

使用递归神经网络进行时间序列预测

时间序列预测在金融、医疗保健和物流等各个领域都是必不可少的。传统的统计方法(如 ARIMA 和指数平滑)为我们提供了很好的服务,但在捕获数据中的复杂非线性关系方面存在局限性。这就是递归神经网络(RNN)提供优势的地方,为复杂的时间相关现象建模提供了强大的工具。本文旨在成为使用 RNN 进行时间序列预测的综合指南。
本指南为复杂的时间相关现象建模提供了强大的工具,详细介绍了使用 RNN 进行时间序列预测,涵盖了从设置环境到构建和评估 RNN 模型的所有内容。

设置您的环境
在为时序数据构建 RNN 模型之前,必须设置 Python 环境。如果未安装 Python,请从官方网站下载。接下来,您需要一些额外的数据操作和建模库。打开终端并执行:
pip install numpy tensorflow pandas matplotlib sklearnRNN 的基础知识
递归神经网络 (RNN) 是用于序列预测的专用神经架构。与传统的前馈神经网络不同,RNN 具有支持信息持久性的内部循环。这种独特的结构使他们能够捕获时间动态和上下文,使其成为时间序列预测和自然语言处理任务的理想选择。然而,RNN面临着诸如梯度消失和爆炸等问题的挑战,LSTM和GRU等高级架构已经部分缓解了这些问题。
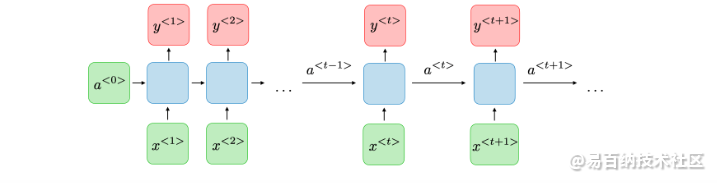
为什么要使用 RNN 进行时间序列预测?
时间序列数据通常包含简单统计方法无法捕获的复杂模式。RNN具有记住过去信息的能力,自然适合此类任务。它们可以捕获复杂的关系、季节性模式,甚至是数据中的异常,使其成为时间序列预测的有力候选者。
为什么要使用 RNN 进行时间序列预测?
时间序列数据通常包含简单统计方法无法捕获的复杂模式。RNN具有记住过去信息的能力,自然适合此类任务。它们可以捕获复杂的关系、季节性模式,甚至是数据中的异常,使其成为时间序列预测的有力候选者。
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
# Sample Data (replace this with your time-series data)
data = np.random.rand(100, 1)
# Preprocessing
X, y = data[:-1], data[1:]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# RNN Model
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(50, activation='relu', input_shape=(X_train.shape[1], 1)),
tf.keras.layers.Dense(1)
])
# Compilation
model.compile(optimizer='adam', loss='mse')
# Training
model.fit(X_train, y_train, epochs=200, verbose=0)
# Evaluation
loss = model.evaluate(X_test, y_test)
print(f'Test Loss: {loss}')
特征工程和超参数调优
在实际场景中,特征工程和超参数优化对于构建用于时间序列预测的鲁棒 RNN 模型是不可或缺的。这些步骤可能涉及选择不同的RNN层,如LSTM或GRU,包括特征缩放和规范化等预处理步骤。实验是成功的关键。
下面是一个简单的Python代码片段,使用Scikit-learn库对示例时间序列数据集执行最小-最大缩放:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# Sample time-series data
data = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]])
# Initialize the MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
# Fit and transform the data
scaled_data = scaler.fit_transform(data)
print("Scaled data:", scaled_data)超参数调优
超参数调优通常涉及试验不同类型的层、学习率和批量大小。像这样的工具在系统地搜索超参数网格时很有用。GridSearchCV
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
import numpy as np
# Function to create RNN model
def create_model(neurons=1):
model = Sequential()
model.add(SimpleRNN(neurons, input_shape=(None, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
return model
# Random seed for reproducibility
seed = 7
np.random.seed(seed)
# Create the model
model = KerasRegressor(build_fn=create_model, epochs=100, batch_size=10, verbose=0)
# Define the grid search parameters
neurons = [1, 5, 10, 15, 20, 25, 30]
param_grid = dict(neurons=neurons)
# Conduct Grid Search
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=3)
grid_result = grid.fit(X_train, y_train)
# Summarize the results
print(f"Best: {grid_result.best_score_:.3f} using {grid_result.best_params_}")
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print(f"Mean: {mean:.3f} (Std: {stdev:.3f}) with: {param}")评估指标和验证策略
指标
为了评估 RNN 模型的性能,常用的指标包括平均绝对误差 (MAE)、均方根误差 (RMSE) 和平均绝对百分比误差 (MAPE)。此外,交叉验证等技术在确保模型很好地泛化到看不见的数据方面非常有用。
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
# Sample true values and predictions
true_values = np.array([1.0, 1.5, 2.0, 2.5, 3.0])
predictions = np.array([0.9, 1.6, 2.1, 2.4, 3.1])
# Calculate MAE, RMSE, and MAPE
mae = mean_absolute_error(true_values, predictions)
rmse = np.sqrt(mean_squared_error(true_values, predictions))
mape = np.mean(np.abs((true_values - predictions) / true_values)) * 100
print(f"MAE: {mae}, RMSE: {rmse}, MAPE: {mape}%")验证策略
交叉验证技术,如k折叠交叉验证,对于确保RNN模型很好地推广到看不见的数据非常有益。您可以通过多次将数据集划分为训练集和验证集来评估模型在不同数据子集中的表现。
通过采用适当的指标和验证策略,您可以严格评估 RNN 模型的质量和可靠性,以进行时间序列预测。
# Sample Python code to demonstrate RNN in demand forecasting
# Note: This is a simplified example and should not replace a full-fledged model
import numpy as np
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense
# Generate some sample demand data
np.random.seed(0)
demand_data = np.random.randint(100, 200, size=(100, 1))
# Build a simple RNN model
model = Sequential()
model.add(SimpleRNN(4, input_shape=(None, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# Assume `X_train` as training features and `y_train` as labels
# model.fit(X_train, y_train, epochs=50, batch_size=1)局限性和未来方向
虽然递归神经网络(RNN)不可否认地彻底改变了时间序列预测,但它们也带来了挑战和局限性。一个主要障碍是它们的计算强度,特别是在处理长数据序列时。这种计算负担通常需要像GPU这样的专用硬件,这使得中小型组织难以大规模部署RNN。此外,RNN容易受到梯度消失或爆炸等问题的影响,这可能会影响模型的稳定性和有效性。
尽管存在这些挑战,但未来充满希望。有一个新兴的研究机构专注于优化RNN架构,降低其计算需求,并解决梯度问题。长短期记忆(LSTM)和门控循环单元(GRU)层等先进技术已经减轻了其中一些限制。此外,硬件加速技术的进步使得在现实世界的大规模应用中部署 RNN 变得越来越可行。这些持续的发展表明,虽然RNN有局限性,但它们远未充分发挥其潜力,使它们处于时间序列预测研究和应用的前沿。
结论
RNN 的出现显著提高了我们在时间序列预测方面的能力。它们捕获数据中复杂模式的能力使其成为任何处理时间序列数据的数据科学家或研究人员的宝贵工具。随着该领域的不断进步,我们可以期待出现更强大和计算效率更高的模型。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2131次2023-09-07 11:09:28
-
浏览量:4333次2018-02-14 10:30:11
-
浏览量:5595次2021-08-13 15:39:02
-
浏览量:6773次2021-07-26 11:27:40
-
浏览量:7701次2021-07-26 11:30:25
-
浏览量:1923次2023-01-21 10:13:45
-
浏览量:1000次2023-09-04 11:16:00
-
浏览量:943次2023-07-18 13:41:23
-
浏览量:5985次2021-05-28 16:59:25
-
浏览量:9030次2021-05-28 16:59:43
-
浏览量:852次2023-07-05 10:11:51
-
浏览量:1125次2023-07-05 10:11:45
-
浏览量:5414次2021-04-15 15:51:43
-
浏览量:1129次2023-09-06 11:12:55
-
浏览量:1007次2023-09-02 09:45:20
-
浏览量:811次2023-09-06 10:09:13
-
浏览量:1668次2023-03-07 09:26:18
-
浏览量:1850次2023-07-05 10:11:54
-
浏览量:11957次2020-12-16 17:38:28

tomato
===============













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
tomato

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
