

基于相关性的四种机器学习聚类方法

在这篇文章中,基于20家公司的股票价格时间序列数据。根据股票价格之间的相关性,看一下对这些公司进行分类的四种不同方式。
苹果(AAPL),亚马逊(AMZN),Facebook(META),特斯拉(TSLA),Alphabet(谷歌)(GOOGL),壳牌(SHEL),Suncor能源(SU),埃克森美孚公司(XOM),Lululemon(LULU),沃尔玛(WMT),Carters(CRI)、 Childrens Place (PLCE), TJX Companies (TJX), Victoria's Secret & Co (VSCO), Macy's (M), Wayfair (W), Dollar Tree (DLTR), CVS Caremark (CVS), Walgreen (WBA), Curaleaf Holdings Inc. (CURLF)
我们的DataFrame df_combined,包含上述公司413天的股票价格,没有遗漏数据。
目标
我们的目标是根据相关性对这些公司进行分组,并检查这些分组的有效性。例如,苹果、亚马逊、谷歌和Facebook通常被视为科技股,而Suncor和Exxon被视为石油和天然气股。我们将检查我们是否可以得到这些分类,只使用这些公司的股票价格之间的相关性。
使用相关性来对这些公司进行分类,而不是使用股票价格,如果使用股票价格,具有相似股票价格的公司将被集中在一起。但在这里,我们想根据股票价格的行为来对公司进行分类。实现这一目标的一个简单方法是使用股票价格之间的相关性。
最 佳集群数量
寻找集群的数量是一个自身的问题。有一些方法,如elbow方法,可以用来寻找最 佳的集群数量。然而,在这项工作中,尝试将这些公司分成4个集群。理想情况下,这四个群组必须是科技股、石油和天然气股、零售股和其他股票。
首先获得我们所拥有的数据框架的相关矩阵。
correlation_mat=df_combined.corr()定义一个效用函数来显示集群和属于该集群的公司。
# 用来打印公司名称和它们所分配的集群的实用函数
def print_clusters(df_combined,cluster_labels):
cluster_dict = {}
for i, label in enumerate(cluster_labels):
if label not in cluster_dict:
cluster_dict[label] = []
cluster_dict[label].append(df_combined.columns[i])
# 打印出每个群组中的公司 -- 建议关注@公众号:数据STUDIO 定时推送更多优质内容
for cluster, companies in cluster_dict.items():
print(f"Cluster {cluster}: {', '.join(companies)}")方法1:K-means聚类法
K-means聚类是一种流行的无监督机器学习算法,用于根据特征的相似性将相似的数据点分组。该算法迭代地将每个数据点分配给最近的集群中心点,然后根据新分配的数据点更新中心点,直到收敛。我们可以用这个算法根据相关矩阵对我们的数据进行聚类。
from sklearn.cluster import KMeans
# Perform k-means clustering with four clusters
clustering = KMeans(n_clusters=4, random_state=0).fit(correlation_mat)
# Print the cluster labels
cluster_labels=clustering.labels_
print_clusters(df_combined,cluster_labels)
k-means聚类的结果
正如预期的那样,亚马逊、Facebook、特斯拉和Alphabet被聚集在一起,石油和天然气公司也被聚集在一起。此外,沃尔玛和MACYs也被聚在一起。然而,我们看到一些科技股,如苹果与沃尔玛聚集在一起。
方法2:聚和聚类法Agglomerative Clustering
聚合聚类是一种分层聚类算法,它迭代地合并类似的聚类以形成更大的聚类。该算法从每个对象的单独聚类开始,然后在每一步将两个最相似的聚类合并。
from sklearn.cluster import AgglomerativeClustering
# 进行分层聚类
clustering = AgglomerativeClustering(n_clusters=n_clusters,
affinity='precomputed',
linkage='complete'
).fit(correlation_mat)
# Display the cluster labels
print_clusters(df_combined,clustering.labels_)
分层聚类的结果
这些结果与我们从k-means聚类得到的结果略有不同。我们可以看到一些石油和天然气公司被放在了不同的聚类中。
方法3:亲和传播聚类法 AffinityPropagation
亲和传播聚类是一种聚类算法,不需要事先指定聚类的数量。它的工作原理是在成对的数据点之间发送消息,让数据点自动确定聚类的数量和最 佳聚类分配。亲和传播聚类可以有效地识别数据中的复杂模式,但对于大型数据集来说,计算成本也很高。
from sklearn.cluster import AffinityPropagation
# 用默认参数进行亲和传播聚类
clustering = AffinityPropagation(affinity='precomputed').fit(correlation_mat)
# Display the cluster labels
print_clusters(df_combined,clustering.labels_)
亲和传播聚类的结果
有趣的是,这个方法发现四个聚类是我们数据的最 佳聚类数量。此外,我们可以观察到,石油和天然气公司被聚在一起,一些科技公司也被聚在一起。
方法4:DBSCAN聚类法
DBSCAN是一种基于密度的聚类算法,它将那些紧密排列在一起的点聚在一起。它不需要事先指定聚类的数量,而且可以识别任意形状的聚类。该算法对数据中的离群值和噪声具有鲁棒性,可以自动将它们标记为噪声点。
from sklearn.cluster import DBSCAN
# Removing negative values in correlation matrix
correlation_mat_pro = 1 + correlation_mat
# Perform DBSCAN clustering with eps=0.5 and min_samples=5
clustering = DBSCAN(eps=0.5, min_samples=5, metric='precomputed').fit(correlation_mat_pro)
# Print the cluster labels
print_clusters(df_combined,clustering.labels_)
DBScan聚类的结果
在这里,与基于亲和力的聚类不同,DBScan方法将5个聚类确定为最 佳数量。还可以看出,有些集群只有1或2家公司。
可视化
同时检查上述四种聚类方法的结果,以深入了解它们的性能,可能是有用的。最简单的方法是使用热图,公司在X轴上,聚类在Y轴上。
def plot_cluster_heatmaps(cluster_results, companies):
"""
Plots the heatmaps of clustering for all companies
for different methods side by side.
Args:
- cluster_results: a dictionary of cluster labels for each
clustering method
- companies: a list of company names
- 建议关注@公众号:数据STUDIO 定时推送更多优质内容
"""
# 从字典中提取key和value
methods = list(cluster_results.keys())
labels = list(cluster_results.values())
# 定义每个方法的热图数据
heatmaps = []
for i in range(len(methods)):
heatmap = np.zeros((len(np.unique(labels[i])), len(companies)))
for j in range(len(companies)):
heatmap[labels[i][j], j] = 1
heatmaps.append(heatmap)
# Plot the heatmaps in a 2x2 grid
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 12))
for i in range(len(methods)):
row = i // 2
col = i % 2
sns.heatmap(heatmaps[i], cmap="Blues", annot=True, fmt="g", xticklabels=companies, ax=axs[row, col])
axs[row, col].set_title(methods[i])
plt.tight_layout()
plt.show()
companies=df_combined.columns
plot_cluster_heatmaps(cluster_results, companies)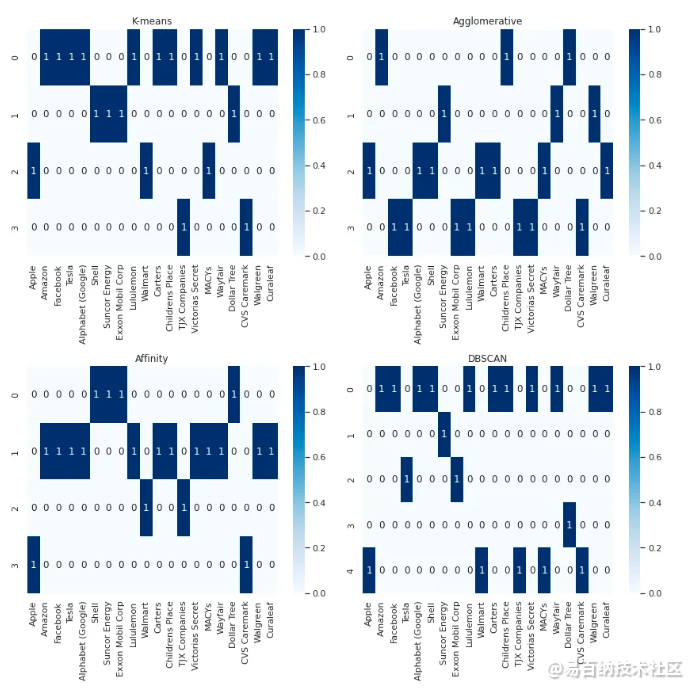
所有四种方法的聚类结果
然而,当试图比较多种聚类算法的结果时,上述的可视化并不是很有帮助。找到一个更好的方法来表示这个图将会很有帮助。
结论
在这篇文章中,我们探讨了四种不同的方法,根据20家公司的股票价格之间的相关性来进行聚类。其目的是以反映这些公司的行为而不是其股票价格的方式对其进行聚类。尝试了K-means聚类、Agglomerative聚类、Affinity Propagation聚类和DBSCAN聚类方法,每种方法都有自己的优点和缺点。结果显示,这四种方法都能以符合其行业或部门的方式对公司进行聚类,而一些方法的计算成本比其他方法更高。基于相关性的聚类方法为基于股票价格的聚类方法提供了一个有用的替代方法,可以根据公司的行为而不是股票价格来聚类。
文章转载自公众号:机器学习算法与Python实战
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:919次2023-07-05 10:16:37
-
浏览量:889次2023-07-24 15:23:06
-
浏览量:5339次2021-07-02 14:29:53
-
浏览量:1000次2023-07-05 10:15:45
-
浏览量:1676次2019-05-25 09:45:04
-
浏览量:1657次2023-01-28 13:55:15
-
浏览量:8201次2021-05-06 12:40:38
-
浏览量:916次2023-11-10 11:30:56
-
2023-01-13 11:35:13
-
浏览量:1316次2023-09-27 11:34:33
-
浏览量:4668次2021-06-30 11:34:00
-
浏览量:5104次2021-04-08 11:23:42
-
浏览量:1455次2023-09-27 10:05:40
-
浏览量:2118次2020-08-21 14:40:54
-
浏览量:6624次2021-06-11 12:41:01
-
浏览量:1278次2023-01-12 17:13:47
-
浏览量:949次2023-08-03 10:52:42
-
浏览量:10213次2021-04-20 15:42:26
-
浏览量:1358次2024-02-02 17:26:56









-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

一休摸鱼

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
