或者形状更加敏感,而对另外一些则更容易忽略,这种情况下,我们可以着重编码这些被重视的部分,而略过那些难以分辨的部分,在h264中,使用了量化技术来大大降低了数据量,这就是视觉冗余
- 通过一些先验知识来消除 知识冗余,这个我没想到264里是哪里用的,倒是NN encoder我觉得很符合这个。暂时挂在这里,以后想到了再来补坑。
三、NALU:
经过2.1 的解释,我们可以得知,最终的码流文件是将原始的YUV文件经过一定的规则编码而成一个新的二进制文件,这个文件的大小相比之前小了很多,但是却不能直观的得到图像的数据,我们的任务就是从这个二进制文件里获取到原来YUV文件的像素YUV的值。
打开一个h264文件,两眼一黑。
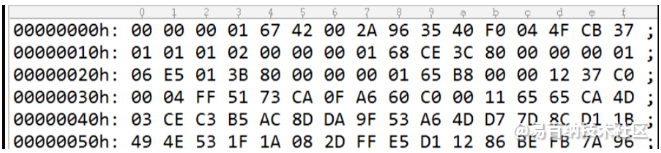
这都是些啥,一点规律没有,这怎么看?
别急,接下来,让我们一点点来分析。
3.1 NALU是什么:
H264分为Network abstract layer 网络抽象层 和 video coding layer 视频编码层。
NALU是 Network abstract layer unit,也是网络发送的基本单元,每个NALU都有自己的作用,类型,数据格式以及重要性。不同NALU之间在发送上是相互独立的,发送端甚至可以使用不同的传输模式来传输码流,比如使用稳定的TCP来传递重要性高的NALU,使用快速的UDP来传输重要性低的NALU,这些都是可以的。
也就是说,这个我们的打开的H264的二进制文件中,其实是由很多个NALU单元组成的,我们第一步要做的,就是从文件中找到这些NALU,挨个取出他们来进行分析。
3.2 如何获取一个NALU:
因为每个NALU的长度不一且未知,解码器需要根据他们的打包方式来进行解码。在NALU组合码流的过程中,一般有两种使用比较常见的打包方式:AnnxB 和 avcC。
- Annex B [əˈneks]Annex B 是比较常用的一种打包方式,详见《Rec. ITU-T H.264 (03/2010)》 305面。

根据表格可以看出,在 nal_unit之前,插入了一个 start_code_prefix_one_3bytes的 起始码作为标记,这个起始码的值为0x00 0x00 0x01。
我们在解码中,只需要去找固定的0x00 0x00 0x01的字符串即可。
实际在264码流里面一般会用到两种起始码,4字节 0x00 00 00 01或者3字节 0x00 00 01.
一般4字节起始码用于SPS,PPS和每帧的第一个Slice,3字节起始码用于其他的NALU(例如多slice时一帧内的非第一slice)。
在同一个码流中,也会两种混用。
不过我觉得问题不大,只要找到0x00 00 01,作为开头,准没错。我在自己的解码器里也是这么找的。
- avcC:avcC的使用没有AnnexB的模式使用的多,avcC会把Nalu的长度写在开头,然后去找固定长度的字节即可。
3.3 NALU header:
当我们根据起始码成功定位出NALU的位置之后,每个NALU的第一个字节都是固定的NALU header。
这个header非常重要,决定了这个NALU的类型,重要性,也决定了解码器如何去解码,以及能获取到的信息。

根据协议可以看出NALU header的组成是:
NALU header:1字节 8bit,具体分为
fordidden_zero_bit(1bit) | nal_ref_idc(2bit) | nal_unit_type(5bit) 如图:
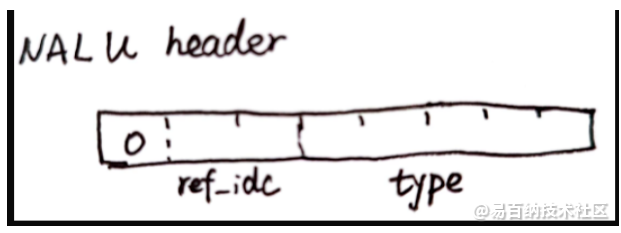
其中:
- fordidden_zero_bit:固定为0,如果解码器检测到不为0,表示NALU出错,解码器可以选择丢弃或者修复这个NALU。
- nal_ref_idc:重要程度,0~3. 值越高,说明越重要。一般SPS,PPS,IDR的slice都会选择大于0的值
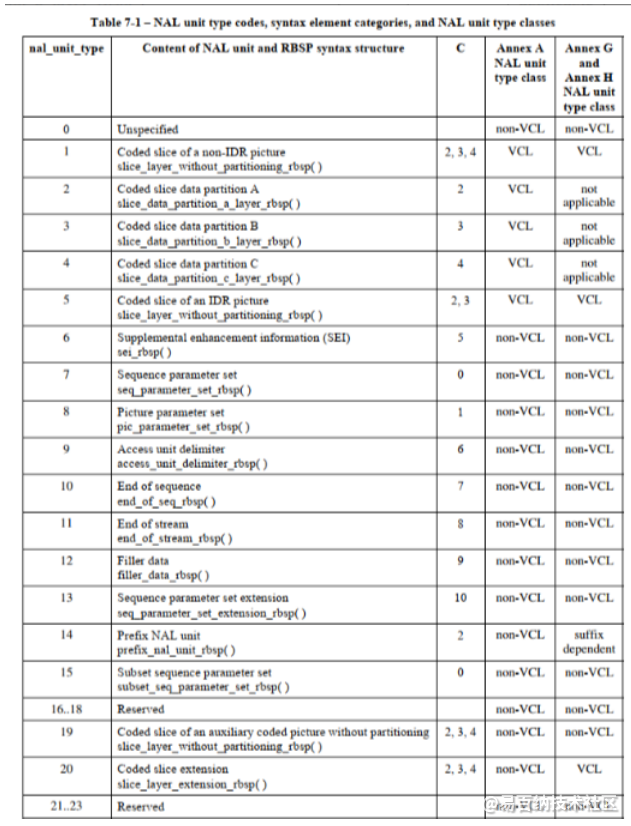
- nal_unit_type:NALU类型如下图,比较重要的是 SPS(7),PPS(8),IDR slice(5) 等等。
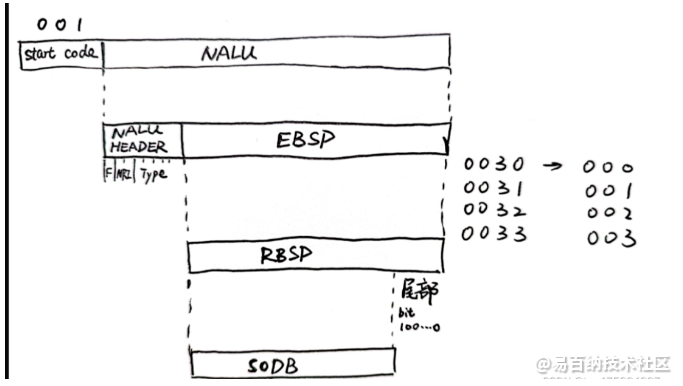
3.4 NAL的防竞争码, EBSP与RBSP:
EBSP 扩展字节序列载荷,协议中未定义,JM中使用的。RBSP。
因为我们需要根据0x00 00 01的起始码来将码流数据分成多个NALU,但是,如果原始数据里就存在0x00 00 01这样的数据,就会导致识别错误,从来切分NALU失败。
这里采用了防竞争码的方式,将原始码 中的一些特定组合进行防竞争码的转换。
0x 00 00 01 -> 0x 00 00 03 01
0x 00 00 02 -> 0x 00 00 03 02
0x 00 00 03 -> 0x 00 00 03 03解码过程则逆过来即可,在真实码流中的NALU中,检测到0x00 00 03 01就转成 0x00 00 01,检测到0x00 00 03 02就转成 0x00 00 02,检测到0x00 00 03 03就转成 0x00 00 03,。
可能大家又会担心,那原始码流中如果本来就有类似0x00 00 03 01 ,0x00 00 03 02 这种组合呢?是不是转换回来就错了?其实不会的。
假设原始码流中有 0x00 00 03 02, 在编码时,会被替换防竞争码, 变成 0x00 00 03 03 02,这样,在解码的时候,依然可以原样的解回来,就不会出错了。
3.5 获取SODB:
视频在编码时,是按照bit来编的,这样可能导致编出来的SODB码流长度不是整byte的。
因此,协议规定,如果遇到这种情况,先写入 1 bit 数据,数据内容是 1,然后开始补齐 0,直到补齐到一整个字节。
那如果正好是整byte的呢?那就再补1个0x80的字节(1bit的1,剩下补0)。解码方法也是一样,从RBSP里的末尾开始按bit找0,找到第一个不是0的位,就是尾部的开始。
至此,我们已经成功拿到了一个NALU的Data,下面,我们需要根据NALU header里解析出来的type,按照不同的语法对其进行解析。具体请见下一篇博文。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1981次2023-11-01 11:26:42
-
浏览量:4985次2021-04-27 16:33:22
-
浏览量:5914次2021-04-27 16:33:54
-
浏览量:1072次2023-10-23 17:56:00
-
浏览量:2680次2020-05-22 19:32:20
-
浏览量:2869次2024-02-27 17:03:43
-
浏览量:2447次2024-01-26 15:15:36
-
浏览量:3495次2018-05-07 16:22:35
-
浏览量:1080次2023-06-12 14:34:57
-
浏览量:1148次2023-06-30 09:18:17
-
浏览量:1220次2023-06-30 10:11:29
-
浏览量:1886次2023-06-12 14:34:40
-
浏览量:5339次2018-11-13 10:03:09
-
浏览量:6325次2020-08-20 14:18:11
-
浏览量:4275次2020-08-05 20:32:31
-
浏览量:5777次2019-12-28 10:17:47
-
浏览量:2609次2023-06-12 14:35:30
-
浏览量:3393次2020-08-10 09:24:28
-
浏览量:14297次2023-12-27 20:28:48




-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
txp

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
