

带有 Django API 的机器学习预测模型

概述
机器学习 (ML) 和数据科学应用的需求量很大。当 ML 算法在已知信息之前提供信息时,对业务的好处是显着的。将用于推理的机器学习算法集成到生产系统中是一个技术障碍。另一方面,ML 算法分两个阶段运行:
训练阶段是使用以前的数据开发机器学习算法的阶段。
ML 方法用于在推理阶段计算对具有不确定结果的新数据的预测。
介绍
该项目旨在使机器学习算法可通过 DJANGO API、RPC 或 WebSockets 访问。这种技术导致创建一个服务器来处理查询并将它们路由到机器学习算法。使用此方法可以满足 ML 生产系统的所有标准。
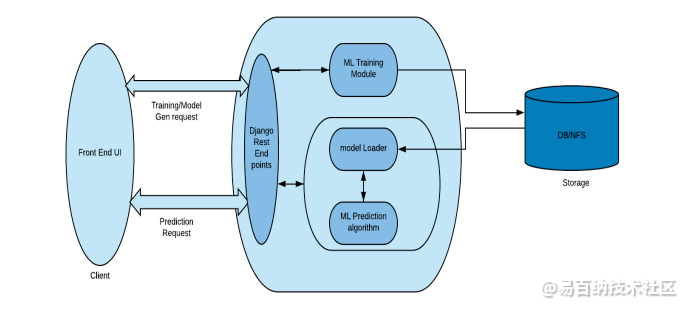
最后一个进展是聘请商业供应商来实施机器学习算法,这可以在内部或云端完成。情况并非总是如此。
涉及的步骤
- 构建 Django 应用程序
- 训练机器学习模型
- 测试 API
构建 Django 应用程序
让我们创建并初始化开发环境。
python3 -m venv env
source env/bin/activate安装所需的软件包:
pip install django djangorestframework sklearn numpy打开命令行并输入注释以创建和复制存储 Django 项目的目录。为此应用程序创建一个目录并将其复制(cd)到该目录中。
mkdir DjangoMLAPI
cd DjangoMLAPI
django-admin startproject api我们已经创建了一个 Django 项目,其中将包含我们正在处理的所有代码。它还将包含数据库配置和应用程序设置。
“项目”对应于我们正在开发的应用程序,而 Django 将项目中的包称为“应用程序”。主要包将是 API。
Start Project API 创建了大量运行我们的项目所需的样板代码。它将类似于左侧的文件树。
外部 /api 文件夹只包含我们项目的所有代码。
我们项目的主要 python 包是内部的 /api。
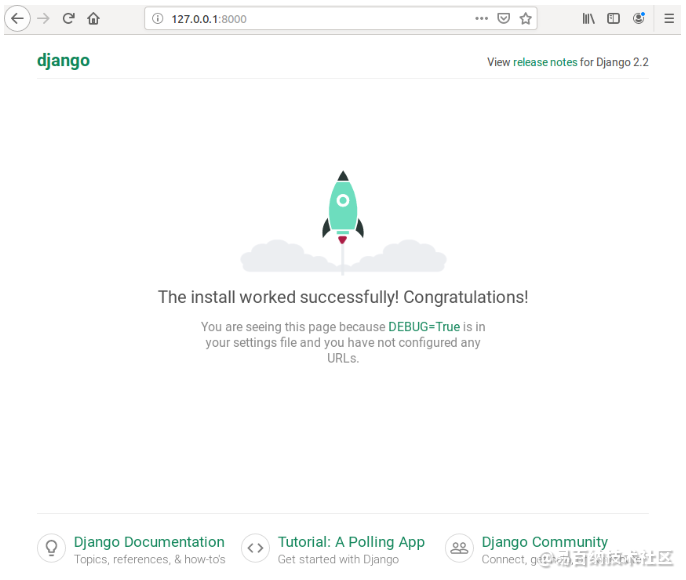
python manage.py runserver如果您在 Web 浏览器中输入 127.0.0.1:8000,您应该会看到默认的 Django 欢迎网页。
之后,我们将在我们的项目中创建一个“应用程序”。这将传播 API 背后的机器学习。我们将命名这个声音预测器。
cd api
python manage.py startapp soundpredictor我们添加了一个名为 /soundpredictor 的文件夹,里面有很多文件。
view.py包含可以在每个请求上运行的代码。因此,我们在方程中添加了矢量化和回归逻辑。
apps.py是我们将在其中指定配置类的文件。这段代码只会执行一次,所以我们最终会把代码放在那里加载我们的模型
让我们将此应用程序添加到 APPS_INSTALLED。打开 /api/api/settings.py 并将“声音预测器”添加到 APPS_INSTALLED。
APPS_INSTALLED = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'predictor'
]在 /soundpredictor 中创建一个名为 /models 的文件夹很重要。将经过训练的模型移动到此目录中。
请注意,在真实的生产环境中,这样我们就不必在每次模型更改时重新部署应用程序。但是,在这种情况下,我们只会在应用程序中包含模型。
我们必须将这些行添加到设置中。此代码将加载模型。
MODELS = os.path.join(BASE_DIR, 'soundpredictor/models')编写在应用程序启动时加载模型的代码。在 /api/soundpredictor/apps.py 中部署代码。创建模型路径并将模型加载到单独的变量中。
from django.apps import AppConfig
from django.conf import settings
import os
import pickle
class soundpredictorConfig(AppConfig):
path = os.path.join(settings.MODELS, 'models.p')
with open(path, 'rb') as pickled:
data = pickle.load(pickled)
regressor = data['regressor']
vectorize = data['vectorize']现在我们需要创建一个视图来鼓励我们的回归逻辑。打开 /api/predictor/views.py 并使用此代码进行更新。
from django.shortcuts import render
from .apps import soundpredictorConfig
from django.http import JsonResponse
from rest_framework.views import APIView
class call_model(APIView):
def get(self,request):
if request.method == 'GET':
sound = request.GET.get('sound')
vector = PredictorConfig.vectorizer.transform([sound])
prediction = soundpredictorConfig.regressor.predict(vector)[0]
response = {'dog': prediction}
return JsonResponse(response)最后一步是将 URL 添加到我们的模型中,以便我们可以访问它们。请将以下代码添加到 /api/api/urls.py 中的 urls.py 文件中:
from django.urls import path
from predictor import viewsurlpatterns = [
path('classify/', views.call_model.as_view())
]from django.conf.urls import url, include
from rest_framework.routers import DefaultRouter
urlpatterns = [
url(r"^api/v1/", include(router.urls)),
]训练机器学习模型
要开始该项目,请打开一个 jupyter notebook。运行命令,
pip3 install jupyter notebook
ipython kernel install --user --name=venv创建一个目录来存储笔记本文件,
mkdir research
cd research
jupyter notebook这种预测分析是训练模型根据它的语气来预测动物是否是鸭子。
因此,我们将使用虚构数据训练模型。这表明它将以与您可能创建的任何其他 sklearn 模型相同的方式工作。
该算法将根据动物发出的声音确定它是否是鸭子。
创建虚构数据后,每个内部列表中的第一个索引是动物的声音,第二个索引是指示动物是否是鸭子的布尔标签。

data = [
['Honk', 1],
['Woof', 0],
['ruff', 0],
['bowwow', 0],
['cackle', 1],
['moo', 0],
['meow', 0],
['clang', 1],
['buzz', 0],
['quack', 0],
['pika', 0]
]下一个任务是将上述数据转换为特征和标签列表。
X = []
y = []
for i in data:
X.append( i[0] )
y.append( i[1] )在我们将特征转换为列表后,拟合向量化器,并转换特征。
from sklearn.feature_extraction.text import CountVectorizer
vectorize = CountVectorizer()
X_vectorized = vectorize.fit_transform(X)我们正处于训练线性回归模型的最后一步,
from sklearn.linear_model import LinearRegression
import numpy as npregressor = LinearRegression()
regressor.fit(X_vectorized, y)我们必须用几个例子来测试它以检查模型是否正常工作,
test_feature = vectorizer.transform(['Honk'])
prediction = regressor.predict(test_feature)
print(prediction)
test_feature = vectorizer.transform(['bowwow'])
prediction = regressor.predict(test_feature)
print(prediction)
test_feature = vectorizer.transform(['meoww'])
prediction = regressor.predict(test_feature)
print(prediction)]#=> [1.]
#=> [0.]
#=> [0.36363636]模型看起来很完美。
Pickle 我们的模型到一个字节流中,以便它可以将它们存储在应用程序中。
import pickle
pick = {
'vectorize': vectorize,
'regressor': regressor
}
pickle.dump( pick, open( 'models' + ".p", "wb" ) )测试 API
我们可以使用以下命令运行服务器:
python manage.py runserver添加几个 curl 请求来测试它。我们可以直接在浏览器地址栏中输入网址。
curl -X GET http://127.0.0.1:8000/classify/?sound=buzz
#=> {"duck": 0.0}
curl -X GET http://127.0.0.1:8000/classify/?sound=quack
#=> {"duck": 1.0}这个模型正在工作!接近 1 的数字表示它是一只鸭子,接近 0 的数字表示它不是一只鸭子。
我们也可以在浏览器中检查这些。在网址:
http://127.0.0.1:8000/classify/?sound=buzz
http://127.0.0.1:8000/classify/?sound=quack
Django API 可以加载和运行经过训练的机器学习模型,并使用 URL 测试应用程序。
下载Python源代码: plot_iris_svc.py
下载Jupyter notebook源代码: plot_iris_svc.ipynb
文章转载自机器学习算法与知识图谱
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1182次2023-03-01 09:36:58
-
浏览量:5371次2021-04-21 17:06:33
-
浏览量:5653次2021-02-21 22:45:39
-
浏览量:11518次2021-02-21 21:57:48
-
浏览量:5492次2021-06-09 14:02:36
-
浏览量:7248次2021-06-08 14:50:34
-
浏览量:197次2023-08-15 22:50:27
-
浏览量:1628次2023-01-05 17:44:00
-
浏览量:174次2023-08-16 18:28:43
-
浏览量:2282次2023-05-18 22:55:16
-
浏览量:1358次2023-03-02 13:55:57
-
浏览量:150次2023-08-15 18:40:55
-
浏览量:1282次2023-01-12 17:08:25
-
浏览量:2176次2023-03-14 09:12:42
-
浏览量:10147次2021-02-23 16:44:17
-
浏览量:5674次2021-06-07 09:28:15
-
浏览量:1358次2024-02-02 17:26:56
-
浏览量:764次2023-09-14 16:30:18
-
浏览量:1544次2023-09-04 16:04:31

tomato
===============













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
tomato

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
