

增强自动驾驶汽车坡道合并能力的强化学习框架

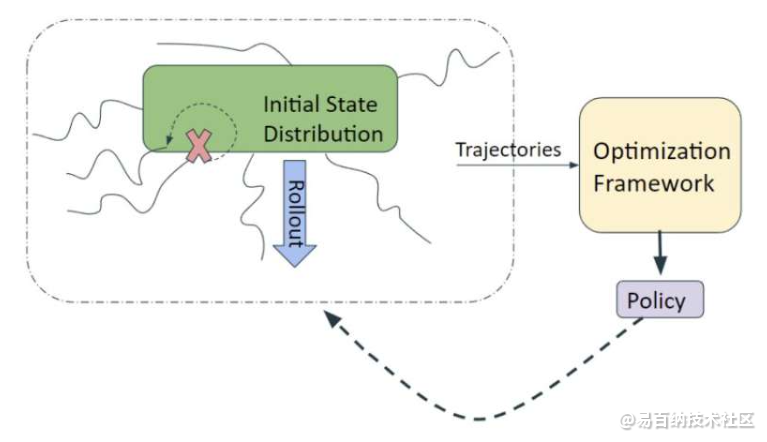
解释团队强化学习管道的图。他们首先从随机初始状态初始化推出,并对收集的轨迹集运行优化,以为每个纪元训练策略。
虽然许多汽车公司现在都在投资开发自动驾驶汽车,但迄今为止制造的车辆尚未达到大规模部署所需的安全水平。为此,车辆需要能够安全有效地应对道路上的各种挑战。
卡内基梅隆大学的研究人员最近开发了一种基于强化学习(RL)的框架,可以帮助提高自动驾驶汽车在匝道合并场景中的性能,即匝道道路上的车辆偏离到主要道路上的情况。他们的框架在arXiv上预先发表的一篇论文中提出,可能有助于在这些特别重要的时期提高自动驾驶汽车的安全性,降低事故风险。
“CMU的John Dolan教授的实验室已经研究了一段时间的各种自动驾驶应用,”开发该模型的研究人员之一Soumith Udatha告诉TechXplore。“我们在本文中关注的应用是高速公路合并,因为高速车辆、各种风格的驾驶员以及所涉及的不确定性存在挑战。”
Udatha及其同事研究工作的首要目标是提高自动驾驶汽车的安全性。在他们最近的论文中,他们特别试图设计一个框架,可以有效地捕捉坡道合并场景,并根据对任何不确定性和可能风险的分析来规划车辆的行动。
“RL模型与环境交互并收集数据以优化其奖励,但是这种数据探索在实际环境中部署时会遇到一些问题,”Udatha解释说。“这部分是因为并非代理遇到的所有状态都是安全的。我们使用控制屏障功能 (CBF) 约束我们的 RL 策略,以确保指定距离的安全。因此,在环境限制下,我们忽略了不安全的状态,并增强了系统学习如何导航的能力。
CBF是一类相当新的计算方法,旨在增强自治系统的安全控制。CBF可以直接应用于不同的优化问题,包括斜坡合并。尽管它们的质量很有希望,但它们执行的优化并没有考虑到系统在探索环境时收集的数据。RL方法可以帮助填补这一空白。
“我们发现我们的算法可以扩展到离线和在线RL环境,”Udatha说。“由于我们现在有大量用于离线RL的数据,因此在离线数据集上进行训练最终可以产生更好的模型。通过我们的指标,我们还发现,将概率CBF作为约束可以提供更好的安全性,因为它在一定程度上解释了驾驶员的不确定性。
Udatha 和他的同事在一系列测试中测试了他们的框架,使用由英特尔实验室和巴塞罗那计算机视觉中心的一组研究人员开发的在线版本的 CARLA 模拟器。在这些模拟中,他们的方法取得了显着的结果,突出了其在坡道合并期间提高自动驾驶汽车安全性的可能价值。
“我们现在计划通过训练我们的模型来扩展我们的研究,以便在驾驶员不确定的场景中将自动驾驶汽车与多辆车合并,”Udatha补充道。“我们还发现,目前缺少一个比较各种匝道合并方法的标准基准,因此我们同时试图为NGSIM建立一个匝道合并基准,NGSIM是NHTSA在美国I-80和US 101高速公路上发布的高速公路数据集。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1992次2020-07-01 17:44:50
-
浏览量:3912次2021-09-09 14:15:15
-
浏览量:2196次2020-07-31 17:27:52
-
浏览量:1785次2019-06-10 09:31:33
-
浏览量:1699次2023-02-28 11:53:25
-
浏览量:1468次2022-12-07 10:05:17
-
浏览量:1386次2022-12-07 18:55:35
-
浏览量:1391次2019-06-18 13:45:49
-
浏览量:46210次2019-07-12 15:07:40
-
浏览量:1684次2022-01-21 09:00:31
-
浏览量:9107次2021-07-12 11:01:47
-
浏览量:1722次2020-03-11 09:48:51
-
浏览量:1579次2019-06-26 13:40:10
-
浏览量:2498次2020-01-08 11:20:32
-
浏览量:37729次2019-07-30 17:51:57
-
浏览量:1640次2023-04-14 14:37:29
-
浏览量:4487次2021-01-28 17:24:58
-
浏览量:686次2023-09-07 09:12:40
-
浏览量:4970次2021-03-15 16:24:28






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
艾

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
