

【深度学习】LSTM神经网络解决COVID-19预测问题(二)

文章目录
1 概述
2 模型求解和检验
3 模型代码
4 模型评价与推广
5 参考- 1
- 2
- 3
- 4
- 5
- 6
1 概述
建立一个普适性较高的模型来有效预测疫情的达峰时间、每日增长量和最终报告病人数等,这能为国家实施防控措施提供重要的理论决策支持。对于附录1中的疫情确诊病例的时间序列time_series_19-covid-Confirmed.csv获取它第二列的国家信息和第五列之后疫情时间序列病例数,计算每一天病例增长量。我们首先建立了SIR传染病模型,然后搭建了LSTM循环神经网络,发现LSTM网络效果更优。基于问题一的分类结果,随机抽取不同等级的国家对LSTM神经网络进行了训练和评价,最后对全球的总确诊病例增长量也进行了预测。
2 模型求解和检验
在这一部分,我们使用了深度学习框架库Pytorch搭建了LSTM神经网络,利用第三方库Pandas对time_series_19-covid-Confirmed.csv进行数据处理,将全球每个国家疫情数据按时间递增顺序划分为7/3的训练集和测试集。
在模型的训练阶段,我们考虑到,随着时间增长每个国家的累计确诊病例数一定是递增的,这种递增的规律数据并不适合对LSTM网络进行训练,所以我们将训练集的标签改为后一天累计确诊病例数与前一天累计确诊病例数的差值△Y,应用2020年1月22日到2020年5月31日多个国家的最新疫情增长数据对本网络做80次迭代(Epoch)进行训练。
最后利用sklearn库对预测出的增长确诊病例数和真实的增长确诊病例数做评价,逐步得到train loss和test loss,很多国家的test loss值很小。结果表明模型效果很理想,具有普适性,检验结果在本问题中绘图展示。
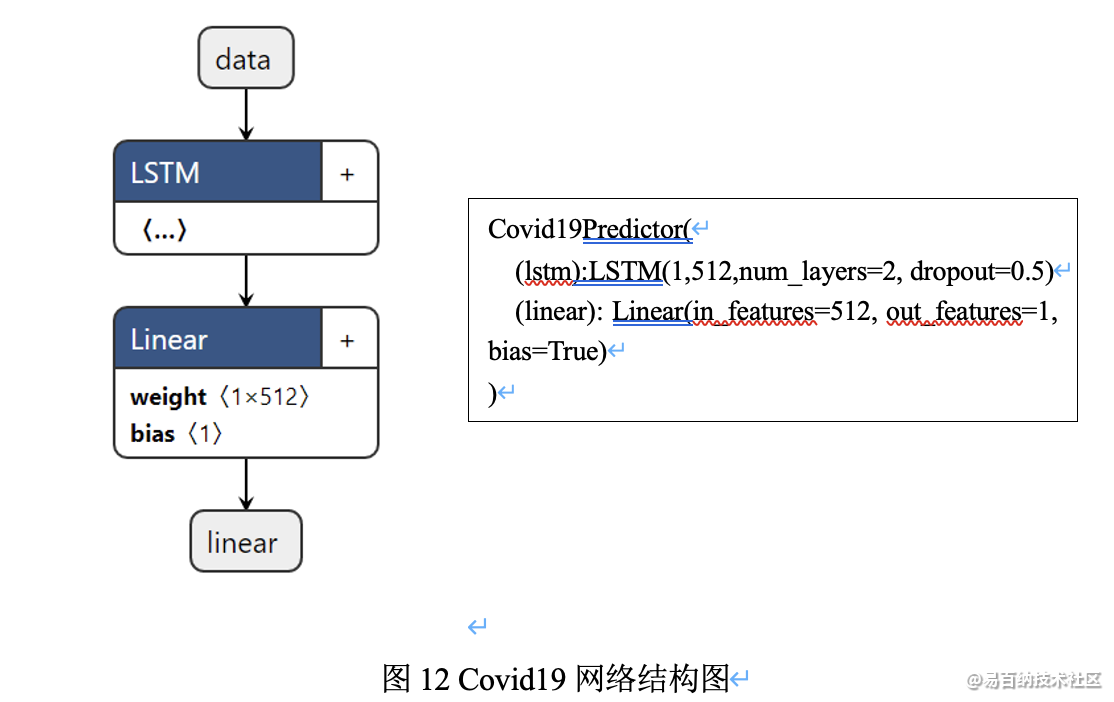
网络结构和参数如下图12所示,对于LSTM层input_name=data、input_size=1、hidden_size=512、num_layers=2、bias=true、mode=LSTM,而对于Linear层in_features=512、out_features=1、input_name=lstm、output_name=linear:
应用在全球疫情增长数据和一些主要国家,模型取得的效果较好,在问题(1)的分类基础上,在情况较好的国家中挑选中国进行预测,病例每日增长数情况如下图13所示:
Epoch 80 train loss: 1.488620638847351 test loss: 0.13394665718078613
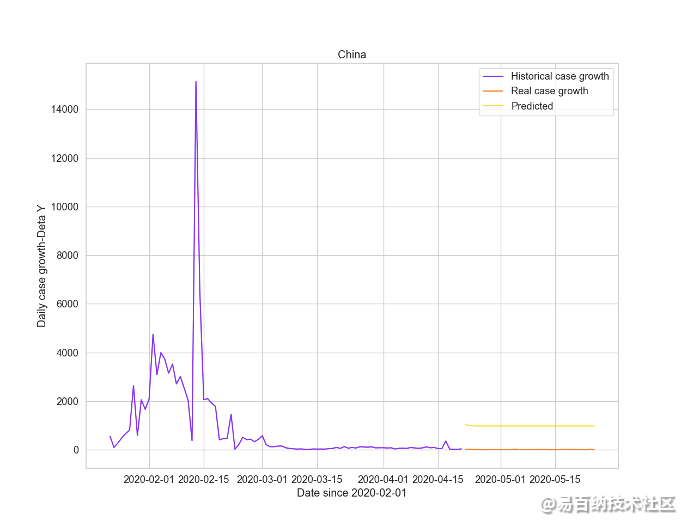
图13 中国病例每日增长数预测
在情况较好的国家中挑选马来西亚进行预测,病例每日增长数情况如下图14所示:
Epoch 80 train loss: 1.5871658325195312 test loss: 1.3702807426452637
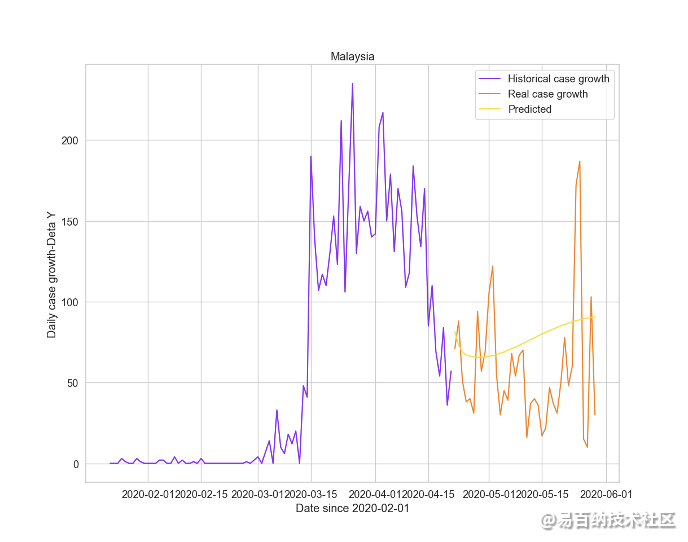
图14 马来西亚病例每日增长数预测
在情况中等的国家中挑选乌克兰进行预测,病例每日增长数情况如下图15所示:
Epoch 80 train loss: 0.5142446756362915 test loss: 0.7830316424369812
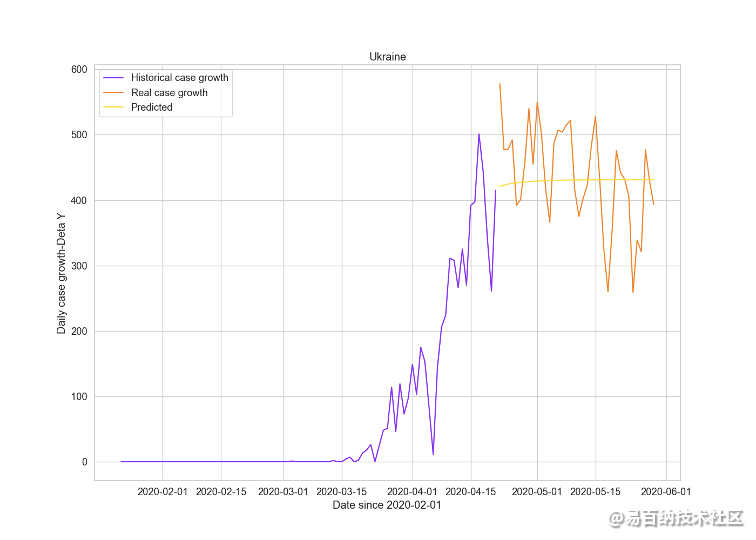
图15 乌克兰病例每日增长数预测
在情况比较重的国家中挑选英国进行预测,病例每日增长数情况如下图16所示:
Epoch 80 train loss: 0.36931702494621277 test loss: 0.704137980937957
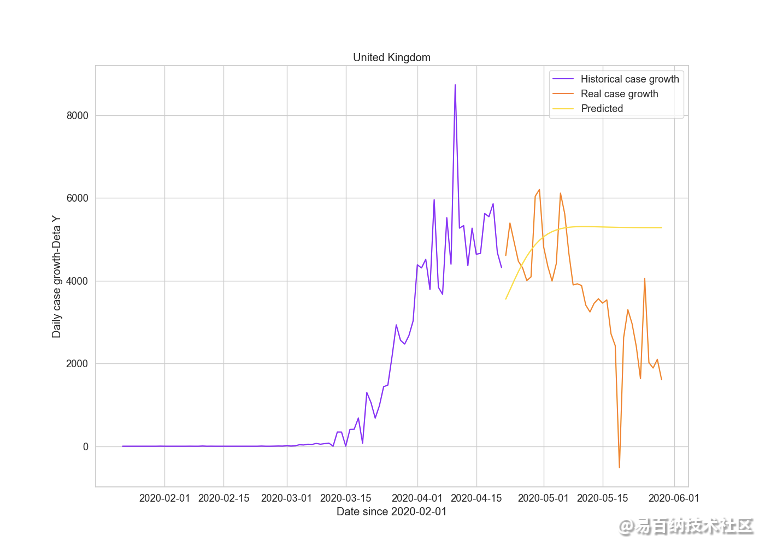
图16 英国病例每日增长数预测
在情况严重的国家中挑选美国进行预测,病例每日增长数情况如下图17所示:
Epoch 80 train loss: 1.488620638847351 test loss: 0.13394665718078613
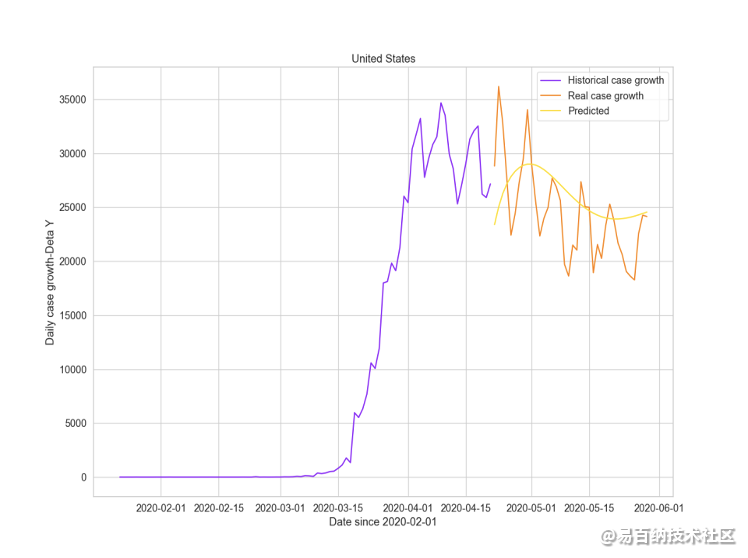
图17 美国病例每日增长数预测
最后对全球病例每日增长数情况进行预测,如下图18所示:
Epoch 80 train loss: 0.392549991607666 test loss: 0.35554710030555725
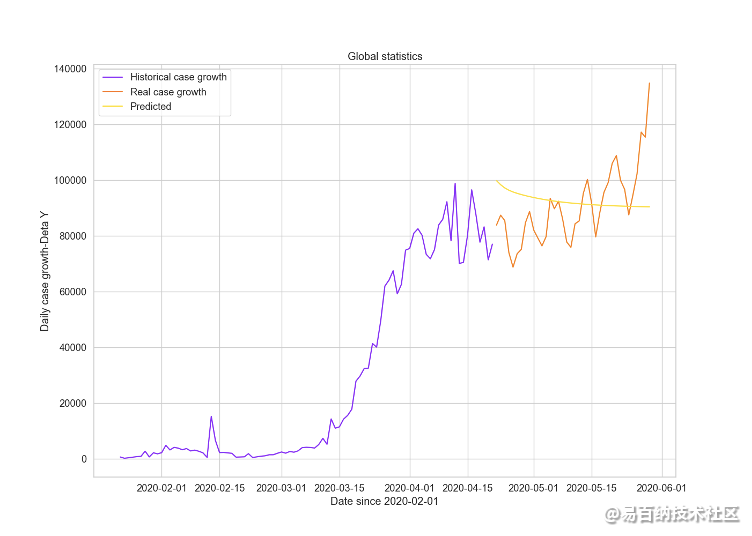
图18 全球病例每日增长数预测
我们观察以上几张图从2020年1月22日到2020年5月31日后四十天的预测结果,发现和真实的确诊病例增长量较为接近,网络的预测结果较为理想。在训练网络的过程中train loss和test loss均不断下降,模型精确度和泛化能力较高,网络能够平稳的学习。最后测试集和训练集上误差都比较低,针对不同的国家疫情增长数据取得效果各不相同。
3 模型代码
import torch
from torch import nn, optim
class CoronaVirusPredictor(nn.Module):
def __init__(self, n_features, n_hidden, seq_len, n_layers=2):
super(CoronaVirusPredictor, self).__init__()
self.n_hidden = n_hidden
self.seq_len = seq_len
self.n_layers = n_layers
self.lstm = nn.LSTM(
input_size=n_features,
hidden_size=n_hidden,
num_layers=n_layers,
dropout=0.5
)
self.linear = nn.Linear(in_features=n_hidden, out_features=1)
def reset_hidden_state(self):
self.hidden = (
torch.zeros(self.n_layers, self.seq_len, self.n_hidden),
torch.zeros(self.n_layers, self.seq_len, self.n_hidden)
)
def forward(self, sequences):
lstm_out, self.hidden = self.lstm(
sequences.view(len(sequences), self.seq_len, -1),
self.hidden
)
last_time_step = \
lstm_out.view(self.seq_len, len(sequences), self.n_hidden)[-1]
y_pred = self.linear(last_time_step)
return y_pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4 模型评价与推广
模型的优点
(1)本文所用的数据是使用requests2.21.0获取的百度疫情源和约翰·霍普金斯大学系统科学与工程中心发布在Github上的实时疫情更新数据。
(2)对于问题二的熵权-TOPSIS模型,TOPSIS能对事物进行综合评价,熵权法能根据数据的变化特点,来科学客观的分配因素权重,避免了主观因素的影响,因而它可以用来对TOPSIS方法进行修正。
(3)对于问题三把LSTM和SIR传染病模型做了对比,由于新冠病毒潜伏期的特点,我们最终选定了LSTM神经网络,LSTM非常适合解决与时间序列高度相关的问题,同时也解决了梯度反传过程梯度爆炸、梯度消失等问题。
模型的缺点
(1)层次分析法当指标过多时,权重难以确定。构造成对比较矩阵和模糊综合评价隶属函数的确定具有一定的主观性。
(2)熵权法是一种客观的赋值方法,它依据指标的变异程度的大小来分配权重,如果说指标的变动比较小,那么分配的权值也相应较低,因此较为局限。
模型的推广
本文对世界范围内主要国家的疫情发展和管控效果进行了分类和评价,并搭建了预测病例日增长量的神经网络,搜集了百度疫情源和CSSE中心的数据库,基于这两种数据通过数据处理和数学建模等手段,得出了一个合理的研究结果。
我们用层次分析法和模糊综合评价对主要国家的疫情发展特点及疫情状况进行分类,构建了熵权-TOPSIS模型确定世界范围内主要国家的疫情的管控效果,首先由熵权法确定指标的权重,然后将原始矩阵通过正向化处理得到正向矩阵,再对得到的矩阵进行标准化消除不同量纲的影响,之后通过确定正负理想解来计算所有指标与正负理想解之间的相对距离来排序并做出选择。最后我们利用python的dash库绘制了真实的疫情数据情况反应图,证明打分情况合理。
未来的研究方向,对于国家病例数的预测我们可以考虑使用LSTM的改进GRU神经网络[9],做更多的尝试,找到一个更适合新型冠状病毒发展规律的模型,得到有关峰值感染率和最佳结果预测,帮助一线工作人员为应对当前和未来的疫情状况做好最佳准备和应对措施。
5 参考
[1] 陈健,于俊乐.基AHP与模糊综合评价的“四位一体”实践教学研究[J].学理论,2014(21):206-208.
[2] 任江萍,凌锋,孙继民,陈恩富.部分国家新型冠状病毒肺炎疫情流行趋势分析[J/OL].预防医学:1-7[2020-06-13].http://kns.cnki.net/kcms/detail/33.1400. R.20200514.1031.002. html.
[3] 王煜,俞双恩,丁继辉,李倩倩,张梦婷,刘子鑫,陈凯文.基于熵权TOPSIS模型评价不同施氮水平下水稻灌排模式[J/OL].排灌机械工程学报:1-6[2020-06-13]. http://kns.cnki. net/kcms/ detail/32.1814.TH.20200607.1405.012.html.
[4] Zeyer A, Doetsch P, Voigtlaender P, et al. A comprehensive study of deep bidirectional LSTM RNNS for acoustic modeling in speech recognition[C]// IEEE International Conference on Acoustics, Speech and Signal Processing.New Orleans, USA,2017: 2462-2466.
[5] ]Ensheng Dong,Hongru Du,Lauren Gardner. An interactive web-based dashboard to track COVID-19 in real time[J]. The Lancet Infectious Diseases,2020,20(5).
[6] 盛华雄,吴琳,肖长亮.新冠肺炎疫情传播建模分析与预测[J].系统仿真学报,2020,32(05):759-766.
[7] Song Eunwoo, Soong F K, Kang Hong-Goo. Effective spectral and excitation modeling techniques for LSTM-RNN-Based speech synthesis systems[J]. IEEE/ACM Trans on Audio, Speech and Language Processing, 2017, 25(11): 2152-2161.
[8] Gao Lianli, Guo Zhao, Zhang Hanwang, et al. Video captioning with attention-based LSTM and Semantic consistency[J]. IEEE Trans on Multimedia, 2017, 19(9): 2045-2055.
[9] 何春蓉,朱江.基于注意力机制的GRU神经网络安全态势预测方法[J/OL].系统工程电子技术:1-11[2020-06-13].http://kns.cnki.net/kcms/detail/11.2422.TN.20200609.1857. 012.html.
[10] Hochreiter S, Schmid Huber, Jürgen. Long Short-Term Memory [J]. Neural Computation, 1997, 9(8):1735-1780.
[11] Jordan M I. Serial order: a parallel distributed processing approach[J]. Advanced in Psychology, 1997, 121(4): 471-495.
[12] Zeyer A, Doetsch P, Voigtlaender P, et al. A comprehensive study of deep bidirectional LSTM RNNS for acoustic modeling in speech recognition[C]// IEEE International Conference on Acoustics, Speech and Signal Processing.New Orleans, USA,2017: 2462-2466.
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:7231次2021-07-26 11:30:25
-
浏览量:4034次2018-02-14 10:30:11
-
浏览量:5596次2021-05-28 16:59:25
-
浏览量:4996次2021-04-23 14:09:37
-
浏览量:6676次2021-05-31 17:02:05
-
浏览量:5355次2021-08-13 15:39:02
-
浏览量:570次2024-02-01 14:20:47
-
浏览量:4711次2021-04-20 15:50:27
-
浏览量:537次2023-08-28 09:56:42
-
浏览量:865次2024-02-01 14:28:23
-
浏览量:8570次2021-05-28 16:59:43
-
浏览量:16594次2021-06-07 17:47:54
-
浏览量:873次2023-07-05 10:11:45
-
浏览量:4087次2021-05-14 09:47:57
-
浏览量:678次2023-10-07 17:46:34
-
浏览量:6347次2021-07-14 09:51:09
-
浏览量:4347次2021-04-19 14:54:23
-
浏览量:6313次2021-07-05 16:39:40
-
浏览量:504次2023-09-28 11:44:09

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
