

基于视觉变压器的人脸识别框架

人脸识别工具是计算模型,可以识别图像中的特定人物,以及闭路电视或视频片段。这些工具已经在广泛的现实环境中使用,例如协助执法和边境管制人员进行刑事调查和监视工作,以及用于身份验证和生物识别应用。虽然大多数现有模型的表现都非常好,但仍有很大的改进空间。
伦敦玛丽皇后大学的研究人员最近创建了一个新的、有前景的人脸识别架构。这种架构在arXiv上预先发表的一篇论文中提出,它基于一种从图像中提取面部特征的策略,该策略与迄今为止提出的大多数图像不同。
“使用卷积神经网络(CNN)和基于利润的损失的整体方法主导了面部识别的研究,”进行这项研究的两位研究人员Zhonglin Sun和Georgios Tzimiropoulos表示。
“在这项工作中,我们从两个方面出发:(a)我们使用Vision Transformer作为训练非常强大的人脸识别基线的架构,简称为fViT,它已经超越了大多数最先进的人脸识别方法。(b)其次,我们利用变压器的固有属性来处理从不规则网格中提取的信息(视觉标记),以设计一种让人联想到基于部分的人脸识别方法的人脸识别管道。
最普遍的人脸识别方法基于CNN,这是一类人工神经网络(CNN),可以自主学习在图像中查找模式,例如识别特定的物体或人。虽然其中一些方法取得了非常好的性能,但最近的工作突出了另一类人脸识别算法的潜力,称为视觉变压器(ViTs)。
与通常分析整个图像的CNN相比,ViT将图像拆分为特定大小的块,然后向这些补丁添加嵌入。然后将生成的向量序列馈送到标准转换器,这是一种深度学习模型,可以对正在分析的数据的不同部分进行差异加权。
“与CNN相反,ViT实际上可以在从不规则网格中提取的补丁上运行,并且不需要用于卷积的均匀间隔的采样网格,”研究人员在他们的论文中解释说。“由于人脸是由部分(例如,眼睛,鼻子,嘴唇)组成的结构化对象,并且受到深度学习之前基于部分的面部识别的开创性工作的启发,我们建议将ViT应用于代表面部部位的贴片。
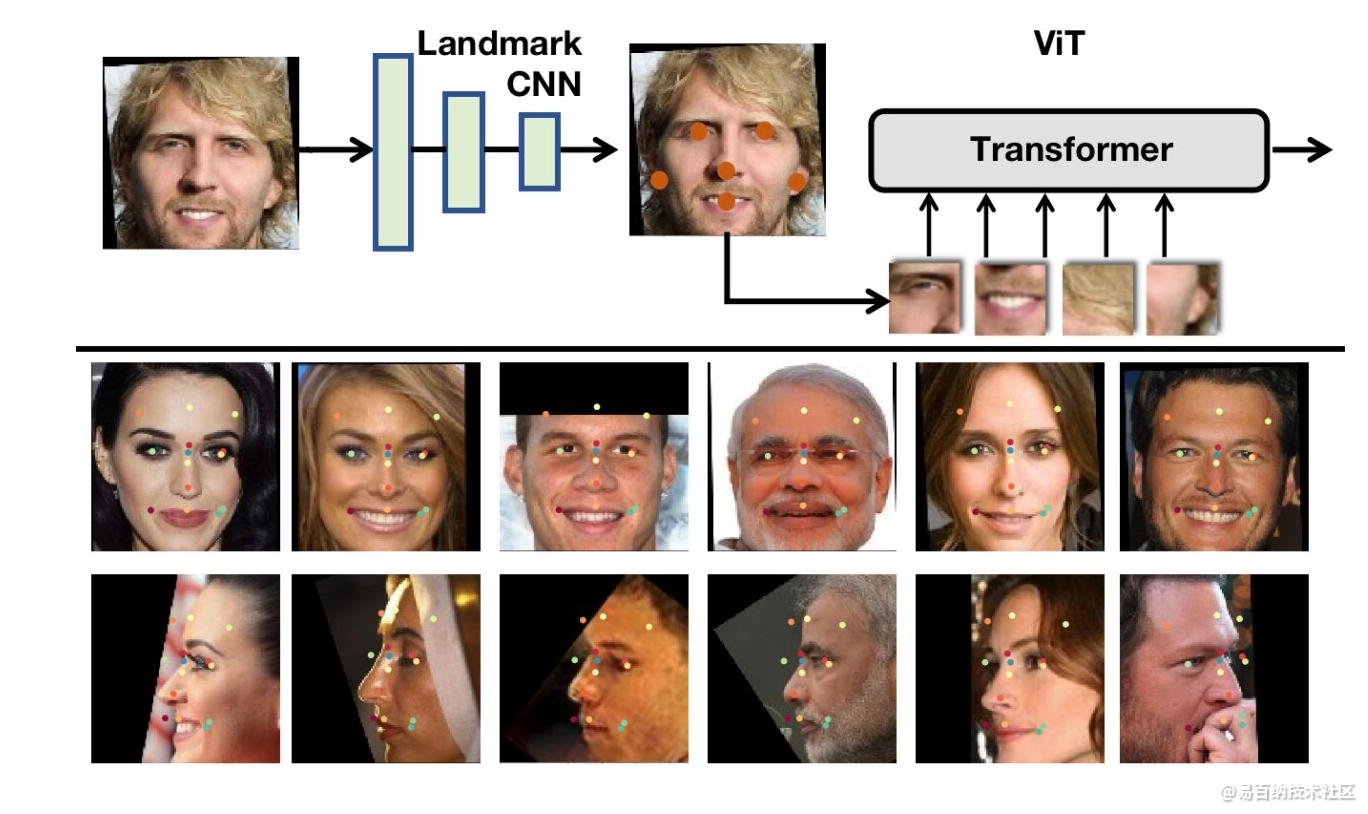
由Sun和Tzimiropoulos创建的视觉变压器架构,被称为fViT部分,由轻量级网络和视觉变压器组成。网络预测面部特征点(例如,鼻子、嘴巴等)的坐标,而转换器分析包含预测地标的斑块。
研究人员使用两个众所周知的数据集训练了不同的人脸变压器,即包含 93,431 人图像的 MS1MV3 和包含 310 万张图像和 8,600 个身份的 VGGFace2。随后,他们进行了一系列测试来评估他们的模型,还改变了他们的一些特征来测试这对他们的性能有何影响。
他们的架构在其测试的所有数据集上都实现了惊人的准确性,可与许多其他最先进的人脸识别模型相媲美。此外,他们的模型似乎在没有经过专门训练的情况下成功地描绘了面部特征。
未来,这项最近的研究可能会激发其他基于视觉转换器的人脸识别模型的开发。此外,研究人员的架构可以在应用程序或软件工具中实现,这些应用程序或软件工具可以从对不同人脸特征的选择性分析中受益。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1749次2022-01-31 09:00:12
-
浏览量:2335次2024-05-24 17:53:56
-
浏览量:1162次2024-03-14 17:53:46
-
浏览量:1634次2020-08-06 10:12:40
-
2020-12-08 10:24:22
-
浏览量:353次2023-07-24 11:00:24
-
浏览量:2177次2020-07-22 14:39:14
-
浏览量:1935次2022-12-16 09:12:30
-
浏览量:216次2023-08-03 15:58:40
-
浏览量:1765次2019-08-02 17:06:48
-
浏览量:3162次2019-09-17 14:36:22
-
浏览量:1431次2024-02-26 14:47:49
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:4376次2017-11-02 17:07:21
-
浏览量:629次2023-11-16 09:44:04
-
浏览量:4024次2020-12-23 17:19:19
-
浏览量:3392次2019-11-13 09:15:39
-
浏览量:3759次2022-02-06 09:00:19
-
浏览量:2690次2019-06-18 10:00:28


-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

万万没想到

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
