

【深度学习】基于Colab Pro的TPU训练模型教程(Tensorflow)

文章目录
1 概述
2 对比 TPU 与 GPU 的计算速度
3 总结和简易的测试代码
4 为什么使用 TPU1 概述
TPU 比 CPU 和 GPU 快 15~30 倍。. 效率则以每瓦特能量消耗执行的 tera-操作计算。. TPU 比 CPU 和 GPU 效率高 30~80 倍。. TPU,GPU,CPU 和改进的 TPU 的性能对比。. GPU(蓝色)和TPU(红色)相对于CPU的能效比(功耗/瓦,TDP),以及 TPU 相对于GPU 的能效比。. TPU’是改进的TPU。. 绿色代表改进的 TPU 与 CPU 对比的性能,浅紫色代表改进的 TPU与 GPU 对比性能。. 总和数据(Total)包含了主机服务器的功耗,增量数据(Incremental)则不包含主机服务器的功耗。.
接下来看下如何在 Colab 上开启 PyTorch 对 TPU 的支持,PyTorch 是通过 XLA 编译器来支持 TPU 的,详情自查。这里只需要知道把下面这个代码放到一个代码块里面执行以下就打开了支持就好:
import os
print(os.environ["COLAB_TPU_ADDR"])
assert os.environ["COLAB_TPU_ADDR"], "Make sure to select TPU from Edit > Notebook settings > Hardware accelerator"
VERSION = "20200325" #@param ["1.5" , "20200325", "nightly"]
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version $VERSION然后通过 torch_xla 包获取 TPU 硬件对 PyTorch 的支持即可。
本文使用tensorflow,如下:
为了确保 Colab 给我们分配了 TPU 计算资源,我们可以运行以下测试代码。如果输出 ERROR 项,则表示目前的运行时并没有调整到 TPU,如果输出 TPU 地址及 TPU 设备列表,则表示 Colab 已经为我们分配了 TPU 计算资源。
如果查看以下测试代码的正常输出,Colab 会为「TPU 运行时」分配 CPU 和 TPU,其中分配的 TPU 工作站有八个核心,因此在后面配置的 TPU 策略会选择 8 条并行 shards。
import os
import pprint
import tensorflow as tf
if 'COLAB_TPU_ADDR' not in os.environ:
print('ERROR: Not connected to a TPU runtime')
else:
tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR']
print ('TPU address is', tpu_address)
with tf.compat.v1.Session(tpu_address) as session:
devices = session.list_devices()
print('TPU devices:')
pprint.pprint(devices)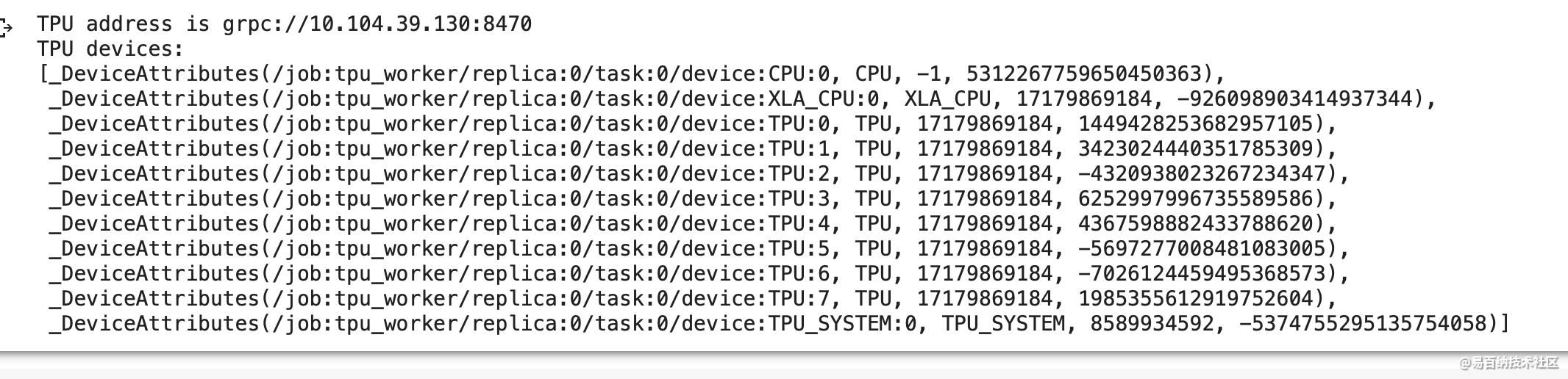
目前,Colab 一共支持三种运行时,即 CPU、GPU(K80)和 TPU(据说是 TPU v2)。但我们不太了解 Colab 中的 GPU 和 TPU 在深度模型中的表现如何,当然后面会用具体的任务去测试,不过现在我们可以先用相同的运算试试它们的效果。因此我们首先尝试用简单的卷积运算测试它们的迭代时间。
在测试不同的硬件时,需要切换到不同的运行时。如下先定义 128 张随机生成的 256×256 图像,然后定义 256 个 5×5 的卷积核后就能执行卷积运算,其中魔术函数 %timeit 会自动多次执行,以产生一个更为精确的平均执行时间。
然而,是我们想当然了,使用 TPU 执行运算似乎需要特定的函数与运算,它不像 CPU 和 GPU 那样可以共用相同的代码。分别选择 CPU、GPU 和 TPU 作为运行时状态,运行上面的代码并迭代一次所需要的时间分别为:2.44 s、280 ms、2.47 s。从这里看来,仅修改运行时状态,并不会真正调用 TPU 资源,真正实现运算的还是 CPU。随后我们发现 TF 存在一个神奇的类 tf.contrib.tpu,似乎真正调用 TPU 资源必须使用它改写模型。
因此,根据文档与调用示例,我们将上面的卷积测试代码改为了以下形式,并成功地调用了 TPU。此外,因为每次都需要重新连接不同的运行时,所以这里的代码都保留了库的导入。虽然代码不太一样,但直觉上它的计算量应该和上面的代码相同,因此大致上能判断 Colab 提供的 GPU、TPU 速度对比。
2 对比 TPU 与 GPU 的计算速度
为了简单起见,这里仅使用 Fashion-MNIST 数据集与简单的 5 层卷积神经网络测试不同的芯片性能。这个模型是基于 Keras 构建的,因为除了模型转换与编译,Keras 模型在 TPU 和 GPU 的训练代码都是一样的,且用 Keras 模型做展示也非常简洁。
几天前谷歌 Colab 团队发了一版使用 Keras 调用 TPU 的教程,因此我们就借助它测试 TPU 的训练速度。对于 GPU 的测试,我们可以修改该模型的编译与拟合部分,并调用 GPU 进行训练。所以整个训练的数据获取、模型结构、超参数都是一样的,不一样的只是硬件。
教程地址:https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynb
以下是整个测试的公共部分,包含了训练数据的获取和模型架构。Keras 的模型代码非常好理解,如下第一个卷积层首先采用了批归一化,然后用 64 个 5×5 的卷积核实现卷积运算,注意这里采用的激活函数都是指数线性单元(ELU)。随后对卷积结果做 2×2 的最大池化,并加上一个随机丢弃率为 0.25 的 Dropout 层,最后得出的结果就是第一个卷积层的输出。
import tensorflow as tf
import numpy as np
import timeit
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# add empty color dimension
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
model = tf.keras.models.Sequential()
# 以下为第一个卷积层
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('elu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
model.summary()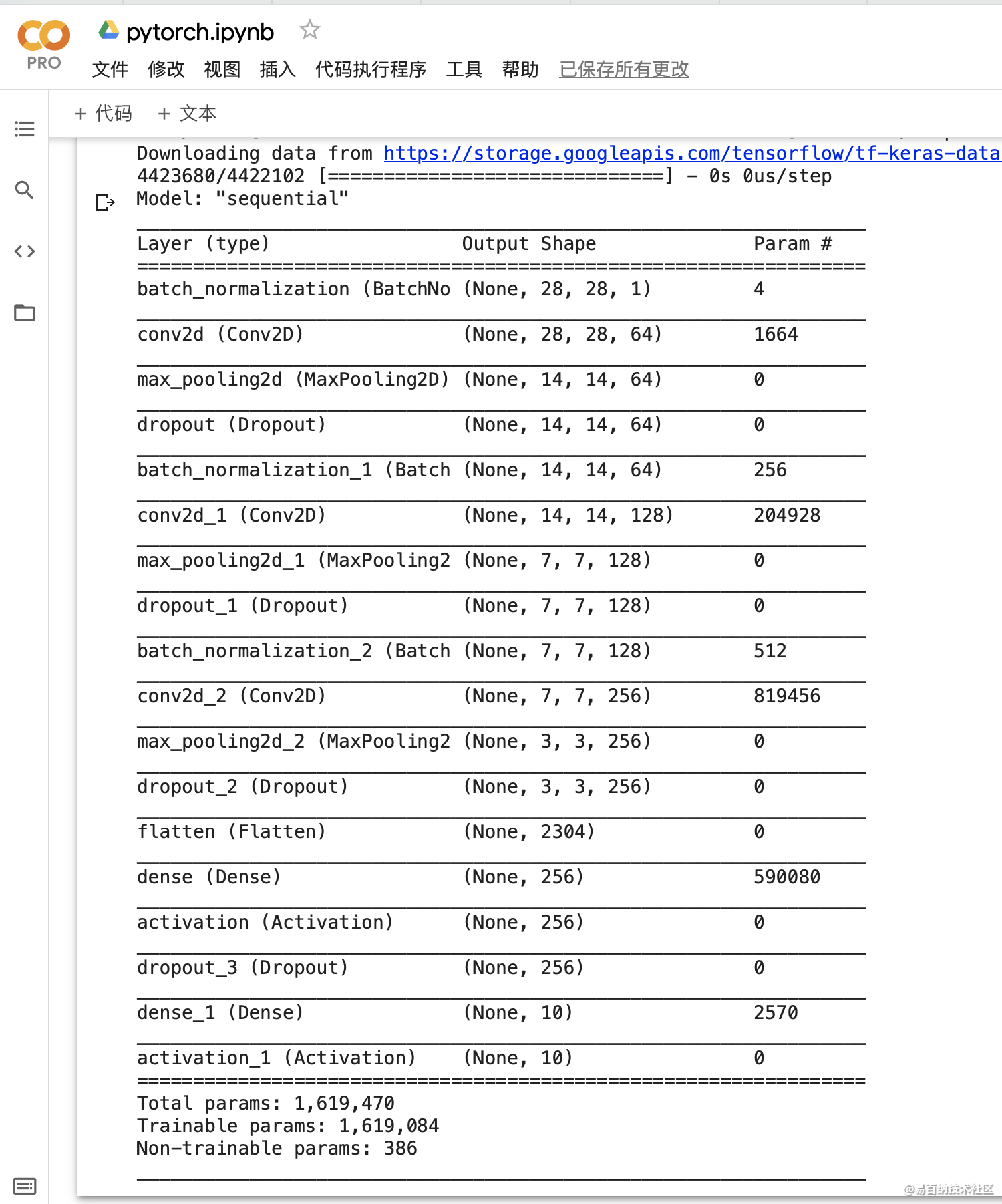
在定义模型后,TPU 需要转化模型与编译模型。如下所示,keras_to_tpu_model 方法需要输入正常 Keras 模型及其在 TPU 上的分布式策略,这可以视为「TPU 版」的模型。完成模型的转换后,只需要像一般 Keras 模型那样执行编译并拟合数据就可以了。
注意两个模型的超参数,如学习率、批量大小和 Epoch 数量等都设置为相同的数值,且损失函数和最优化器等也采用相同的方法。
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
tpu_model.compile(
optimizer=tf.train.AdamOptimizer(learning_rate=1e-3, ),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['sparse_categorical_accuracy']
)
def train_gen(batch_size):
while True:
offset = np.random.randint(0, x_train.shape[0] - batch_size)
yield x_train[offset:offset+batch_size], y_train[offset:offset + batch_size]
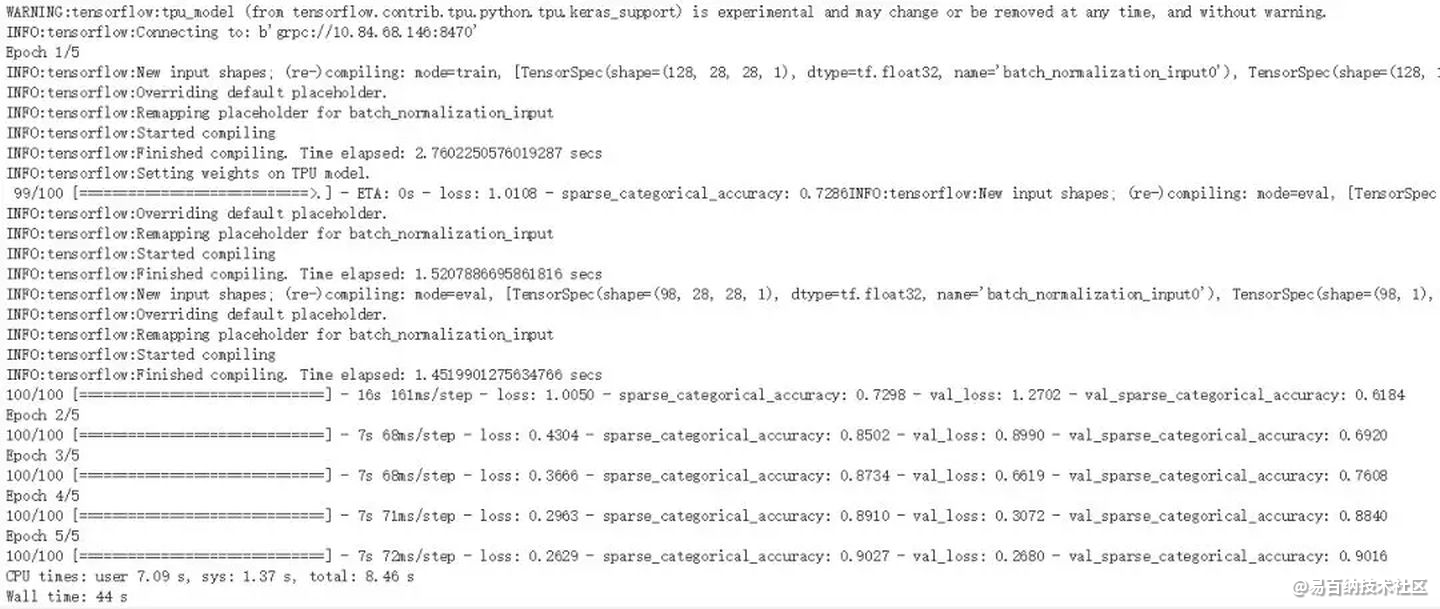
%time tpu_model.fit_generator(train_gen(1024), epochs=5, steps_per_epoch=100, validation_data=(x_test, y_test))这里要注意Tensorflow的版本问题哦!
最后在使用 GPU 训练模型时,我们会删除模型转换步骤,并保留相同的编译和拟合部分。训练的结果如下所示,Colab 提供的 TPU 要比 GPU 快 3 倍左右,一般 TPU 训练 5 个 Epoch 只需要 40 多秒,而 GPU 需要 2 分多钟。
3 总结和简易的测试代码
TPU, tensor processing unit, 张量处理器, 是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。
TPU 比现在的 CPU、GPU 在深度学习的推断任务上,要快 15~30 倍。而在能耗比上,更是好出 30~80 倍。
与图形处理器(GPU)相比,TPU采用低精度(8位)计算,以降低每步操作使用的晶体管数量。降低精度对于深度学习的准确度影响很小,但却可以大幅降低功耗、加快运算速度。同时,TPU使用了脉动阵列的设计,用来优化矩阵乘法与卷积运算,减少I/O操作。此外,TPU还采用了更大的片上内存,以此减少对DRAM的访问,从而更大程度地提升性能。
Google在2016年的Google I/O年会上首次公布了TPU。不过在此之前TPU已在Google内部的一些项目中使用了一年多,如Google街景服务、RankBrain以及其旗下DeepMind公司的围棋软件AlphaGo等都用到了TPU。而在2017年的Google I/O年会上,Google又公布了第二代TPU,并将其部署在Google云平台之上。第二代TPU的浮点运算能力高达每秒180万亿次别忘了更改运行类型!

import tensorflow as tf
import numpy as np
import os
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# add empty color dimension
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
def create_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(64, (3, 3), input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Activation('relu'))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
return model
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
with strategy.scope():
model = create_model()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy])
model.fit(
x_train.astype(np.float32), y_train.astype(np.float32),
epochs=5,
steps_per_epoch=60,
validation_data=(x_test.astype(np.float32), y_test.astype(np.float32)),
validation_freq=5
)4 为什么使用 TPU
通过使用 Cloud TPU ,我们可以大大提升 TensorFlow 进行机器学习训练和预测的性能,并能够灵活的帮助研究人员,开发人员和企业 TensorFlow 计算群集。

根据 Google 提供的数据显示,在 Google Cloud TPU Pod 上可以仅用 8 分钟就能够完成 ResNet-50 模型的训练。
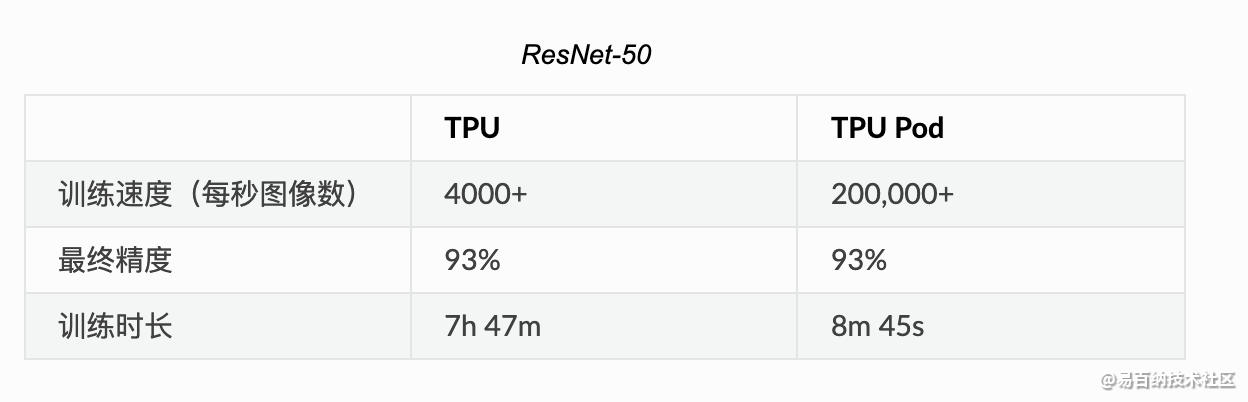
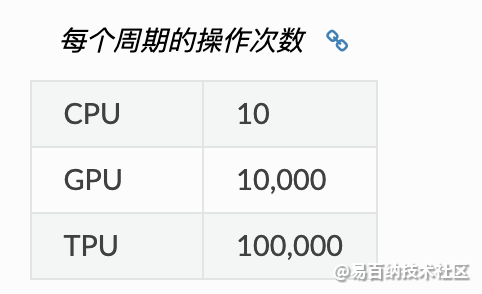
TPU 性能
根据研究显示,TPU 比现代 GPU 和 CPU 快 15 到 30 倍。同时,TPU 还实现了比传统芯片更好的能耗效率,算力能耗比值提高了 30 倍至 80 倍。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5324次2021-08-02 09:33:43
-
浏览量:6244次2021-07-15 10:44:33
-
浏览量:8550次2021-07-13 10:59:24
-
浏览量:1061次2023-07-05 10:15:58
-
浏览量:19868次2021-07-15 10:45:21
-
浏览量:1262次2023-09-06 17:53:04
-
浏览量:5371次2021-04-21 17:06:33
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:5535次2021-07-12 11:02:32
-
浏览量:285次2023-08-02 20:35:16
-
浏览量:6583次2021-08-03 11:36:37
-
浏览量:6411次2021-08-03 11:36:18
-
浏览量:5466次2021-04-12 16:28:50
-
浏览量:1211次2024-02-28 15:53:55
-
浏览量:5426次2021-04-27 16:30:07
-
浏览量:6448次2021-07-26 17:43:04
-
2023-09-28 11:13:27
-
浏览量:6245次2021-05-17 16:52:58
-
2023-01-12 11:47:40

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
