

yolov8训练自己的数据集,超详细讲解,技术心得

文章目录
一、准备学习环境
笔记本电脑系统是:Windows10 YOLO系列最新版本的YOLOv8已经发布了,详细介绍可以参考我前面写的博客,目前ultralytics已经发布了部分代码以及说明,可以在github上下载YOLOv8代码,代码文件夹中会有requirements.txt文件,里面描述了所需要的安装包。
本文最终安装的pytorch版本是1.8.1,torchvision版本是0.9.1,python是3.7.10,其他的依赖库按照requirements.txt文件安装即可。
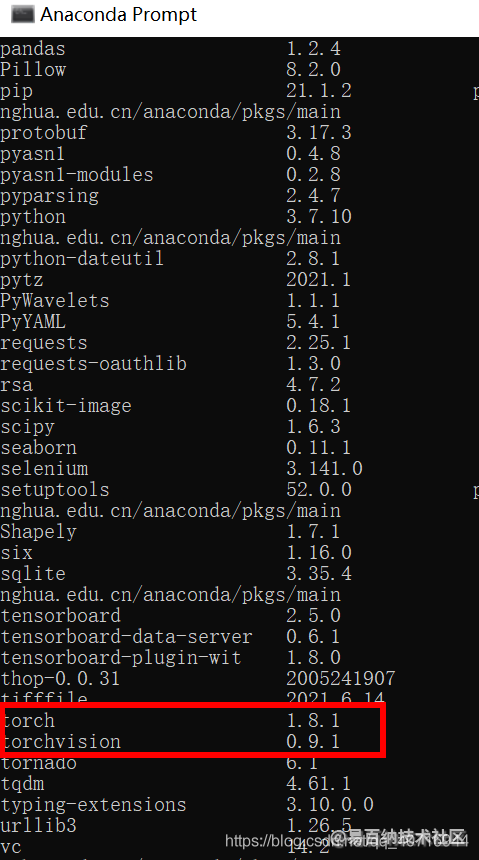
然后还需要安装ultralytics,目前YOLOv8核心代码都封装在这个依赖包里面,可通过以下命令安装
pip install ultralytics
二、 准备自己的数据集
本人在训练YOLOv8时,选择的数据格式是VOC,因此下面将介绍如何将自己的数据集转换成可以直接让YOLOv8进行使用。
1、创建数据集
我的数据集都在保存在mydata文件夹(名字可以自定义),目录结构如下,将之前labelImg标注好的xml文件和图片放到对应目录下
mydata
…images # 存放图片
…xml # 存放图片对应的xml文件
…dataSet #之后会在Main文件夹内自动生成train.txt,val.txt,test.txt和trainval.txt四个文件,存放训练集、验证集、测试集图片的名字(无后缀.jpg)
示例如下:
mydata文件夹下内容如下:

image为VOC数据集格式中的JPEGImages,内容如下:
xml文件夹下面为.xml文件(标注工具采用labelImage),内容如下:
dataSet 文件夹下面存放训练集、验证集、测试集的划分,通过脚本生成,可以创建一个split_train_val.py文件,代码内容如下:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='xml', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='dataSet', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()运行代码后,在dataSet 文件夹下生成下面几个txt文档:

三个txt文件里面的内容如下:
2、转换数据格式
接下来准备labels,把数据集格式转换成yolo_txt格式,即将每个xml标注提取bbox信息为txt格式,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。格式如下:

创建voc_label.py文件,将训练集、验证集、测试集生成label标签(训练中要用到),同时将数据集路径导入txt文件中,代码内容如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["a", "b"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('data/mydata/xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('data/mydata/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/mydata/labels/'):
os.makedirs('data/mydata/labels/')
image_ids = open('data/mydata/dataSet/%s.txt' % (image_set)).read().strip().split()
list_file = open('paper_data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/mydata/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()3、配置文件
1)数据集的配置
在mydata文件夹下新建一个mydata.yaml文件(可以自定义命名),用来存放训练集和验证集的划分文件(train.txt和val.txt),这两个文件是通过运行voc_label.py代码生成的,然后是目标的类别数目和具体类别列表,mydata.yaml内容如下:

2) 选择一个你需要的模型
在ultralytics/models/v8/目录下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov8x.yaml,只用修改一个参数,把nc改成自己的类别数,需要取整(可选) 如下:
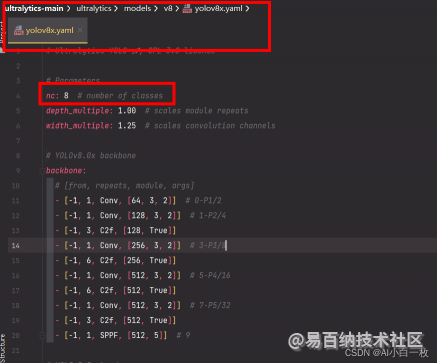
至此,自定义数据集已创建完毕,接下来就是训练模型了。
三、模型训练
1、下载预训练模型
2、训练
接下来就可以开始训练模型了,命令如下:
yolo task=detect mode=train model=yolov8x.yaml data=mydata.yaml epochs=1000 batch=16
以上参数解释如下:
task:选择任务类型,可选['detect', 'segment', 'classify', 'init']
mode: 选择是训练、验证还是预测的任务蕾西 可选['train', 'val', 'predict']
model: 选择yolov8不同的模型配置文件,可选yolov8s.yaml、yolov8m.yaml、yolov8l.yaml、yolov8x.yaml
data: 选择生成的数据集配置文件
epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。 batch:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
训练过程如下所示:

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3788次2023-11-25 17:47:33
-
2024-12-10 10:52:33
-
浏览量:3513次2023-12-19 17:25:07
-
浏览量:4175次2024-02-20 13:54:36
-
浏览量:3334次2024-02-28 16:15:25
-
2024-12-10 11:13:53
-
浏览量:2408次2023-04-14 10:12:00
-
浏览量:4862次2024-03-05 15:05:36
-
2024-12-10 10:34:18
-
浏览量:1806次2023-12-19 17:38:07
-
浏览量:7157次2024-02-05 10:11:42
-
浏览量:4455次2024-02-02 18:15:06
-
浏览量:2307次2023-12-14 17:15:07
-
2024-12-10 11:25:33
-
浏览量:4116次2023-12-16 11:15:45
-
浏览量:6135次2024-02-28 15:36:09
-
浏览量:3813次2024-11-13 14:14:36
-
浏览量:8331次2024-02-02 17:13:35
-
浏览量:1639次2025-02-26 21:18:20

四叶草~
元宇宙(Metaverse)













- AscendCL快速入门——模型推理篇(中)
- 雷达系统可以识别和跟踪房间内的人和物体
- 使用Stable Diffusion图像修复来生成自己的目标检测数据集
- 斯坦福大学研究人员提出人工智能框架来实现和验证复杂的算法
- HiEuler-Pico-OpenEuler Yolov8模型训练和转换——onnx模型转换(四)
- win10环境实现yolov5 TensorRT加速试验(环境配置+训练+推理)
- YOLOv5在SD3403上的部署(包含模型训练,模型转换,SDK部署)
- 海思NNIE Hi3559量化部署Mobilefacenet与RetinaFace
- YOLOv8 AS-One:目标检测AS-One 来了!(YOLO就是名副其实的卷王之王)
- Python人工智能:基于sklearn的K-means聚类算法的详细总结
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
四叶草~

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
