

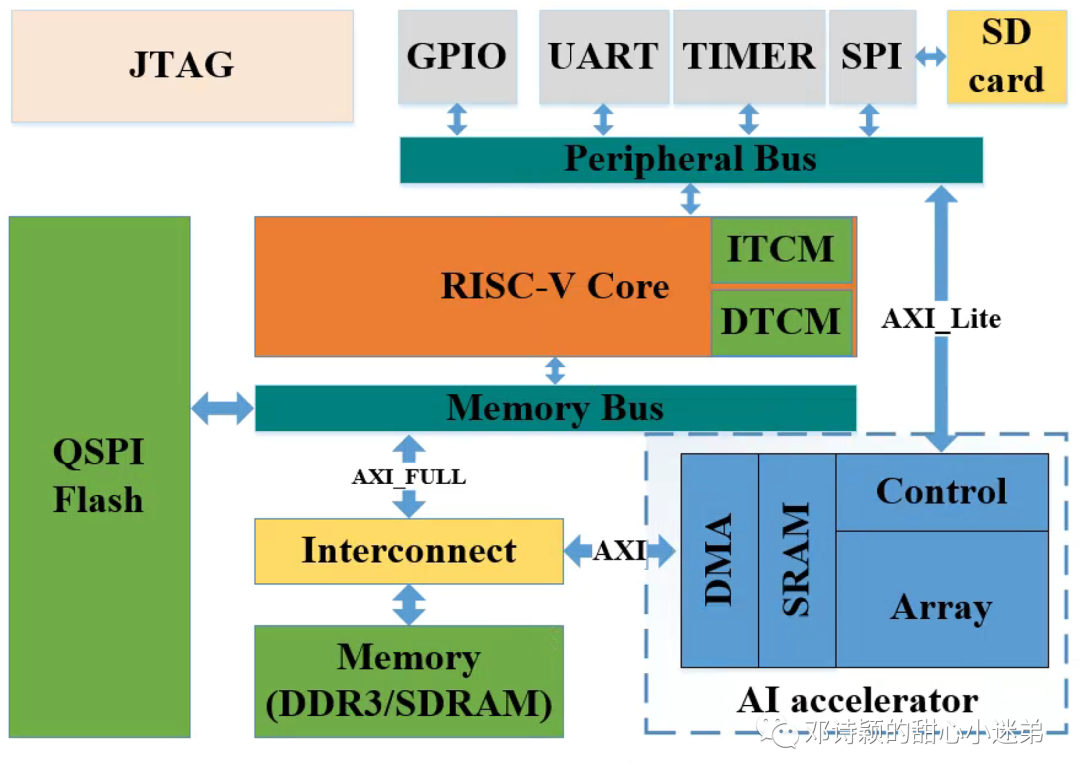
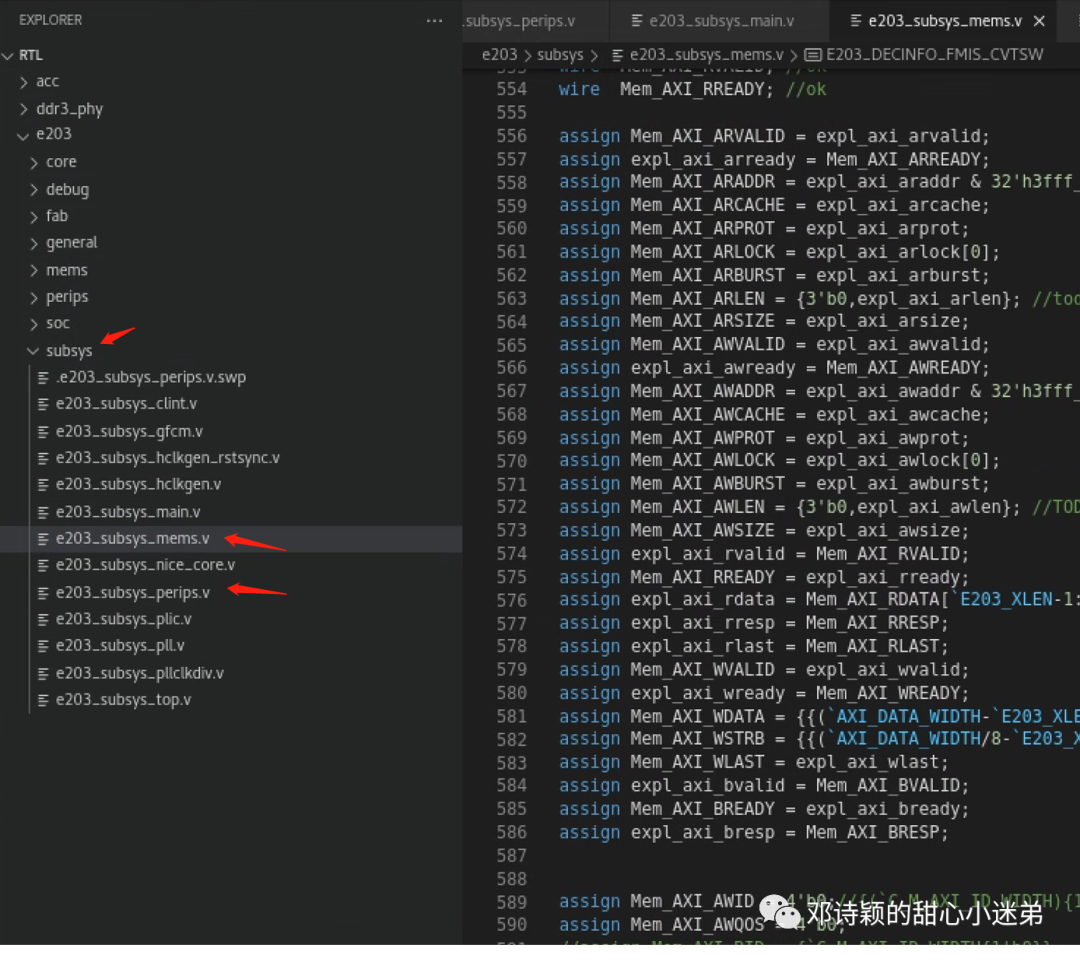
 ****
****

 微信扫码分享
微信扫码分享 QQ好友
QQ好友
星空
2022-09-06 20:38:54
回复
举报
你好,请问一下 移植好rsicv后 怎么去跑程序呀 刚入手 完全不懂






