

DatRet:结构化表格数据的 Tensorflow 实现

用于表格数据的深度神经网络架构的简单实现,具有可调的层生成和神经元数量的逐层增加。使用类似的经典机器学习方法。
本文讨论了使用这个库的原因,并将 DatRetClassifier 和 DatRetRegressor 的预测准确性与经典机器学习方法进行比较。
介绍
为了预测表格数据,最常用的是经典的机器学习方法。最常在 scikit-learn 中实现。
该库的优点之一是易于使用。我们准备数据,进行拟合和预测,完成。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X, y)
print(clf.predict([[0, 0, 0, 0]]))神经网络的使用,特别是 Tensorflow 或 PyTorch 库,涉及构建神经网络模型的架构,然后进行训练和预测。需要较高的入门门槛。
许多现成的神经网络架构已经实现用于处理图像、文本和声音。对表格数据的处理不多——TabNet示例(https://github.com/dreamquark-ai/tabnet)
创建 DatRet 的主要目标是降低使用神经网络的入门门槛。实施训练和数据预测,与经典方法一样,例如RandomForestClassifier 或 CatBoostClassifier。
为此,我根据第一个全连接层中选定的神经元数量,创建了一个自动生成的神经网络架构。第二个目标是尝试在预测结构化表格数据的准确性方面接近经典方法。
该模型分为三个类:
- DatRetClassifier用于分类任务。
- DatRetRegressor用于回归问题
- DatRetMultilabelClassifier用于“多标签”分类。
优点
- 简单易用。
自动生成神经网络架构
- 快速调整模型参数
- 支持 GPU
- 预测精度高
- 支持多标签分类
从哪里获取?
源代码目前托管在 GitHub 上:https://github.com/AbdualimovTP/datret
最新发布版本的二进制安装程序可在Python 包索引 (PyPI)获得:https://pypi.org/project/datret
# PyPI
pip install datret依赖关系
- Tensorflow:一个主要用于深度学习应用的开源库
- https://www.tensorflow.org/
- NumPy:添加对大型多维数组、矩阵和高级数学函数的支持以对这些数组进行操作
- https://www.numpy.org/
- Pandas 文档:pandas 1.5.2 文档:
- http://pandas.pydata.org/pandas-docs/stable/
- Scikit-Learn:Python 中的机器学习
- https://scikit-learn.org/stable/
快速开始
模型的训练和预测是在 scikit-learn 中实现的。准备你的测试和训练集并运行拟合。支持神经网络的自动数据规范化。
注意!在使用模型之前不要忘记安装依赖项。你需要安装 Tensorflow、Numpy、Pandas 和 Scikit-Learn。
注意!无需对预测特征进行 one-hot 编码。该模型将自动执行。
# load library
from datret.datret import DatRetClassifier, DatRetRegressor, DatRetMultilabelClassifier
# prepare train, test split. As in sklearn.
# for example
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=i)
# Call the regressor or classifier and train the model.
DR = DatRetClassifier() # DatRetRegressor works on the same principle
DR.fit(X_train, y_train)
# predict the actual label (or class) over a new set of data.
DR_predict = DR.predict(X_test)
# predict the class probabilities for each data point.
DR_predict_proba = DR.predict_proba(X_test) # Missing in DatRetRegressor, DatRetMultilabelClassifier自定义模型选项
参数:
- epoch: int, default = 30. 训练模型的时期数。
- optimizer:字符串(优化器名称)或优化器实例。默认 =
Adam(learning_rate=0.001)。在 DatRetRegressor 上,默认学习率 = 0.01。内置 tensorflow optimizer 类。 - 参考:https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/legacy/
- loss:损失函数。可能是一个字符串(损失函数的名称)。默认为 DatRetClassifier =
CategoricalCrossentropy(),DatRetRegressor =MeanSquaredError()。内置损失函数。 - 参考:https://www.tensorflow.org/api_docs/python/tf/keras/losses
- verbose: 'auto', 0, 1, or 2, default=0. Verbosity 模式。0 = silent, 1 = progress bar, 2 = one line per epoch.在大多数情况下,'auto' 默认为 1,但在与 ParameterServerStrategy=0 一起使用时为 2。
- number_neurons: int, default = 500. 第一个全连接层的层数。随后的层是用一半的神经元自动生成的。
- validation_split:在 0 和 1 之间浮动,默认值 = 0。要用作验证数据的训练数据的分数。该模型将分离这部分训练数据,不会对其进行训练,并将在每个时期结束时评估该数据的损失和任何模型指标。
- batch_size:整数,默认值=1。每次梯度更新的样本数。Steps_per_epoch 自动计算,
X_train.shape[0] // batch_size - shuffle: True 或 False,默认值 = True。当x是生成器或 tf.data.Dataset 的对象时,将忽略此参数。'batch' 是处理 HDF5 数据限制的特殊选项;它以批量大小的块进行洗牌。
- callback:
[], 默认值 =[EarlyStopping(monitor='loss', mode='auto', patience=7, verbose=1), ReduceLROnPlateau(monitor='loss', factor=0.2, patience=3, min_lr=0.00001, verbose=1)]。在模型训练期间的某些点调用的实用程序。 - 参考:https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/
可调fit方法参数
参数:
- normalize: True 或 False,默认为 True。输入数据的自动归一化。使用 MinMaxScaler。
例子:
# load library
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, Nadam
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.losses import CategoricalCrossentropy, MeanSquaredError, BinaryCrossentropy
from datret.datret import DatRetClassifier, DatRetRegressor, DatRetMultilabelClassifier
# prepare train, test split. As in sklearn.
# for example
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=i)
# Call the regressor or classifier and train the model.
DR = DatRetClassifier(epoch=50,
optimizer=Nadam(learning_rate=0.001),
loss=BinaryCrossentropy(),
verbose=1,
number_neurons=1000,
validation_split = 0.1,
batch_size=100,
shuffle=True,
callback=[])
DR.fit(X_train, y_train, normalize=True)
# predict the actual label (or class) over a new set of data.
DR_predict = DR.predict(X_test)
# predict the class probabilities for each data point.
DR_predict_proba = DR.predict_proba(X_test)模型架构
例如,当使用number_neurons = 500输入神经元和 2 个可预测类时,模型将自动具有此架构。
Model: "DatRet with number_neurons = 500"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, X_train.shape[0)] 0
dense (Dense) (None, 500) 150500
dense_1 (Dense) (None, 250) 125250
dense_2 (Dense) (None, 125) 31375
dense_3 (Dense) (None, 62) 7812
dense_4 (Dense) (None, 31) 1953
dense_5 (Dense) (None, 15) 480
dense_6 (Dense) (None, 7) 112
dense_7 (Dense) (None, 3) 24
dense_8 (Dense) (None, 2) 8
(2 predictable classes)
=================================================================
Total params: 317,514
Trainable params: 317,514
Non-trainable params: 0精度与经典机器学习方法的比较
- DatRetClassifier
为了评估分类器的准确性,我们将使用 Pima Indians Diabetes Database(https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database)。
可比较的指标RocAucScore。我们将“开箱即用”地比较 DatRet 与 RandomForest 和 CatBoost。
for i in [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]:
X_train, X_test, y_train, y_test = train_test_split(data.drop(["Outcome"], axis=1), data["Outcome"],
random_state=10, test_size=i)
#RandomForest
RF = RandomForestClassifier(random_state=0)
RF.fit(X_train, y_train)
RF_pred = RF.predict_proba(X_test)
dataFrameRocAuc.loc['RandomForest'][f'{int(i*100)}%'] = np.round(roc_auc_score(y_test, RF_pred[:,1]), 2)
#Catboost
CB = CatBoostClassifier(random_state=0, verbose=0)
CB.fit(X_train, y_train)
CB_pred = CB.predict_proba(X_test)
dataFrameRocAuc.loc['CatBoost'][f'{int(i*100)}%'] = np.round(roc_auc_score(y_test, CB_pred[:,1]), 2)
#DatRet
DR = DatRetClassifier(optimizer=Adam(learning_rate=0.001))
DR.fit(X_train, y_train)
DR_pred = DR.predict_proba(X_test)
dataFrameRocAuc.loc['DatRet'][f'{int(i*100)}%'] = np.round(roc_auc_score(y_test, DR_pred[:,1]), 2)
10% 20% 30% 40% 50% 60%
RandomForest 0.79 0.81 0.81 0.79 0.82 0.82
CatBoost 0.78 0.82 0.82 0.8 0.81 0.82
DatRet 0.79 0.84 0.82 0.81 0.84 0.81- DatRetRegressor
为了评估回归器的准确性,我们将使用医疗费用个人数据集 (https://www.kaggle.com/datasets/mirichoi0218/insurance)。
可比较的度量标准均方根误差。我们将“开箱即用”地比较 DatRet 与 RandomForest 和 CatBoost。
for i in [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]:
X_train, X_test, y_train, y_test = train_test_split(data.drop(["charges"], axis=1), data["charges"],
random_state=10, test_size=i)
#RandomForest
RF = RandomForestRegressor(random_state=0)
RF.fit(X_train, y_train)
RF_pred = RF.predict(X_test)
dataFrameRMSE.loc['RandomForest'][f'{int(i*100)}%'] = np.round(mean_squared_error(y_test, RF_pred, squared=False), 2)
#Catboost
CB = CatBoostRegressor(random_state=0, verbose=0)
CB.fit(X_train, y_train)
CB_pred = CB.predict(X_test)
dataFrameRMSE.loc['CatBoost'][f'{int(i*100)}%'] = np.round(mean_squared_error(y_test, CB_pred, squared=False), 2)
#DatRet
DR = DatRetRegressor(optimizer=Adam(learning_rate=0.01))
DR.fit(X_train, y_train)
DR_pred = DR.predict(X_test)
dataFrameRMSE.loc['DatRet'][f'{int(i*100)}%'] = np.round(mean_squared_error(y_test, DR_pred, squared=False), 2)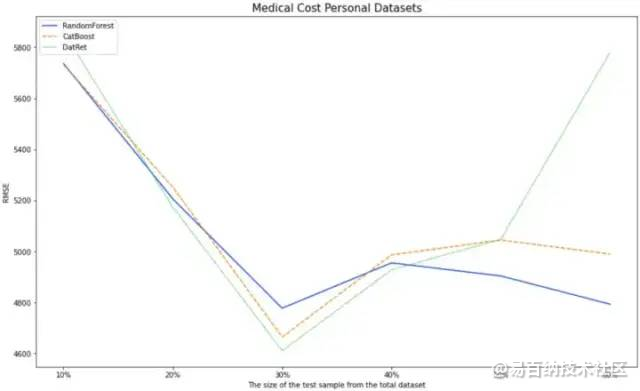
10% 20% 30% 40% 50% 60%
RandomForest 5736 5295 4777 4956 4904 4793
CatBoost 5732 5251 4664 4986 5044 4989
DatRet 5860 5173 4610 4927 5047 5780开箱即用模型的结果不错。
在对测试样本总数据集的 10%、20%、30%、40%、50% 进行分类的任务中,DatRet表现出了最好的结果。
在测试样本总数据集的 20%、30%、40% 的回归问题中,DatRet给出了最好的准确率。
未来,我计划在其他数据集上评估模型的准确性。我也看到了提高预测质量的机会。我计划在下一个版本的库中实现。
文章转载自公众号:机器学习算法与知识图谱
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4689次2021-05-26 15:42:50
-
浏览量:1603次2022-12-06 14:45:10
-
浏览量:3248次2022-05-26 16:24:43
-
浏览量:2685次2019-09-18 22:17:27
-
浏览量:5681次2021-05-21 17:03:03
-
浏览量:898次2023-10-11 15:32:30
-
浏览量:2919次2020-07-09 13:39:17
-
浏览量:19885次2020-11-12 21:39:29
-
浏览量:1549次2024-02-06 11:56:53
-
浏览量:1802次2023-02-01 09:16:22
-
浏览量:5959次2021-04-06 17:40:39
-
浏览量:8585次2020-12-12 17:55:00
-
浏览量:8814次2020-12-12 17:47:04
-
浏览量:1259次2023-01-12 17:08:47
-
浏览量:4633次2021-09-08 09:30:45
-
浏览量:3234次2020-10-26 10:36:20
-
浏览量:4179次2024-02-20 13:54:36
-
浏览量:1261次2023-09-06 17:53:04
-
2023-01-12 11:47:40










-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
Debug

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
