

【深度学习】基于PyTorch的模型训练实用教程之数据处理
【深度学习】基于PyTorch的模型训练实用教程之数据处理
文章目录
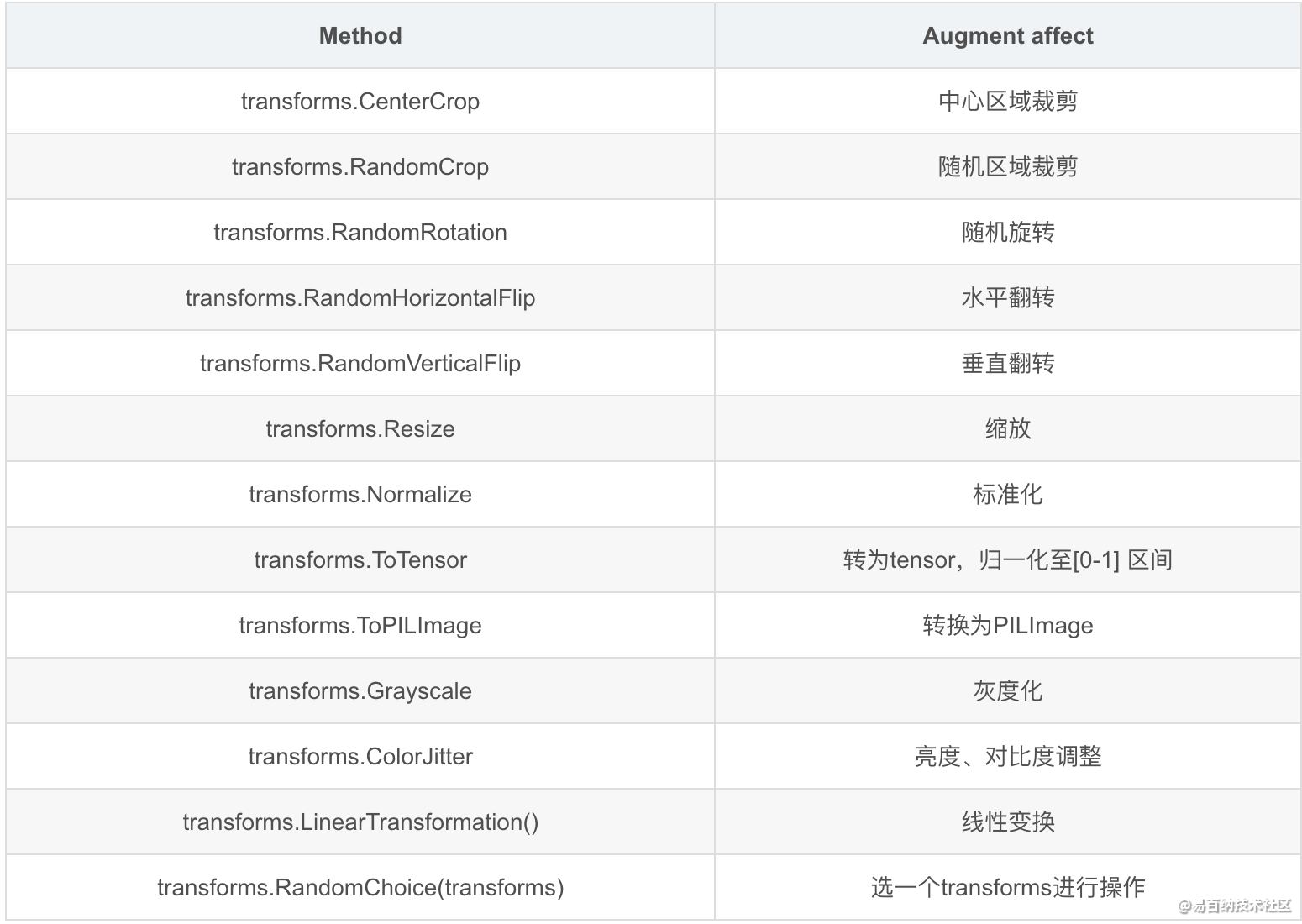
1 transforms 的二十二个方法
2 数据加载和预处理教程
3 torchvision
4 如何用Pytorch进行文本预处理
5 补充
- 1
- 2
- 3
- 4
- 5
- 6
1 transforms 的二十二个方法
-
裁剪——Crop 中心裁剪:transforms.CenterCrop 随机裁剪:transforms.RandomCrop 随机长宽比裁剪:transforms.RandomResizedCrop 上下左右中心裁剪:transforms.FiveCrop 上下左右中心裁剪后翻转,transforms.TenCrop
-
翻转和旋转——Flip and Rotation:依概率 p 水平翻转:transforms.RandomHorizontalFlip(p=0.5)
依概率 p 垂直翻转:transforms.RandomVerticalFlip(p=0.5) 随机旋转:transforms.RandomRotation
3.图像变换
resize:transforms.Resize
标准化:transforms.Normalize
转为 tensor,并归一化至[0-1]:transforms.ToTensor 填充:transforms.Pad 修改亮度、对比度和饱和度:transforms.ColorJitter 转灰度图:transforms.Grayscale 线性变换:transforms.LinearTransformation() 仿射变换:transforms.RandomAffine
依概率 p 转为灰度图:transforms.RandomGrayscale 将数据转换为 PILImage:transforms.ToPILImage transforms.Lambda:Apply a user-defined lambda as a transform.
4.对 transforms 操作,使数据增强更灵活
transforms.RandomChoice(transforms), 从给定的一系列 transforms 中选一个进行操作 transforms.RandomApply(transforms, p=0.5),给一个 transform 加上概率,依概率进行操作 transforms.RandomOrder,将 transforms 中的操作随机打乱
2 数据加载和预处理教程
首先需要确保安装以下几个 python 库:
scikit-image :处理图片数据
pandas :处理 csv 文件
导入模块代码如下:
from __future__ import print_function, division
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# Ignore warnings
import warnings
warnings.filterwarnings("ignore")
plt.ion() # interactive mode- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
本次教程采用的是一个人脸姿势数据集,其图片如下所示:

每张人脸都是有 68 个人脸关键点,它是由 dlib 生成的,具体实现可以查看其官网介绍:
https://blog.dlib.net/2014/08/real-time-face-pose-estimation.html
数据集下载地址:
https://download.pytorch.org/tutorial/faces.zip
数据集中的 csv 文件的格式如下所示,图片名字和每个关键点的坐标 x, y
image_name,part_0_x,part_0_y,part_1_x,part_1_y,part_2_x, ... ,part_67_x,part_67_y
0805personali01.jpg,27,83,27,98, ... 84,134
1084239450_e76e00b7e7.jpg,70,236,71,257, ... ,128,312
数据集下载解压缩后放到文件夹 data/faces 中,然后我们先快速打开 face_landmarks.csv 文件,查看文件内容,即标注信息,代码如下所示:
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 65
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
接着写一个辅助函数来显示人脸图片及其关键点,代码如下所示:
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
show_landmarks(io.imread(os.path.join('data/faces/', img_name)),
landmarks)
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出如下所示:

3 torchvision
最后介绍 torchvision 这个库,它提供了一些常见的数据集和预处理方法,采用这个库就可以不需要自定义类,它比较常用的方法是 ImageFolder ,它假定图片的保存路径如下所示:
root/ants/xxx.png
root/ants/xxy.jpeg
root/ants/xxz.png
.
.
.
root/bees/123.jpg
root/bees/nsdf3.png
root/bees/asd932_.png- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里的 ants,bees 等等都是类别标签,此外对 PIL.Image 的预处理方法,如 RandomHorizontalFlip 、Scale 都包含在 torchvision 中,一个使用例子如下所示:
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',
transform=data_transform)
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,
batch_size=4, shuffle=True,
num_workers=4)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4 如何用Pytorch进行文本预处理
文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
读入文本
分词
建立字典,将每个词映射到一个唯一的索引(index)
将文本从词的序列转换为索引的序列,方便输入模型
读入文本
我们用一部英文小说,即H. G. Well的Time Machine,作为示例,展示文本预处理的具体过程。
import collections
import re
def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt', 'r') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
return lines
lines = read_time_machine()
print('# sentences %d' % len(lines))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:#sentences 3221
分词
我们对每个句子进行分词,也就是将一个句子划分成若干个词(token),转换为一个词的序列。
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unkown token type '+token)
tokens = tokenize(lines)
tokens[0:2]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:[[‘the’, ‘time’, ‘machine’, ‘by’, ‘h’, ‘g’, ‘wells’, ‘’], [’’]]
建立字典
为了方便模型处理,我们需要将字符串转换为数字。因此我们需要先构建一个字典(vocabulary),将每个词映射到一个唯一的索引编号。
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = count_corpus(tokens) # :
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
下一步输入模型训练即可。
5 补充
Torchvision对图像数据进行扩充常用Method

GAN生成扩充数据
利用对抗式神经网络在原有数据基础上通过训练可以生成新的数据。这就需要一个专门训练生成数据的网络。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:18673次2021-07-15 10:45:21
-
浏览量:6048次2021-07-30 10:33:41
-
浏览量:12963次2021-05-12 12:35:30
-
浏览量:15185次2021-05-31 17:01:39
-
浏览量:8177次2021-07-13 10:59:24
-
浏览量:6224次2021-08-03 11:36:37
-
浏览量:6147次2021-08-03 11:36:18
-
浏览量:5185次2021-07-26 11:25:51
-
浏览量:5978次2021-07-26 17:43:04
-
浏览量:5182次2021-04-27 16:30:07
-
浏览量:5357次2021-08-13 15:39:02
-
浏览量:5108次2021-04-21 17:06:33
-
浏览量:5029次2021-08-05 09:21:07
-
浏览量:5159次2021-08-05 09:20:49
-
浏览量:10648次2020-11-08 17:15:55
-
浏览量:28332次2021-01-08 11:33:04
-
浏览量:13525次2021-07-08 09:43:47
-
浏览量:5073次2021-07-26 11:28:05
-
浏览量:7577次2021-07-12 11:03:00

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
