

电商搜索推荐算法系列-序列模型- DIN

前言
电商搜索推荐场景,算法过程一般分为4步:召回/粗排/精排/重排。一般业务级别的场景只要召回和精排就可以了,更复杂的可能有粗排和重排,但多数是卷,普通的小公司投入ROI是很低的,没有必要。
- 召回阶段:在搜索中,召回算法来保证搜索相关性,召回的商品和用户的query需要相应匹配,这里更多的是短文本相关性技术。在推荐场景召回主要是保证用户的兴趣召回,主要包括CF,Swing,Simrank,deepMatch等技术。
- 粗排阶段:对于大规模的用户和商品空间,召回阶段返回可用的商品可能有大几万,如果直接都输出到精排层,都被复杂模型来打分是不现实。精排模型一般是足够复杂,一般打上千个的分的开销已经很大,如果更多,会对系统的性能和RT产生很大的问题。这样就需要有个相对简单的模型,将几万的商品截断成几百个。粗排模型一般和精排模型的目标一致,只是高性能牺牲部分准确率,甚至是精排模型的简单蒸馏。
- 精排阶段:排序模型,就是各种复杂的模型叠加,保证CTR/CVR等的准确率,保证目标的AUC,GAUC最大化,比如:FM,DIN,DIEN,WDL,DCN,TA,序列模型等。
- 重排阶段:一般的场景也不需要,因为排列的list组合是非常巨大的,很难直接遍历,所以只能在精排的输入1页(比如20个)内部进行重新排序,这样效果天然就会受限;另外,listwise在离线的样本构造是很复杂的,导致从样本构造的,到模型训练,到线上适配等,都比较复杂。
短序列- DIN-Deep Interest Network
重点Comment
- 主要目标:利用序列模型,Encode 用户的历史行为
- Attention Weight:利用当前的Target item,对历史的item进行权重筛选,进行加权Pooling
- 计算效率:如果设计Attention Weight,快速的进行序列计算
核心-Din attention
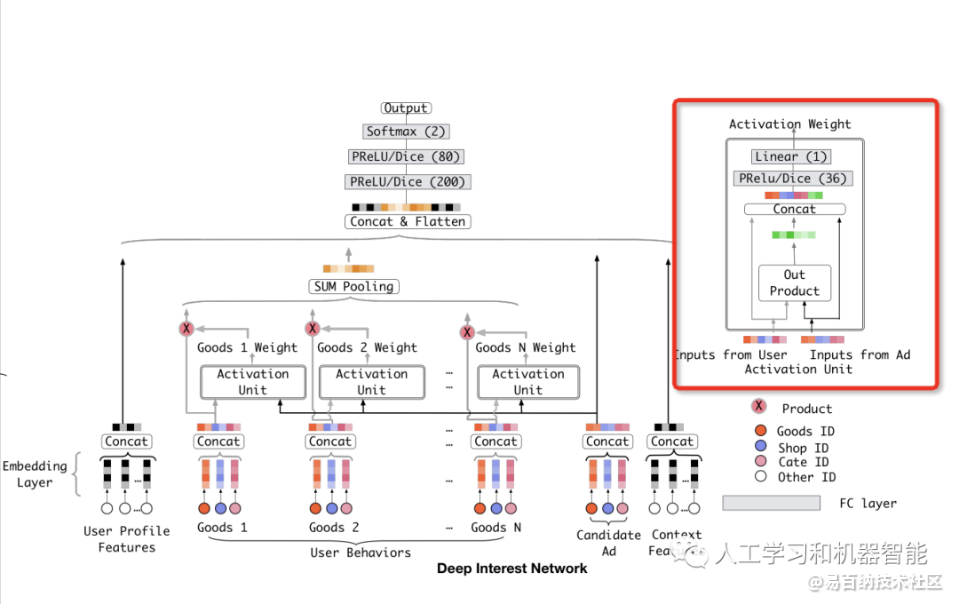
思想:计算目标商品与序列商品的Attention - Target attention
要对history_items进行聚合,聚合需要各个history_item的权重,history_item的权重通过贡献condidate_item的重要性Weights得到,然后对history_items加权求和
Din Target attention 过程
Activation Weight
- 通过将【condidate item,history items,相减,相乘】得到四个特征,然后concat
- 经过MLP,MASK和Scale
- 利用Softmax得到序列的Weights
- 利用Weights 和 history_items向量进行product操作,得到logit
def attention(queries, keys, keys_length):
'''
queries: [B, H]
keys: [B, T, H]
keys_length: [B]
'''
queries_hidden_units = queries.get_shape().as_list()[-1]
queries = tf.tile(queries, [1, tf.shape(keys)[1]])
queries = tf.reshape(queries, [-1, tf.shape(keys)[1], queries_hidden_units])
# 1. concat features
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
# 2. MLP
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att', reuse=tf.AUTO_REUSE)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(keys)[1]])
outputs = d_layer_3_all
# 2. Mask
key_masks = tf.sequence_mask(keys_length, tf.shape(keys)[1]) # [B, T]
key_masks = tf.expand_dims(key_masks, 1) # [B, 1, T]
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(key_masks, outputs, paddings) # [B, 1, T]
# 2. Scale
outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)
# 3. Activation Weights
outputs = tf.nn.softmax(outputs) # [B, 1, T]
# 4. Weighted sum
outputs = tf.matmul(outputs, keys) # [B, 1, H]
return outputs
Self-Attention 过程
目标商品Q和行为序列商品K计算的Attention Score中
EfficientSelf-Attention
扩展可打分的序列:
先利用Q,K的相识度,从K里面选择出TOP-K,然后进行打分,怎么快速找出TOPK
DIEN、
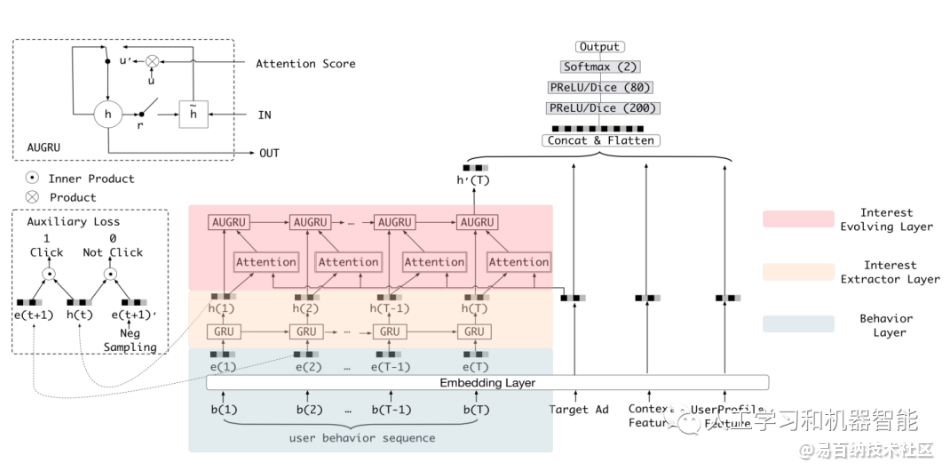
重点:在DIN的基础上,新增了个兴趣演化模块
兴趣提取模块

通过对b的embedding,e(t) 和 gru的状态输出 h(t) 做内积,
构造兴趣提取loss,label为0时随机采样的e。
兴趣提取模块使用GRU的隐状态来表达用户隐藏在行为背后的兴趣,
并且使用辅助loss来约束这个隐状态的学习(即通过给定每个隐状态以及一个行为能够准确的预测出用户是否会发生这次行为):
从兴趣提取的角度来讲负采样辅助loss能够约束GRU的每个隐状态更好的表达用户此刻的兴趣。
如果不加入这个loss,所有的监督信号都源于最后的点击样本。
点击率预估大多数情况下都会采用某个具体场景的样本,而希望通过某个具体场景样本的反馈信号能提取到用户每一个行为状态背后的兴趣是不现实的,
辅助loss的设计用一种优雅的方式引入了用户的全网行为反馈信息,同时不会引入多场景之间的点击bias以及造成多场景耦合;
从优化的角度来讲负采样辅助loss可以在gru的长序列建模中减少梯度反向传播的难度;
最后负采样辅助loss能提供更多语义信息来帮助Embedding层的学习,能够学习到更好的Embedding表达。
兴趣演化模块
就是个普通的gru encode过程。
附件
1https://arxiv.org/pdf/1706.06978.pdf
2https://github.com/zhougr1993/DeepInterestNetwork
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6624次2021-06-11 12:41:01
-
浏览量:2213次2018-05-13 16:56:19
-
浏览量:5326次2021-02-20 16:25:37
-
浏览量:963次2023-08-08 09:39:00
-
浏览量:2899次2020-11-21 17:26:21
-
浏览量:2524次2017-09-07 13:05:34
-
浏览量:19840次2021-01-06 19:08:06
-
浏览量:3118次2018-01-17 12:09:23
-
浏览量:2911次2022-02-26 09:00:10
-
浏览量:1420次2023-10-25 18:39:50
-
浏览量:4263次2020-11-17 10:13:00
-
浏览量:2840次2020-09-30 17:16:43
-
浏览量:1278次2023-01-12 17:13:47
-
浏览量:6213次2021-04-27 00:06:35
-
浏览量:1474次2023-08-04 10:55:54
-
浏览量:1195次2023-07-05 10:17:15
-
浏览量:1032次2023-09-04 11:09:13
-
浏览量:4838次2021-04-09 16:28:04
-
浏览量:5985次2021-04-20 15:43:03



-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
Uncle

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
