

【sklearn教程】使用SimpleImputer填补缺失值

在建模过程中,我们经常会遇到数据存在缺失值的情况,如果数据缺失不是很严重,可以使用一些简单的方法对数据进行缺失值填补,例如使用每个特征的中位数、均数或众数等来对该特征的缺失值进行填补。sklearn.impute模块中提供了函数SimpleImputer可以很方便地帮助我们实现这一需求,本文就来介绍这一函数及其用法。
参数详解
SimpleImputer函数的主要参数包括:
missing_values:指定缺失值的标识符,默认为np.nan,如果我们的数据是DataFrame,一般不用管,因为DataFrame默认缺失值就是np.nan。strategy:指定填补缺失值的策略。常见的策略包括:'mean'、'median'、'most_frequent'、'constant'。其中,'mean'表示使用均值填充,'median'表示使用中位数填充,'most_frequent'表示使用众数填充,'constant'表示使用一个常数填充。fill_value:当strategy为'constant'时,指定用于填充缺失值的常数。默认为None。copy:指定是否在原数组的基础上进行填充,还是创建一个新的数组进行填充。默认为True。
基本用法
SimpleImputer的用法非常简单,导入函数之后首先进行实例化:
from sklearn.impute import SimpleImputer
imp = SimpleImputer()然后调用实例的fit方法,传入待填补的数据矩阵 ,这一步的主要作用是获取每一列的均数(如果使用均数填补)等信息。
,这一步的主要作用是获取每一列的均数(如果使用均数填补)等信息。
imp = imp.fit(X)然后调用实例的transform方法,传入带填补的数据矩阵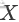 ,这一步才是正式地填补操作:
,这一步才是正式地填补操作:
X_imp = imp.fit(X)这就填补完成了。
实际上fit和transform两个方法可以用fit_transform方法一步完成:
X_imp = imp.fit_transform(X)实例一:用中位数、均数、众数、常数填补缺失值
下面介绍几个实例。我们以sklearn库中的diabetes数据集为例,演示如何使用中位数、均数、众数、常数进行缺失值填补:
from sklearn.datasets import load_diabetes
from sklearn.impute import SimpleImputer
# 加载数据集
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# 人为地将X的前10个特征的前20个值设为缺失值
import numpy as np
X[:20, :10] = np.nan
# 使用中位数填充缺失值
imputer_median = SimpleImputer(missing_values=np.nan, strategy='median')
X_median = imputer_median.fit_transform(X)
print(X_median[:20, :10])
# 使用均数填充缺失值
imputer_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
X_mean = imputer_mean.fit_transform(X)
print(X_mean[:20, :10])
# 使用众数填充缺失值
imputer_most_frequent = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
X_most_frequent = imputer_most_frequent.fit_transform(X)
print(X_most_frequent[:20, :10])
# 使用常数0填充缺失值
imputer_constant = SimpleImputer(missing_values=np.nan, strategy='constant', fill_value=0)
X_constant = imputer_constant.fit_transform(X)
print(X_constant[:20, :10])在上述代码中,我们首先人为地将diabetes数据集的前10个特征的前20个值设为缺失值。然后,我们使用SimpleImputer函数来分别使用中位数、均数、众数、常数0填充缺失值。最后,我们分别输出填充后的前20个样本的前10个特征的值,以便进行比较。
实例二:对测试集填充缺失值
在建模时如果使用SimpleImputer函数进行缺失值填充时,我们通常只对训练集进行填充,然后将填充后的训练集用于模型训练和测试。在填充测试集时,我们需要使用与训练集相关的信息,下面用一个例子来进行演示。
首先,我们需要导入必要的库以及数据集:
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
import numpy as np
diabetes = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size=0.2, random_state=42)在这里,我们同样使用的是diabetes数据集。我们先使用train_test_split()函数将数据集分为训练集和测试集,并将测试集大小设置为20%。然后,我们将训练集和测试集分别存储在X_train、X_test、y_train和y_test中。
接下来,我们可以使用NumPy库来创建一些缺失值。这里我们将数据集中的20%数据设置为NaN:
# 创建缺失值
missing_pct = 0.2
missing_mask = np.random.rand(*X_train.shape) < missing_pct
X_train[missing_mask] = np.nan
missing_mask = np.random.rand(*X_test.shape) < missing_pct
X_test[missing_mask] = np.nan在这里,我们使用np.random.rand()函数创建一个与训练集和测试集形状相同的随机掩码。如果掩码中的值小于缺失率(即20%),则将对应位置的数据设置为NaN。
现在,我们已经创建了缺失值,需要对其进行填充,这里我们使用中位数填充缺失值:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='median')
X_train_imputed = imputer.fit_transform(X_train)
X_test_imputed = imputer.transform(X_test)注意,这里我们先对训练集进行了填充,然后使用相同的imputer,并使用transform()方法对测试集进行填充。
最后,我们可以检查填充后数据集中是否还有缺失值:
rint(np.isnan(X_train_imputed).sum())
print(np.isnan(X_test_imputed).sum())实例三:按照不同类列填充缺失值
在分类问题中,对于不同类别,各个特征往往有不同的分布,此时根据不同类别来进行缺失值填补更加合理。下面就用一个实例进行演示。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import numpy as np
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=42)
# 创建缺失值
missing_pct = 0.2
missing_mask = np.random.rand(*X_train.shape) < missing_pct
X_train[missing_mask] = np.nan
missing_mask = np.random.rand(*X_test.shape) < missing_pct
X_test[missing_mask] = np.nan这里我们使用的是sklearn中威斯康星州乳腺癌数据集,我们还是使用实例二的方法划分训练集和测试集并创建缺失值。
from sklearn.impute import SimpleImputer
# 分组对训练集和测试集用均数填充缺失值
for v in np.unique(y_train):
imputer = SimpleImputer()
imputer = imputer.fit(X_train[y_train==v,:])
X_train[y_train==v,:] = imputer.transform(X_train[y_train==v,:])
X_test[y_test==v,:] = imputer.transform(X_test[y_test==v,:])这里我们首先根据训练集标签的不同类别,使用np.unique方法获取唯一的标签值,然后通过循环遍历这些标签值。在每次循环中,使用SimpleImputer方法创建一个Imputer对象,然后使用fit方法来拟合训练集中标签等于当前标签的部分数据,以获取该部分数据的均值。接下来,使用transform方法来填充训练集和测试集中标签等于当前标签的部分数据中的缺失值。从而实现了按照不同类别填充缺失值的目的。
文章转载自公众号:用Python学机器学习
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1152次2023-09-07 16:22:49
-
浏览量:1904次2023-09-05 18:20:58
-
浏览量:2260次2020-08-19 17:00:36
-
浏览量:11683次2024-01-19 13:48:15
-
浏览量:3065次2020-08-12 20:09:12
-
浏览量:12107次2021-07-13 16:37:15
-
浏览量:7990次2020-12-07 16:50:17
-
浏览量:18606次2021-01-29 19:22:55
-
2023-01-13 11:35:13
-
浏览量:1592次2023-03-29 10:55:15
-
浏览量:197次2023-08-15 22:50:27
-
浏览量:5330次2021-06-29 12:05:47
-
浏览量:174次2023-08-16 18:28:43
-
浏览量:27131次2021-01-29 14:36:29
-
浏览量:150次2023-08-15 18:40:55
-
浏览量:8818次2023-01-11 16:49:09
-
浏览量:1072次2023-07-05 10:16:00
-
浏览量:1150次2023-09-27 14:17:16
-
浏览量:12138次2021-07-23 15:56:25









-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

一休摸鱼

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
