

Keras 回归—King County House 数据集


在本教程中,我将通过探索数字房屋数据集来构建回归模型,以预测金县地区的房屋价格。我使用 TensorFlow 和 Keras 来构建和评估模型。你可以看到一个简短的探索性数据分析 (EDA) 过程。
首先,我们将从导入必要的库开始
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns接下来,我们将在我们的 Python 环境中加载我们的数据集
df = pd.read_csv('kc_house_data.csv')数据清洗
这是我们数据集的列;
df.columns
Index(['id', 'date', 'price', 'bedrooms', 'bathrooms', 'sqft_living',
'sqft_lot', 'floors', 'waterfront', 'view', 'condition', 'grade',
'sqft_above', 'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode',
'lat', 'long', 'sqft_living15', 'sqft_lot15'],
dtype='object')很明显,“id”和“date”列是不相关的,我们可以很容易地将它们从这个特定示例的数据集中删除。
你可能还会注意到,“zipcode”列是代表金县邮政编码的数值集合。由于“zipcode”是一个数值,如果我们在没有进行必要的特征工程的情况下对其进行训练,模型将假定它是连续变量。
因此,这种假设会降低标签预测的准确性(标签在本例中为“price”列)。让我们使用带有两个关键字参数的 .drop() 方法——要删除的列列表和轴。
df = df.drop(['id', 'date', 'zipcode'], axis=1) #axis=1 means column axis我们还可以检查我们的数据集是否包含任何空值,因此我们可以考虑几种方法来用相关值替换它们。
df.isnull().sum() #Total number of null values
Output:
price 0
bedrooms 0
bathrooms 0
sqft_living 0
sqft_lot 0
floors 0
waterfront 0
view 0
condition 0
grade 0
sqft_above 0
sqft_basement 0
yr_built 0
yr_renovated 0
zipcode 0
lat 0
long 0
sqft_living15 0
sqft_lot15 0
dtype: int64简要探索性数据分析 (EDA)
有多种方法可以使用特定技术开始分析数据集。你可以从观察统计指标和绘制直方图、箱线图、计数图等开始。
df.describe() #Will give you mean, std, min and max values and etc.可视化此数据集
让我们从数据集中挑选一些变量并绘制它们的直方图。我们可以单独绘制每个变量的直方图,也可以使用此方法来节省一些时间并编写更好的代码。在这个例子中,我将说明如何通过编写一个函数来可视化你的数据,来扩展你的工具箱。
例如,我可以从这个数据集‘bedrooms’, ’bathrooms’, ’sqft_living’, ’sqft_lot’,’floors’中选择数值,然后通过将它们放入列表中来简单地可视化所有这些值。
def plotHistogram(variable):
"""
Input: Variable/Colum name
Output: Histogram
"""
plt.figure(figsize=(10,5))
plt.hist(df[variable], bins=85, color="blue")
plt.xlabel(variable)
plt.ylabel("Frequency")
plt.title(f"Data Frequency - {variable}")
plt.show()如你所见,函数 plotHistogram 接受一个名为 variable 的参数,创建一个图形并一一设置所有属性。我们可以很容易地调用这个函数,这样输出将是具有相应变量的不同直方图。
numerical_variables = ['bedrooms','bathrooms','sqft_living','sqft_lot','floors']
plot_ = [plotHistogram(i) for i in numerical_variables]这是一个非常实用的示例,通过编写可重用函数来可视化多个直方图。
你可能已经猜到这段代码的输出是几个带有相应变量的直方图。我们可以继续进行进一步的探索性数据分析,但这只是一个回归教程。
拆分标签和特征
X = df.drop('price', axis=1)
y = df['price'].values
"""
Since X represents features, dropping the label column
will provide remaining features.
Similarly, picking the price column will provide the label.
"""进行训练测试拆分;
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=101)我们将在训练测试拆分后立即执行特征缩放。这样我们将只拟合训练集,以防止数据从测试集中泄漏。
从技术上讲,我们可以使用我们希望的任何缩放器(例如 StandardScaler),但在这种情况下,我们可以使用简单的 MinMax 缩放器。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
#Change the definition of the training set as a scaled version.
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)请注意,我们对测试集应用了相同的过程,但在缩放测试集时,我们使用的是单个 .transform() 方法而不是 fit_transform()。我们不拟合我们的测试集,因为我们不想假设有关测试集的先验信息。
现在我们已经应用了必要的拆分和预处理步骤,让我们构建模型。
构建模型
你需要在环境中同时安装 TensorFlow 和 Keras。在创建 Sequential 模型时,请记住,层中包含的神经元数量将基于实际的特征数量。
X_train.shape #Output: (15117, 19)请注意,所有四层上的激活函数都是相同的(ReLU)。现在我们已经构建了一个深度神经网络,我们只需要添加只有一个神经元的最后一层——包含预测的输出层。
from tensorflow.keras import Sequential
from tensorflow.keras.layer import Dense
model = Sequential()
model.add(Dense(19, activation='relu'))
model.add(Dense(19, activation='relu'))
model.add(Dense(19, activation='relu'))
model.add(Dense(19, activation='relu'))
model.add(Dense(1))
model.compile(optimize='adam', loss='mse')让我们看一下这段代码的模型编译部分。你可能会注意到我们使用 Adam 优化器和均方误差作为损失函数。
- 很多模型使用 adam 作为默认优化器有几个原因。它通常优于任何其他优化算法,具有更快的计算时间并且需要更少的参数进行调整。
- 均方误差是衡量统计模型误差量的最合适方法。它用作评估大多数回归算法性能的默认指标。
训练模型
model.fit(x=X_train, y=y_train, validation_data=(X_test, y_test),
batch_size=128, epochs=400)由于我们正在处理一个相对较大的数据集,因此我们需要分批训练模型。
批量大小通常设置为 2 的幂(例如 64、128、256),批量大小越小,训练时间越长。大多数时候,这种相关性具有防止过度拟合的优势,因为你不会一次训练整个训练集。
最后,我选择了一个任意数量的 epoch。稍后将详细介绍提前停止机制。
评估
为了查看我们是否对模型的训练数据过度拟合,我们必须找出损失,以便我们可以将它们与验证损失进行比较。
loss = pd.DataFrame(model.history.history)我们可以通过比较训练损失和验证数据损失来确定我们是否过度拟合训练数据。让我们绘制损失和val_loss变量。
loss.plot()这是绘制的图:
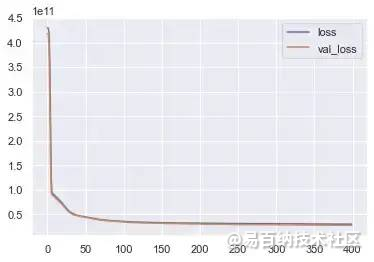
损失与 val_loss
我们可以清楚地看到,在一定批次之后,这两种损失都出现了急剧下降,但保持稳定。这是一个强有力的指标,表明我们可以继续训练,而不会过度拟合我们的训练集。
如果我们看到 val_loss 在某个批次后出现某种增加的趋势,则意味着我们对训练数据过度拟合。
评估
我将使用一些评估指标来比较原始值和预测。
predictions = model.predict(X_test)
predictions #list of predictions
mean_squared_error(y_test, predictions) #using mse compare y_test and predictions
#Output: 27452360549.322517由于很难理解输出,我们可以使用平均绝对误差来找出预测的平均绝对误差。
mean_absolute_error(y_test, predictions)
#Output: 102609.94870394483文章转载自公众号:机器学习算法与知识图谱
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6193次2021-04-14 16:24:29
-
浏览量:1278次2023-01-12 17:13:47
-
浏览量:1152次2023-09-07 16:22:49
-
浏览量:2408次2023-04-14 10:12:00
-
浏览量:1593次2023-03-29 10:55:15
-
2023-01-13 11:35:13
-
浏览量:3791次2023-11-25 17:47:33
-
浏览量:7164次2024-02-05 10:11:42
-
浏览量:1302次2023-06-03 16:08:03
-
浏览量:6551次2021-06-07 11:48:50
-
浏览量:6080次2021-08-12 14:06:09
-
浏览量:1292次2023-05-13 21:35:31
-
浏览量:123次2023-08-23 08:46:26
-
浏览量:10213次2021-04-20 15:42:26
-
2023-01-13 11:33:00
-
浏览量:1803次2023-02-01 09:16:22
-
浏览量:7037次2021-06-07 09:26:53
-
浏览量:16736次2021-07-16 12:56:10
-
浏览量:7060次2021-04-12 12:54:06






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
Mary

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
