

机器学习中相似度算法入门!!

大家好,今天来聊聊机器学习中的相似度算法!
在机器学习中,相似度算法是一种重要的技术,用于衡量和比较不同对象之间的相似程度。
解释一下
想象一下,你要给一组电影推荐系统编写一个算法。为了找到与用户喜好最相似的电影,你需要一种方法来比较电影之间的相似程度。
相似度算法就是干这个的。它会计算两个对象(如电影)之间的相似性,以便你可以找到最匹配用户喜好的电影。
基本原理
相似度算法的核心思想是将对象表示为特征向量或特征矩阵,并使用合适的度量方法来比较它们之间的差异。
通过计算这些差异的度量值,我们可以确定对象之间的相似程度。
相似度公式解释
相似度算法有多种度量方法,其中一种常见的方法是欧几里德距离(Euclidean Distance)。欧几里德距离用于计算两个对象之间的直线距离。以下是欧几里德距离的计算公式:
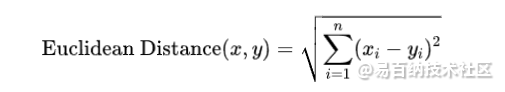
在上述公式中,x和y是两个对象的特征向量,n是特征的数量,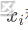 和
和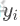 是对象在第i个特征上的取值。
是对象在第i个特征上的取值。
当涉及到相似度算法时,还有其他一些常见的方法。
- 曼哈顿距离(Manhattan Distance):曼哈顿距离是用于计算两个向量之间的距离的一种方法。它通过将两个向量中每个维度上的差值的绝对值相加来计算它们之间的距离。曼哈顿距离公式:
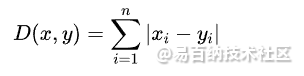
2. 编辑距离(Edit Distance):编辑距离用于度量两个字符串之间的差异,即通过插入、删除和替换操作将一个字符串转换为另一个字符串所需的最小操作数。
编辑距离公式:
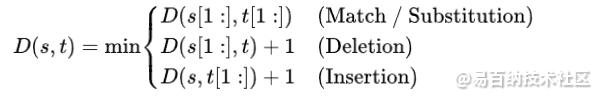
3. 余弦相似度(Cosine Similarity):余弦相似度是衡量两个向量之间夹角的相似性度量。它通过计算两个向量的点积与它们的模长之间的比值来度量它们之间的相似度。
余弦相似度公式:
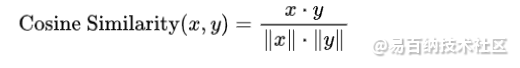
4. 皮尔逊相关系数(Pearson Correlation Coefficient):皮尔逊相关系数衡量两个变量之间线性关系的强度和方向。它在数据集中的协方差和标准差上进行计算,可以用于衡量两个变量之间的相似度。皮尔逊相关系数公式:
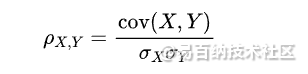
这是更多常见的相似度算法及其公式。每种算法都有不同的应用场景和特点,具体选择哪种算法取决于问题需求和数据类型。
利用Python绘制相似度图像的代码示例
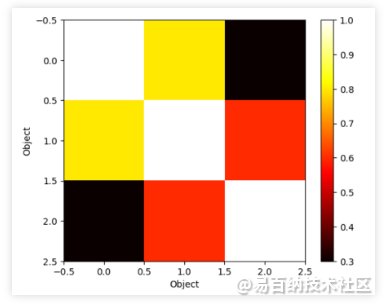
以下是使用Python和matplotlib库绘制相似度图像的示例代码:
import matplotlib.pyplot as plt
import numpy as np
def plot_similarity(similarity_matrix):
plt.imshow(similarity_matrix, cmap='hot', interpolation='nearest')
plt.xlabel('Object')
plt.ylabel('Object')
plt.colorbar()
plt.show()
# 创建一个相似度矩阵
similarity_matrix = np.array([[1.0, 0.8, 0.3],
[0.8, 1.0, 0.6],
[0.3, 0.6, 1.0]])
# 绘制相似度图像
plot_similarity(similarity_matrix)上述代码中,我们首先导入所需的模块。然后,定义了一个plot_similarity函数,该函数将相似度矩阵作为参数,并使用imshow函数将其可视化为热图。最后,使用colorbar函数添加颜色刻度。
这篇文章能够以简单易懂的方式介绍相似度算法的基本原理、公式解释,并提供了一个使用Python绘制相似度图像的示例代码。通过理解相似度算法的原理和应用,您可以更好地处理和比较不同对象之间的相似程度。
最后
相似度算法在许多领域中都有广泛的应用。比如下面列举的:
- 信息检索(Information Retrieval):相似度算法用于衡量文档之间的相似性,以便在搜索引擎或文本分类任务中找到与查询相关的文档。
- 推荐系统(Recommendation Systems):相似度算法用于计算用户之间的兴趣相似度,从而基于用户历史行为和偏好向他们推荐个性化的产品、电影或音乐。
- 聚类分析(Clustering Analysis):相似度算法用于将数据点分组成具有相似特征的集群,例如在市场细分、图像分割和社交网络分析中。
- 图像识别(Image Recognition):相似度算法用于比较图像之间的相似性,例如在图像搜索、人脸识别和图像聚类等任务中。
- 自然语言处理(Natural Language Processing):相似度算法用于计算两个文本之间的相似性,例如在文本匹配、问答系统和文档摘要生成中。
- 模式识别(Pattern Recognition):相似度算法用于计算样本之间的相似性,以实现模式分类、图像识别和信号处理等任务。
这些是相似度算法最常用的领域,但并不局限于此。相似度算法在许多其他领域中也有广泛的应用,如推荐系统、音频处理、网络分析等。它们帮助我们量化和比较数据之间的相似性,从而为各种任务提供基础支持和决策依据。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1000次2023-09-04 10:30:14
-
浏览量:2666次2023-08-28 14:50:41
-
浏览量:3716次2019-09-18 22:22:32
-
浏览量:1205次2023-12-15 14:10:52
-
浏览量:1330次2023-03-13 10:01:59
-
浏览量:1788次2018-12-19 10:11:25
-
浏览量:2127次2018-12-19 09:52:55
-
浏览量:5246次2021-07-05 09:46:48
-
浏览量:4793次2021-06-28 14:10:22
-
浏览量:197次2023-08-15 22:50:27
-
浏览量:1024次2023-03-14 13:50:59
-
浏览量:1993次2019-12-12 09:19:09
-
浏览量:10146次2021-02-23 16:44:17
-
浏览量:5338次2021-07-02 14:29:53
-
浏览量:999次2023-07-05 10:15:45
-
浏览量:5330次2021-06-29 12:05:47
-
浏览量:841次2024-02-28 15:03:08
-
浏览量:3365次2023-11-14 13:37:34
-
浏览量:10213次2021-04-20 15:42:26






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
圈圈

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
