

【深度学习】基于Pytorch的softmax回归问题辨析和应用(一)

【深度学习】基于Pytorch的softmax回归问题辨析和应用(一)

文章目录
1 概述
2 网络结构
3 softmax运算
4 仿射变换
5 对数似然
6 图像分类数据集
7 数据预处理
8 总结1 概述
回归可以用于预测 多少 的问题。比如预测房屋被售出价格,或者棒球队可能获得的胜利数,又或者患者住院的天数。
事实上,我们经常对 分类 感兴趣:不是问“多少”,而是问“哪一个”:
该电子邮件是否属于垃圾邮件文件夹?
该用户可能 注册 或 不注册 订阅服务?
该图像描绘的是驴、狗、猫、还是鸡?
韩梅梅接下来最有可能看哪部电影?
让我们从一个图像分类问题开始简单尝试一下。每次输入是一个 $2\times2$ 的灰度图像。我们可以用一个标量表示每个像素值,每个图像对应四个特征 $x_1, x_2, x_3, x_4$。此外,让我们假设每个图像属于类别 “猫”,“鸡” 和 “狗” 中的一个。
接下来,我们要选择如何表示标签。我们有两个明显的选择。也许最直接的想法是选择 $y \in {1, 2, 3}$,其中整数分别代表 ${\text{狗}, \text{猫}, \text{鸡}}$。这是在计算机上存储此类信息的好方法。如果类别间有一些自然顺序,比如说我们试图预测 ${\text{婴儿}, \text{儿童}, \text{青少年}, \text{青年人}, \text{中年人}, \text{老年人}}$,那么将这个问题转变为回归问题并保留这种格式是有意义的。
但是,一般的分类问题并不与类别之间的自然顺序有关。幸运的是,统计学家很早以前就发明了一种表示分类数据的简单方法:独热编码(one-hot encoding)。独热编码是一个向量,它的分量和类别一样多。类别对应的分量设置为1,其他所有分量设置为0。
在我们的例子中,标签 $y$ 将是一个三维向量,其中 $(1, 0, 0)$ 对应于 “猫”、$(0, 1, 0)$ 对应于 “鸡”、$(0, 0, 1)$ 对应于 “狗”:
$$y \in {(1, 0, 0), (0, 1, 0), (0, 0, 1)}.$$
2 网络结构
为了估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。
为了解决线性模型的分类问题,我们需要和输出一样多的仿射函数(affine function)。
每个输出对应于它自己的仿射函数。
在我们的例子中,由于我们有4个特征和3个可能的输出类别,我们将需要12个标量来表示权重(带下标的$w$),3个标量来表示偏置(带下标的$b$)。
下面我们为每个输入计算三个未归一化的预测(logits):$o_1$、$o_2$和$o_3$。
$$
\begin{aligned}
o_1 &= x1 w{11} + x2 w{12} + x3 w{13} + x4 w{14} + b_1,\
o_2 &= x1 w{21} + x2 w{22} + x3 w{23} + x4 w{24} + b_2,\
o_3 &= x1 w{31} + x2 w{32} + x3 w{33} + x4 w{34} + b_3.
\end{aligned}
$$
我们可以用神经网络图来描述这个计算过程。
与线性回归一样,softmax回归也是一个单层神经网络。由于计算每个输出$o_1$、$o_2$和$o_3$取决于所有输入$x_1$、$x_2$、$x_3$和$x_4$,所以softmax回归的输出层也是全连接层。
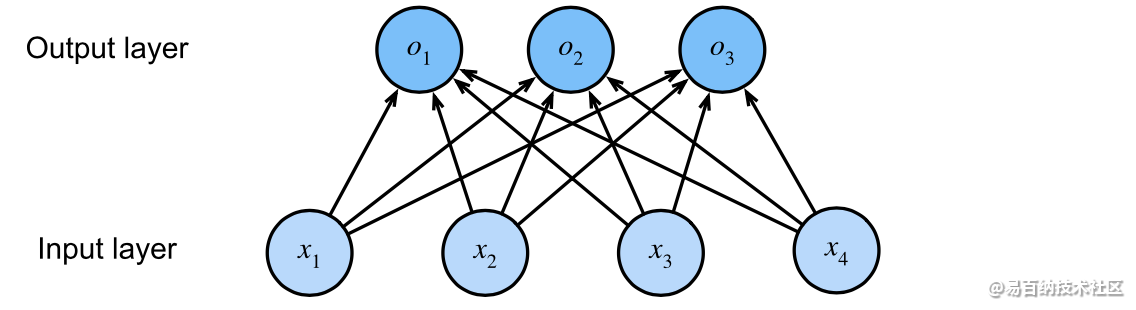
为了更简洁地表达模型,我们仍然使用线性代数符号。
通过向量形式表达为 $\mathbf{o} = \mathbf{W} \mathbf{x} + \mathbf{b}$,这是一种更适合数学和编写代码的形式。我们已经将所有权重放到一个 $3 \times 4$ 矩阵中。对于给定数据样本的特征 $\mathbf{x}$,我们的输出是由权重与输入特征进行矩阵-向量乘法再加上偏置$\mathbf{b}$得到的。
正如我们将在后续章节中看到的,在深度学习中,全连接层无处不在。
然而,顾名思义,全连接层是“完全”连接的,可能有很多可学习的参数。
具体来说,对于任何具有$d$个输入和$q$个输出的全连接层,参数开销为$\mathcal{O}(dq)$,在实践中可能高得令人望而却步。
3 softmax运算
社会科学家邓肯·卢斯于1959年在选择模型(choice models)的背景下发明的softmax函数正是这样做的。
为了将未归一化的预测变换为非负并且总和为1,同时要求模型保持可导。我们首先对每个未归一化的预测求幂,这样可以确保输出非负。为了确保最终输出的总和为1,我们再对每个求幂后的结果除以它们的总和。如下式:
$$\hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)}$$
容易看出对于所有的 $j$ 总有 $0 \leq \hat{y}_j \leq 1$。因此,$\hat{\mathbf{y}}$ 可以视为一个正确的概率分布。softmax 运算不会改变未归一化的预测 $\mathbf{o}$ 之间的顺序,只会确定分配给每个类别的概率。因此,在预测过程中,我们仍然可以用下式来选择最有可能的类别。
$$
\operatorname{argmax}_j \hat y_j = \operatorname{argmax}_j o_j.
$$
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。因此,softmax回归是一个线性模型。
4 仿射变换
仿射变换,又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。

5 对数似然
softmax函数给出了一个向量 $\hat{\mathbf{y}}$,我们可以将其视为给定任意输入 $\mathbf{x}$的每个类的估计条件概率。例如,$\hat{y}_1$ = $P(y=\text{猫} \mid \mathbf{x})$。假设整个数据集 ${\mathbf{X}, \mathbf{Y}}$ 具有 $n$ 个样本,其中索引 $i$ 的样本由特征向量 $\mathbf{x}^{(i)}$ 和独热标签向量 $\mathbf{y}^{(i)}$ 组成。我们可以将估计值与实际值进行比较:
$$
P(\mathbf{Y} \mid \mathbf{X}) = \prod_{i=1}^n P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}).
$$
根据最大似然估计,我们最大化 $P(\mathbf{Y} \mid \mathbf{X})$,相当于最小化负对数似然:
$$
-\log P(\mathbf{Y} \mid \mathbf{X}) = \sum{i=1}^n -\log P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)})
= \sum{i=1}^n l(\mathbf{y}^{(i)}, \hat{\mathbf{y}}^{(i)}),
$$
其中,对于任何标签 $\mathbf{y}$ 和模型预测 $\hat{\mathbf{y}}$,损失函数为:
$$ l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j. $$
由于 $\mathbf{y}$ 是一个长度为 $q$ 的独热编码向量,所以除了一个项以外的所有项 $j$ 都消失了。由于所有 $\hat{y}_j$ 都是预测的概率,所以它们的对数永远不会大于 $0$。
因此,如果正确地预测实际标签,即,如果实际标签 $P(\mathbf{y} \mid \mathbf{x})=1$,则损失函数不能进一步最小化。
注意,这往往是不可能的。例如,数据集中可能存在标签噪声(某些样本可能被误标),或输入特征没有足够的信息来完美地对每一个样本分类。
softmax运算获取一个向量并将其映射为概率。
softmax回归适用于分类问题。它使用了softmax运算中输出类别的概率分布。
交叉熵是一个衡量两个概率分布之间差异的很好的度量。它测量给定模型编码数据所需的比特数。
softmax和交叉熵绝配哦!!!!!6 图像分类数据集
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False,
transform=trans, download=True)

Fashion-MNIST中包含的10个类别分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。以下函数用于在数字标签索引及其文本名称之间进行转换。
def get_fashion_mnist_labels(labels): #@save
"""返回Fashion-MNIST数据集的文本标签。"""
text_labels = [
't-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt',
'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axesX, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
7 数据预处理
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中。"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root="../data",
train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data",
train=False,
transform=trans,
download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break
8 总结
虽然说深度学习的教程已经烂大街了,基础理论也比较容易掌握,但是真正让自己去实现的时候还是有一些坑。一方面教程不会涉及太多具体的工程问题,另一方面啃PyTorch的英文文档还是有点麻烦。
在这篇文章中,笔者首先介绍了FashionMNIST数据集。然后接着介绍了如何使用Pytorch中的DataLoader来构造训练数据迭代器。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5526次2021-08-05 09:20:49
-
浏览量:6583次2021-08-03 11:36:37
-
浏览量:6410次2021-08-03 11:36:18
-
浏览量:5404次2021-07-26 11:25:51
-
浏览量:1044次2023-09-18 15:02:26
-
浏览量:5595次2021-08-13 15:39:02
-
浏览量:6186次2021-06-15 11:49:53
-
浏览量:7043次2021-05-31 17:02:05
-
浏览量:7051次2021-08-09 16:09:53
-
浏览量:6244次2021-05-17 16:52:58
-
浏览量:6448次2021-07-26 17:43:04
-
浏览量:5576次2021-06-21 11:50:25
-
浏览量:6003次2021-08-02 09:34:03
-
浏览量:5195次2021-08-09 16:10:30
-
浏览量:5628次2021-08-09 16:10:57
-
浏览量:5324次2021-07-26 11:28:05
-
浏览量:14477次2021-07-08 09:43:47
-
浏览量:4667次2021-06-30 11:34:00
-
浏览量:5338次2021-07-02 14:29:53

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
