

使用 Pickle 和 Joblib 保存机器学习模型的快速技巧

介绍
保存模型是模型开发领域的关键部分。为了理解它的意思,让我们用一个非常简单的例子来理解它:
假设你正在处理与房租相关的练习问题,给定大量数据点和输入特征。执行EDA、 预处理(可能需要创建额外的特征)并将我们的数据提供给我们的模型,这些步骤是很常见的。
在这种情况下,即使我们使用最简单的线性回归模型(多变量),由于它需要所有输入特征和所有参数,其大小可能会变得巨大,而这些参数将非常耗时,需要一次又一次地重新训练以供使用。
因此,最简单的做法是保存我们的模型,稍后加载它以进行推理或预测。虽然 Keras 模型 API 提供了 [ model.save()] 功能来保存我们的深度学习模型,但仅限于深度学习领域,对于大多数初学者来说,在 ML 中保存他们的模型非常令人困惑。由于估计器具有大量参数,因此最好保存它们。所以在这篇文章中,我们将研究一些小技巧来保存我们的模型
加载数据集并创建我们的模型
我们将使用具有单个特征区域的房价预测数据集(https://drive.google.com/file/d/10uY-Sal9HLTSBun-kNLQcAhUZqP-hx3L/view?usp=sharing)(用于演示目的)。
我们的工作将是预测给定区域的价格。为简单起见,我们将仅使用 4-5 个数据点,我们将使用的模型将是线性回归模型,该模型仅将一条直线拟合到我们的数据集,并根据所有数据点的实际差异计算预测差异的平方
成本函数中的平方确保负值无效
创建模型文件
我们现在将快速分 5 个步骤创建我们的模型文件,我们将保存这些文件以备后用。
1. 我们将首先加载所有必需的依赖项。
# loading dependencies
import pandas as pd
import numpy as np
from sklearn import linear_model2. 现在我们将使用pd.read_csv()函数将数据加载到Pandas数据帧 ( train_df ) 中,并使用**df.head()**方法打印前 5 行。
# loading our data
train_df = pd.read_csv('/content/train.csv')
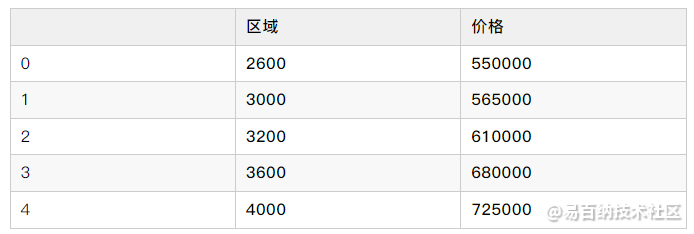
# viewing few files
train_df.head()>>
3. 为了创建我们的模型,我们将首先创建一个模型对象,它实际上是一个线性回归分类器,然后将我们的模型与我们的训练样本和训练标签进行拟合,我们的模型工作将是找到最 佳直线拟合。
# creating the model object
model = linear_model.LinearRegression() # y = mx+b# fitting model with X_train - area, y_train - price
model.fit(train_df[['area']],train_df.price)执行完上面的代码输出会有点像这样
>> LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)4. 我们知道方程中的直线有一个系数和一个截距,所以我们应该检查这些值,因为 sklearn 提供了一些方便的属性。这些可以检查为
# checking coeffiecent - m
model.coef_>> array([135.78767123])
# checking intercept - b
model.intercept_>> 180616.43835616432
5. 最后,为了完整起见,可以测试预测 5000 平方英尺面积房屋价格的模型。
# checking intercept - b
model.intercept_>> array([859554.79452055])
保存模型
现在是时候保存我们创建的模型了。我们将研究保存模型的 2 个快速技巧。另外作为奖励,我将提供有关在何处使用哪种方法的指南。
方法 1 使用 Pickle
你们中的许多人都会熟悉 pickle 模块,pickle 模块允许你使用反序列化从文件中创建上一次程序保存的对象,这意味着简单地 将对象分解为其构成组件。 例如,我们的模型文件属性就像我们看到的那样。
要使用 pickle 保存文件,需要打开一个文件,以某个别名加载它并转储模型的所有信息。这可以使用以下代码实现:
# loading library
import pickle# create an iterator object with write permission - model.pkl
with open('model_pkl', 'wb') as files:
pickle.dump(model, files)完成上述步骤后,可以在目录中看到一个名为model_pkl的文件,打开它会是这样的:
Google 协作中显示的目录
在 model_pkl 文件中
可以使用相同的逻辑将该文件再次加载到模型中,这里我们使用 lr变量来引用模型,然后使用它来预测5000 平方英尺的价格:
# load saved model
with open('model_pkl' , 'rb') as f:
lr = pickle.load(f)# check prediction
lr.predict([[5000]]) # similar>> array([859554.79452055])
好处:
- pickle 模块会跟踪它已经序列化的对象,以便以后对同一对象的引用不会再次序列化,从而缩短执行时间。
- 允许在很短的时间内保存模型。
- 适用于我们使用的参数较少的小型模型。
方法 2 使用 Joblib
Joblib 是模型保存的一种替代方法,它可以对具有大型 NumPy 数组/数据的对象进行操作,作为具有许多参数的后端。
它可以用作单个模块(参阅(https://joblib.readthedocs.io/en/latest/installing.html))或使用 Sci-Kit Learn 库。为简单起见,我们将使用第二种方法。
-> 首先,我们将从sklearn的外部类 导入joblib
# loading dependency
from sklearn.externals import joblib为了保存模型,我们将使用其转储功能将模型保存到model_jlib文件中。
# saving our model # model - model , filename-model_jlib
joblib.dump(model , 'model_jlib')运行上述代码后,将使用文件名创建一个文件,其内容将类似于Pickle 文件。
目录
在 model_jlib 文件中
注意:我们没有使用迭代器,因为模块将数据保存到磁盘而不是字符串名称。但是,它接受类似文件的对象。
为了加载模型,我们将向load函数提供文件路径或文件对象,并将其存储在m_jlib变量中,稍后我们可以使用该变量进行预测。
# opening the file- model_jlib
m_jlib = joblib.load('model_jlib')最后,为了预测,我们可以在m_jlib上调用predict方法并将其传递给值为 5000 的二维数组。
# check prediction
m_jlib.predict([[5000]]) # similar>> array([859554.79452055])
注意预测方法假设你提供二维格式的数据,因此我们使用 [[5000]] 表示 5000 作为二维数组
好处:
- 非常适合具有许多参数的大型模型,并且可以在后端拥有大型 NumPy 数组。
- 只能将文件保存到磁盘而不是字符串。
- 与pickle dump和load的工作原理类似
- 最适合 sklearn 估计器。
结论
由于训练大型模型所涉及的时间复杂性,保存模型正在成为数据科学领域的重要组成部分,在本文中,我试图介绍一些快速保存它们的方法。但是,必须注意的是,该过程基于相同的序列化概念(将数据保存到其组件形式)和反序列化(从序列化块中恢复数据),因此建议从受信任的模型中pickle或joblib来源。
同样为简单起见,我们使用了线性回归模型,但同样可以用于保存不同类型的模型,如逻辑回归、决策树、SVM等等:)
下载Python源代码: plot_iris_svc.py
下载Jupyter notebook源代码: plot_iris_svc.ipynb
文章转载自机器学习算法与知识图谱
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1181次2023-03-01 09:36:58
-
浏览量:1054次2023-08-22 17:38:48
-
浏览量:5370次2021-04-21 17:06:33
-
浏览量:174次2023-08-16 18:28:43
-
浏览量:5653次2021-02-21 22:45:39
-
浏览量:11518次2021-02-21 21:57:48
-
浏览量:1001次2023-09-04 10:30:14
-
浏览量:852次2023-09-04 18:54:46
-
浏览量:1163次2023-09-18 16:40:57
-
浏览量:10146次2021-02-23 16:44:17
-
浏览量:5674次2021-06-07 09:28:15
-
浏览量:1358次2024-02-02 17:26:56
-
浏览量:6244次2021-07-15 10:44:33
-
浏览量:4855次2023-09-04 14:32:32
-
浏览量:764次2023-09-14 16:30:18
-
浏览量:35241次2022-06-11 11:06:24
-
浏览量:10328次2022-06-11 10:47:27
-
浏览量:2174次2023-03-14 09:12:42
-
浏览量:1628次2023-01-05 17:44:00




-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
哈哈哈哈

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
