

在拥挤环境中改善机器人导航的新方法

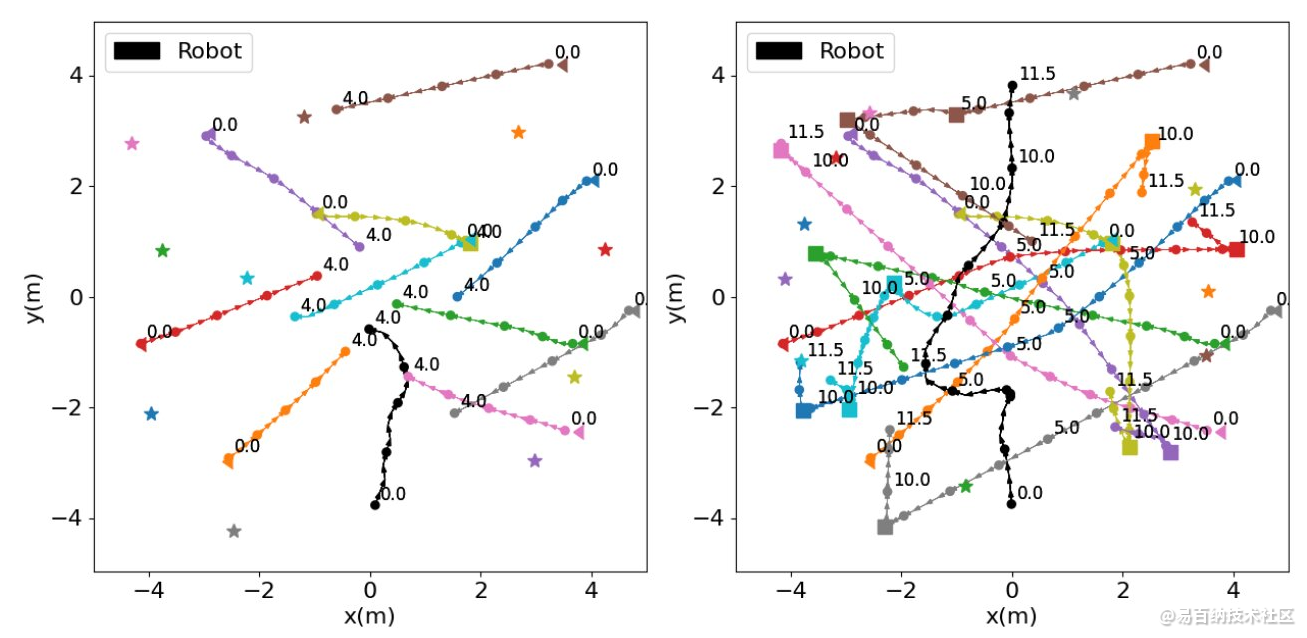
使用标准探索策略训练的机器人的碰撞轨迹(左)和在相同场景中使用内在奖励训练的机器人的成功轨迹
虽然机器人在过去几年中变得越来越先进,但它们中的大多数仍然无法可靠地导航非常拥挤的空间,例如城市环境中的公共区域或道路。然而,为了在未来的智能城市中大规模实施,机器人将需要能够可靠、安全地在这些环境中导航,而不会与人类或附近的物体发生碰撞。
萨拉戈萨大学和西班牙阿拉贡工程研究所的研究人员最近提出了一种新的基于机器学习的方法,可以改善室内和室外拥挤环境中的机器人导航。这种方法在arXiv服务器上预先发表的一篇论文中介绍,需要使用内在奖励,本质上是AI代理在执行与其尝试完成的任务不严格相关的行为时获得的“奖励”。
“自主机器人导航是一个悬而未决的问题,特别是在非结构化和动态环境中,机器人必须避免与动态障碍物发生碰撞并达到目标,”进行这项研究的研究人员之一Diego Martinez Baselga表示。“事实证明,深度强化学习算法在成功率和达到目标的时间方面具有很高的性能,但仍有很多需要改进的地方。
Martinez Baselga及其同事引入的方法使用内在奖励,旨在增加智能体探索新“状态”(即与其环境的交互)的动机或降低给定场景中的不确定性水平,以便智能体能够更好地预测其行为的后果。在他们的研究背景下,研究人员专门利用这些奖励来鼓励机器人访问其环境中的未知区域,并以不同的方式探索其环境,以便它能够随着时间的推移学会更有效地导航。
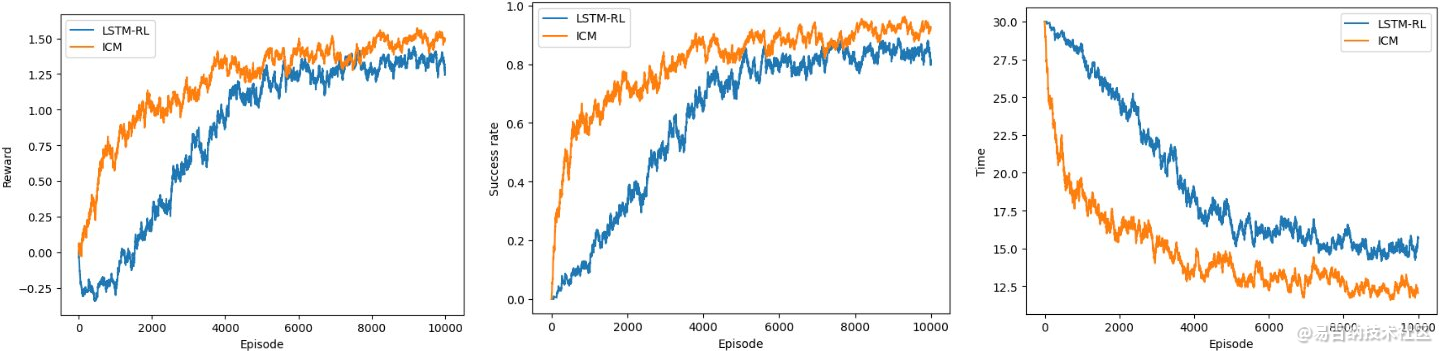
与具有ICM(内在奖励)的相同算法相比,最先进算法的训练指标
“大多数用于人群导航的深度强化学习工作都集中在改进网络和机器人感知的处理上,”Martinez Baselga说。“我的方法研究如何在培训期间探索环境,以改善学习过程。在训练中,机器人不是尝试随机动作或最 佳动作,而是尝试做它认为可以从中学到更多的东西。
Martinez Baselga和他的同事评估了使用内在奖励使用两种不同方法解决拥挤空间中的机器人导航的潜力。其中第一个集成了所谓的“内在好奇心模块”(ICM),而第二个则基于一系列称为高效探索随机编码器(RE3)的算法。
研究人员在一系列模拟中评估了这些模型,这些模拟在CrowdNav模拟器上运行。他们发现,他们提出的两种整合内在奖励的方法都优于以前开发的最先进的拥挤空间机器人导航方法。
未来,这项研究可以鼓励其他机器人专家在训练机器人时使用内在奖励,以提高他们应对不可预见的情况并在高度动态的环境中安全移动的能力。此外,Martinez Baselga及其同事测试的两个基于内在奖励的模型很快就会在真实机器人中集成和测试,以进一步验证它们的潜力。
“结果表明,应用这些智能探索策略,机器人学习得更快,最终学习的策略更好;并且它们可以应用于现有算法之上以改进它们,“Martinez Baselga补充道。“在我的下一个研究中,我计划改进机器人导航中的深度强化学习,使其更安全、更可靠,这对于在现实世界中使用它非常重要。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1423次2023-03-23 10:43:10
-
浏览量:988次2023-08-19 09:30:52
-
浏览量:617次2023-09-26 16:15:11
-
浏览量:9576次2020-12-10 18:35:14
-
浏览量:1290次2023-09-22 11:21:03
-
浏览量:710次2023-10-20 10:57:18
-
浏览量:867次2023-03-14 10:09:41
-
浏览量:3661次2019-07-05 11:12:50
-
浏览量:1369次2023-03-13 13:49:39
-
浏览量:896次2023-07-20 10:57:55
-
浏览量:1572次2019-08-02 14:58:25
-
浏览量:1936次2022-11-18 14:29:30
-
浏览量:8943次2020-12-11 16:05:44
-
浏览量:1573次2023-04-23 09:38:45
-
浏览量:807次2023-10-13 16:06:47
-
浏览量:628次2023-10-16 14:15:15
-
浏览量:2514次2018-01-19 22:01:16
-
浏览量:7979次2018-09-03 15:47:26
-
浏览量:1635次2023-04-14 14:37:29






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
艾

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
