

用于机器学习和深度学习的集成堆叠

介绍
在这篇博客中,我们将通过理论和实践代码来讨论集成堆叠!
让我们首先讨论什么是集成技术?
集成技术是使用多种学习算法或模型来生成一个最 佳预测模型的方法。生成的模型比单独使用的基础学习器具有更好的性能。集成学习的其他应用还包括选择重要特征、数据融合等。集成技术主要可以分为Bagging、Boosting和Stacking。
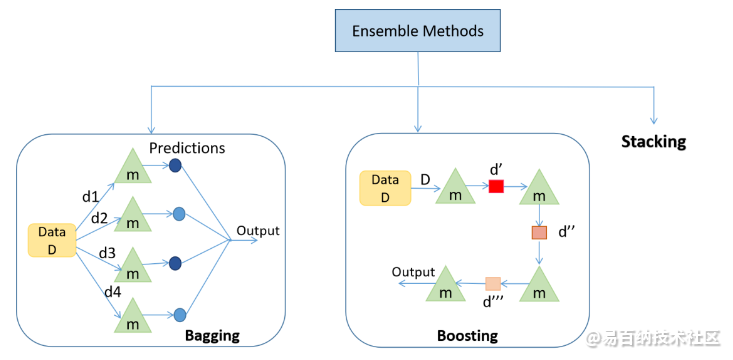
图 1. 表示集成方法的类型
这里,m 代表一个弱学习器;d1, d2, d3, d4 是来自数据 D 的随机样本;d', d”, d”' 是基于先前弱学习器的结果更新的训练数据。
1. Bagging: Bagging主要应用于监督学习问题。它涉及两个步骤,即引导和聚合。Bootstrapping 是一种随机抽样方法,其中使用替换程序从数据中获取样本。
在图 1 中,bagging 的第一步是 bootstrapping,其中随机数据样本被馈送到每个基础学习器。对样本运行基本学习算法以完成该过程。在聚合中,来自基础学习器的输出被组合在一起。目标是提高准确性,同时在很大程度上减少方差。
例如:RandomForest(https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/) ,其中并行采用决策树(基础学习器)的预测。在回归问题中,对这些预测进行平均以给出最终预测,在分类问题中,模式被选为预测类别。
2. Boosting: 这是一种集成方法 ,其中每个预测器从先前的预测器错误中学习,以便在未来做出更好的预测。该技术结合了几个按顺序排列的弱基础学习器(图 1),以便弱学习器从先前弱学习器的错误中学习,以创建更好的预测模型。因此, 通过显着提高模型的可预测性,形成了一个强大的学习器。
例如。XGBoost,AdaBoost。
既然我们已经讨论了集成和两种类型的集成方法,现在是我们讨论 Stacking 的时候了!
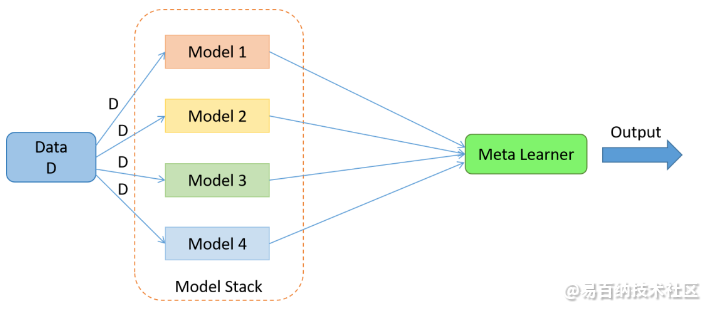
图 2. 堆叠算法。堆栈中弱学习器的数量是可变的
**3. Stacking:**当Bagging和Boosting使用同构弱学习器进行集成时,Stacking 通常考虑异构弱学习器,并行学习它们,并通过训练元学习器将它们组合起来,根据不同弱学习器的预测输出预测。元学习器将预测作为特征输入,目标是数据 D 中的真实值(图 2),它尝试学习如何最好地组合输入预测以做出更好的输出预测。
在平均集合(如随机森林)中,该模型结合了多个训练模型的预测。这种方法的一个限制是,无论模型的性能如何,每个模型对集合预测的贡献都是相同的。另一种方法是加权平均集成,它根据每个集合成员对给出最 佳预测的贡献的信任程度来衡量每个成员的贡献。加权平均集成是对模型平均集成的改进。
这种方法的进一步推广是用线性回归(回归问题)或逻辑回归(分类问题)代替线性加权和,以将子模型的预测与任何学习算法相结合。这种方法称为堆叠。
在堆叠中,算法将子模型的输出作为输入,并尝试学习如何最好地组合输入预测以做出更好的输出预测。
理论讲得够多了。让我们看看实际操作的部分!
机器学习的堆叠
数据集 – Sklearn 乳腺癌数据集(分类)
注 – 以下代码中不包含数据预处理部分。请通过(https://github.com/YashK07/Stacking-Ensembling/blob/main/Stacking%20in%20Machine%20Learning.ipynb) 获取完整代码。
加载你想要堆叠的基础学习算法:
dtc = DecisionTreeClassifier()
rfc = RandomForestClassifier()
knn = KNeighborsClassifier()
xgb = xgboost.XGBClassifier()进行交叉验证并记录分数:
clf = [dtc,rfc,knn,xgb]
for algo in clf:
score = cross_val_score( algo,X,y,cv = 5,scoring = 'accuracy')
print("The accuracy score of {} is:".format(algo),score.mean())执行堆叠和交叉验证:
dtc = DecisionTreeClassifier()
rfc = RandomForestClassifier()
knn = KNeighborsClassifier()
xgb = xgboost.XGBClassifier()
clf = [('dtc',dtc),('rfc',rfc),('knn',knn),('xgb',xgb)] #list of (str, estimator)from sklearn.ensemble import StackingClassifierlr = LogisticRegression()
stack_model = StackingClassifier( estimators = clf,final_estimator = lr)
score = cross_val_score(stack_model,X,y,cv = 5,scoring = 'accuracy')
print("The accuracy score of is:",score.mean())堆叠模型的准确度得分比单独使用的任何其他基础学习算法高 0.969!
深度学习的堆叠
数据集——Churn Modeling 数据集:https://www.kaggle.com/shrutimechlearn/churn-modelling
请浏览数据集以更好地理解以下代码。
注:
- 以下代码中不包含数据预处理部分。请通过(https://github.com/YashK07/Stacking-Ensembling/blob/main/Ensemble_Stacking_in_Neural_Networks.ipynb)获取完整代码;
- Keras 不提供创建深度神经网络堆栈的功能。所以我们创建了一个我们自己的函数;
- Churn Modeling 数据集有 10000 个示例(行)。我将数据以 70:30 的比例拆分为训练和测试。
创建神经网络架构
model1 = Sequential()
model1.add(Dense(50,activation = 'relu',input_dim = 11))
model1.add(Dense(25,activation = 'relu')) model1.add(Dense(1,activation = 'sigmoid')) 
我选择损失函数作为二元交叉熵,优化器作为 adam,F1-score 作为误差度量。由于 F1-score 在 Keras 中不可用,我们自己构建:
def recall_m(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision_m(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
def f1_m(y_true, y_pred):
precision = precision_m(y_true, y_pred)
recall = recall_m(y_true, y_pred)
return 2*((precision*recall)/(precision+recall+K.epsilon()))训练模型并记录性能。我选择了 epochs = 100 :
model1.compile(loss='binary_crossentropy', optimizer='adam', metrics=[f1_m])
history = model1.fit(X_train,y_train,validation_data = (X_test,y_test),epochs = 100)创建 3 种不同的神经网络架构并使用相同的设置对其进行训练:
model2 = Sequential()
model2.add(Dense(25,activation = 'relu',input_dim = 11))
model2.add(Dense(25,activation = 'relu'))
model2.add(Dense(10,activation = 'relu'))
model2.add(Dense(1,activation = 'sigmoid'))
model2.compile(loss='binary_crossentropy', optimizer='adam', metrics=[f1_m])
history1 = model2.fit(X_train,y_train,validation_data = (X_test,y_test),epochs = 100)model3 = Sequential()
model3.add(Dense(50,activation = 'relu',input_dim = 11))
model3.add(Dense(25,activation = 'relu'))
model3.add(Dense(25,activation = 'relu'))
model3.add(Dropout(0.1))
model3.add(Dense(10,activation = 'relu'))
model3.add(Dense(1,activation = 'sigmoid'))
model3.compile(loss='binary_crossentropy', optimizer='adam', metrics=[f1_m])
history3 = model3.fit(X_train,y_train,validation_data = (X_test,y_test),epochs = 100)model4 = Sequential()
model4.add(Dense(50,activation = 'relu',input_dim = 11))
model4.add(Dense(25,activation = 'relu'))
model4.add(Dropout(0.1))
model4.add(Dense(10,activation = 'relu'))
model4.add(Dense(1,activation = 'sigmoid'))
model4.compile(loss='binary_crossentropy', optimizer='adam', metrics=[f1_m])
history4 = model4.fit(X_train,y_train,validation_data = (X_test,y_test),epochs = 100)保存模型
model1.save('model1.h5')model2.save('model2.h5')model3.save('model3.h5')model4.save('model4.h5')加载模型
dependencies = {'f1_m': f1_m }# create a custom function to load modeldef load_all_models(n_models):
all_models = list()
for i in range(n_models):
# Specify the filename
filename = '/content/model' + str(i + 1) + '.h5'
# load the model
model = load_model(filename,custom_objects=dependencies)
# Add a list of all the weaker learners
all_models.append(model)
print('>loaded %s' % filename)
return all_modelsn_members = 4
members = load_all_models(n_members)
print('Loaded %d models' % len(members))执行堆叠 。
我们首先通过向弱学习器(即 4 个神经网络)提供来自测试集的示例并收集预测来训练元学习器。在这种情况下,每个模型将为每个示例输出一个预测('exited': 1 或 'not exited': 0)。
附注:请浏览数据集。因此,测试集中的 3,000 个示例将产生形状为[3000, 1] 的四个数组(因为有 4 个神经网络)。
然后我们通过dstack() NumPy 函数(https://docs.scipy.org/doc/numpy/reference/generated/numpy.dstack.html)将这些数组组合成一个形状为*[3000, 4, 1]*的三维数组,该数组将堆叠每组新的预测。
作为新模型的输入,我们将需要 3,000 个具有一定数量特征的示例。鉴于我们有四个模型,并且每个模型在每个示例中进行 1 次预测,那么我们将为提供给子模型的每个示例提供 4 (1 x 4) 个特征。我们可以将来自子模型的*[3000, 4, 1]形状的预测转换为[3000, 4]*形状的数组,用于使用reshape() NumPy 函数(https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/) 训练元学习器并展平最后的两个维度。使用stacked_dataset() 函数实现此步骤。
# create stacked model input dataset as outputs from the ensemble
def stacked_dataset(members, inputX):
stackX = None
for model in members:
# make prediction
yhat = model.predict(inputX, verbose=0)
# stack predictions into [rows, members, probabilities]
if stackX is None:
stackX = yhat #
else:
stackX = dstack((stackX, yhat))
# flatten predictions to [rows, members x probabilities]
stackX = stackX.reshape((stackX.shape[0], stackX.shape[1]*stackX.shape[2]))
return stackX我们已经创建了数据集来训练元学习器。我们在训练数据上拟合元学习器。
# fit a model based on the outputs from the ensemble members
def fit_stacked_model(members, inputX, inputy):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# fit the meta learner
model = LogisticRegression() #meta learner
model.fit(stackedX, inputy)
return model
model = fit_stacked_model(members, X_test,y_test)做出预测:
# make a prediction with the stacked model
def stacked_prediction(members, model, inputX):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# make a prediction
yhat = model.predict(stackedX)
return yhat# evaluate model on test set -yhat = stacked_prediction(members, model, X_test)
score = f1_m(y_test/1.0, yhat/1.0)
print('Stacked F Score:', score)堆叠模型在测试数据上给出了 0.6007 的 F 分数,高于任何其他单独使用的神经网络!
有了这个,我们可以得出结论,堆叠模型可以提供比单个模型更好的性能。毫无疑问, Stacking Ensembling 是赢得黑客马拉松并提供最先进结果的最受欢迎的方法
下载Python源代码: plot_iris_svc.py
下载Jupyter notebook源代码: plot_iris_svc.ipynb
文章转载自公众号机器学习算法与知识图谱
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:14753次2021-06-15 10:27:34
-
浏览量:7817次2021-06-15 10:28:29
-
浏览量:6186次2021-06-15 11:49:53
-
浏览量:5674次2021-06-07 09:28:15
-
浏览量:5371次2021-04-21 17:06:33
-
浏览量:7037次2021-06-07 09:26:53
-
浏览量:2174次2023-03-14 09:12:42
-
浏览量:920次2023-08-23 14:42:57
-
浏览量:6448次2021-07-26 17:43:04
-
浏览量:5404次2021-07-26 11:25:51
-
浏览量:10165次2021-05-24 15:12:00
-
浏览量:7151次2021-05-24 15:13:24
-
浏览量:9727次2021-07-12 11:01:47
-
浏览量:6623次2021-06-11 12:41:01
-
浏览量:1657次2023-01-28 13:55:15
-
浏览量:4860次2021-05-18 15:15:50
-
浏览量:5324次2021-07-26 11:28:05
-
浏览量:6281次2021-07-09 11:16:51
-
浏览量:5937次2021-06-17 11:39:26









-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

Ocean

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
