

一种高效的文本到音频AI

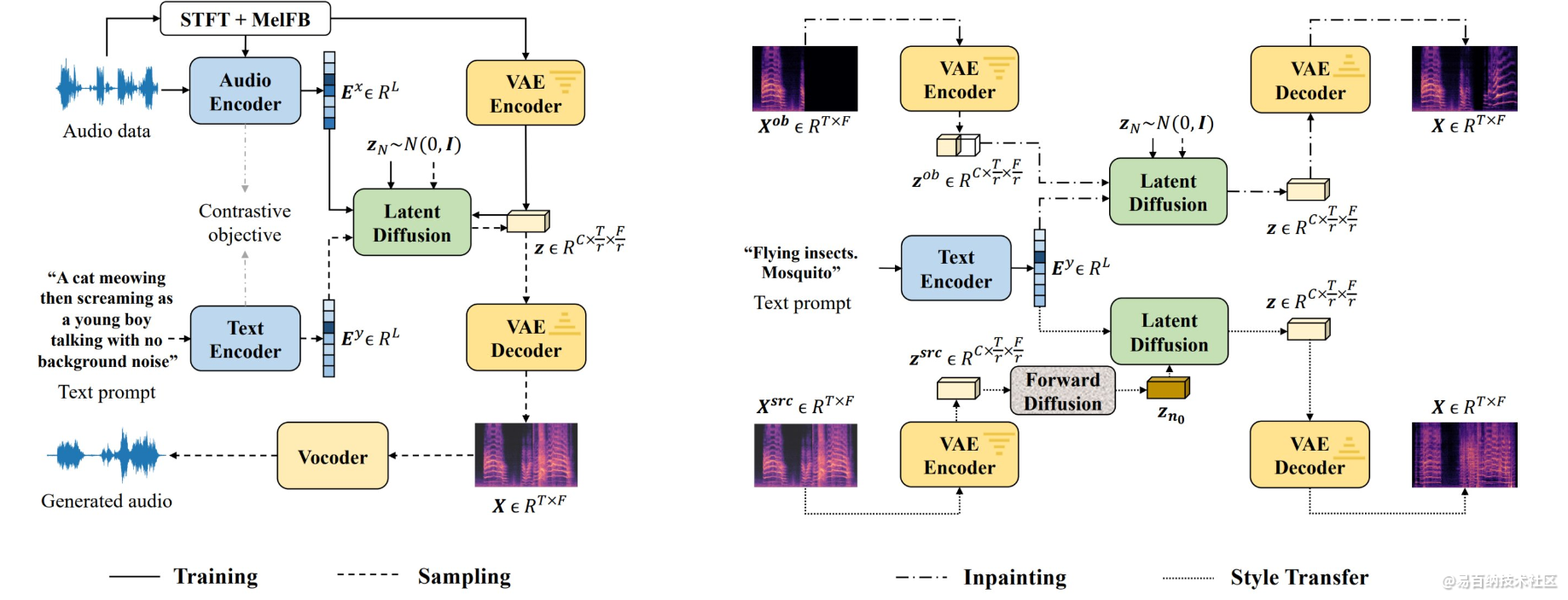
用于文本到音频生成(左)和文本引导音频操作(右)的 AudioLDM 设计概述。在训练过程中,潜在扩散模型(LDM)以音频嵌入为条件,并在VAE学习的连续空间中进行训练。采样过程使用文本嵌入作为条件。给定预训练LDM,零镜头音频修复和风格迁移在相反的过程中实现。前向扩散块表示用高斯噪声破坏数据的过程
Surrey大学的研究人员表示,生成式人工智能(AI)系统将激发音乐行业及其他行业的创造力,他们邀请公众测试他们的新文本转音频模型。
AudioLDM是来自Surrey的一个新的基于人工智能的系统,它允许用户提交文本提示,然后用于生成相应的音频片段。与当前的人工智能系统相比,该系统可以在不影响音质或用户操作剪辑能力的情况下,使用更少的计算能力来处理提示和传递剪辑。
这样的系统可以被声音设计师用于各种应用,如电影制作、数字艺术、虚拟现实、元世界,以及视障人士的数字助手。
Surrey大学的项目负责人Haohe Liu表示:“生成式人工智能有潜力改变每个领域,包括音乐和声音创作。”
“通过AudioLDM,我们表明任何人都可以在几秒钟内创建高质量和独特的样本,只需很少的计算能力。虽然人们对这项技术有一些合理的担忧,但毫无疑问,人工智能将为这些创意行业的许多人打开大门,并激发新想法的爆发。”
Surrey的开源模型是用一种叫做对比语言音频预训练(CLAP)的方法以半监督的方式构建的。使用CLAP方法,AudioLDM可以在大量不同的音频数据上进行训练,无需文本标记,显著提高模型容量。
Surrey大学信号处理和机器学习教授Wenwu Wang说:“AudioLDM的特别之处在于,它不仅可以根据文本提示创建声音片段,而且可以根据相同的文本创建新的声音,而不需要重新训练。”
“这节省了时间和资源,因为它不需要额外的培训。随着生成式人工智能成为我们日常生活的一部分,我们开始思考运行这些技术的计算机所需的能源是很重要的。AudioLDM是朝着正确方向迈出的一步。”
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2042次2020-04-07 10:24:37
-
浏览量:1355次2023-02-14 10:01:43
-
浏览量:1249次2023-02-11 08:54:30
-
浏览量:659次2024-01-30 11:09:07
-
2023-01-12 14:55:31
-
2022-12-26 10:26:11
-
浏览量:1744次2020-03-19 09:24:50
-
浏览量:1807次2020-02-28 09:50:55
-
2023-08-10 09:40:45
-
浏览量:829次2024-02-04 09:47:59
-
浏览量:1006次2023-02-25 09:47:12
-
浏览量:2342次2020-03-18 09:22:40
-
浏览量:980次2023-01-12 15:13:42
-
浏览量:642次2023-11-10 11:30:56
-
浏览量:2958次2018-03-27 16:00:16
-
浏览量:1331次2024-01-12 13:47:40
-
浏览量:1048次2023-02-21 17:24:55
-
浏览量:870次2023-03-14 10:09:41
-
浏览量:3366次2019-11-18 11:15:10






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
艾

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
