

【深度学习】神经网络结构搜索(NAS)与多模态
【深度学习】神经网络结构搜索(NAS)与多模态

文章目录
1 概述
2 经典的NAS方法
2.1 搜索空间
2.2 搜索策略
2.3 性能评估
3 多模态
4 多模态表示学习 Multimodal Representation1 概述
神经网络结构搜索(Neural Architecture Search,NAS)是自动机器学习(Auto-ML)领域热点之一,通过设计经济高效的搜索方法,自动获取泛化能力强,硬件要求友好的神经网络,大量的解放研究员的创造力。在现今深度学习的浪潮中,“炼丹师”作为深度学习工作者自嘲的称号使得NAS注定将成为新的研究热点。

本文作者为东北大学自然语言处理实验室 2018 级研究生胡驰,他的研究方向包括神经网络结构搜索、自然语言处理。雷锋网 AI 科技评论经作者授权发表本文章。
近年来,深度学习的繁荣,尤其是神经网络的发展,颠覆了传统机器学习特征工程的时代,将人工智能的浪潮推到了历史最高点。然而,尽管各种神经网络模型层出不穷,但往往模型性能越高,对超参数的要求也越来越严格,稍有不同就无法复现论文的结果。而网络结构作为一种特殊的超参数,在深度学习整个环节中扮演着举足轻重的角色。在图像分类任务上大放异彩的 ResNet、在机器翻译任务上称霸的 Transformer 等网络结构无一不来自专家的精心设计。这些精细的网络结构的背后是深刻的理论研究和大量广泛的实验,这无疑给人们带来了新的挑战。
2 经典的NAS方法
正如蒸汽机逐渐被电机取代一般,神经网络结构的设计,正在从手工设计转型为机器自动设计。这一进程的标志事件发生在2016年,Google发表论文Neural Architecture Search with Reinforcement Learning,他们使用强化学习进行神经网络结构搜索(NAS),并在图像分类和语言建模任务上超越了此前手工设计的网络。如图1所示,经典的NAS方法使用RNN作为控制器(controller)产生子网络(child network),再对子网络进行训练和评估,得到其网络性能(如准确率),最后更新控制器的参数。然而,子网络的性能是不可导的,我们无法直接对控制器进行优化,幸好有强化学习这一利器,学者们采用了策略梯度的方法直接更新控制器参数。
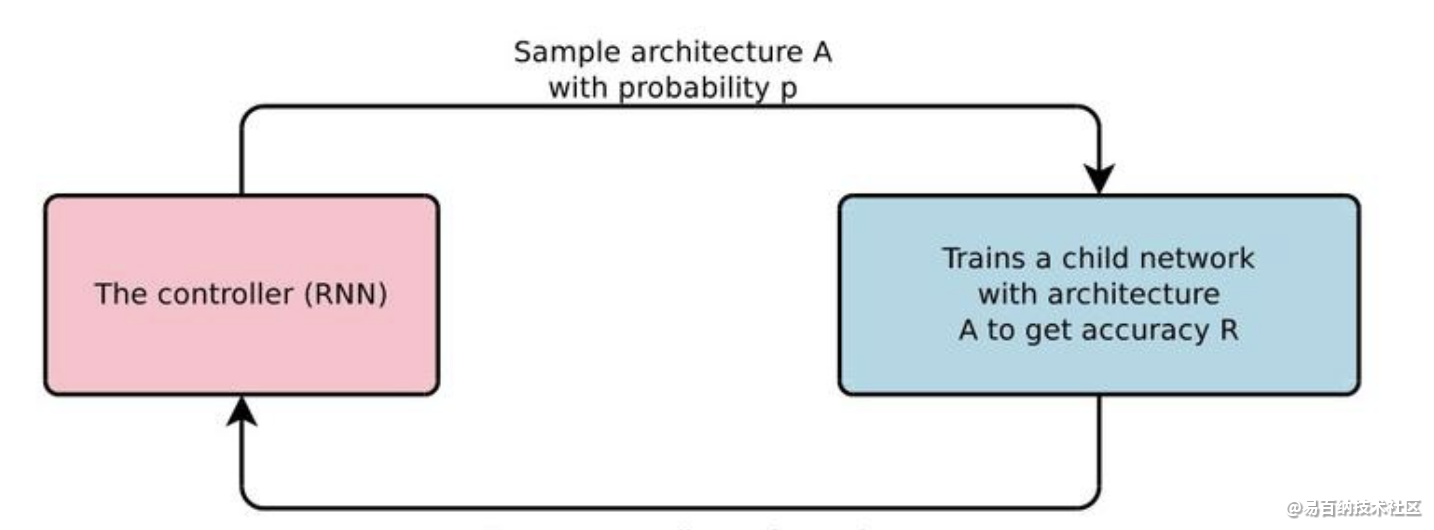
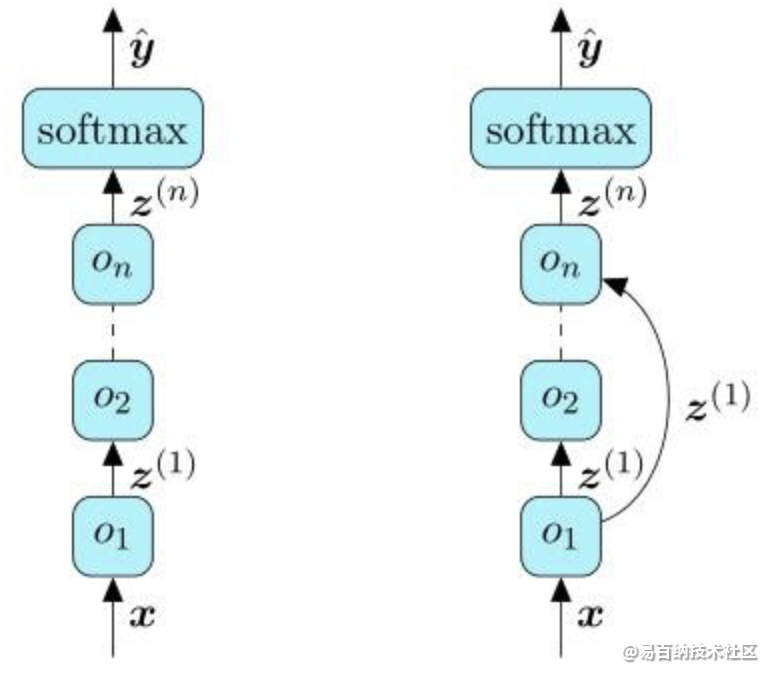
经典的NAS方法形式简单,并且取得了令人瞩目的效果,例如:在PTB语言建模任务上,NAS搜索出来的RNN模型击败了当时最先进的RHN网络,在测试集上取得了62.4的PPL(困惑度,越低越好)。然而受限于其离散优化的本质,这类方法有一个致命的缺点:太耗费计算资源了!例如,在CIFAR-10这么一个小数据集上进行搜索就需要800张GPU计算3到4周,受限于当时的深度学习框架,该论文甚至专门提出了基于参数服务器的分布式训练框架。如此巨大的算力需求实在是令人望洋兴叹,那有没有办法加速搜索,让NAS变得亲民呢?首先我们来思考一下NAS为何如此耗时,在NAS中,为了充分挖掘每个子网络的“潜力”,控制器每次采样一个子网络,都要初始化其网络权重从头训练,那每次采样不重新初始化是不是就能大大减少训练时间?为此,后面有人提出了ENAS,即Efficient NAS,顾名思义,其目的就是提高NAS的搜索效率。ENAS将搜索空间表示为一个有向无环图(DAG),其中的任一子图都代表了一个网络结构,每个节点代表了局部的计算,如矩阵乘法,而节点间的有向连接代表了信息的流动。所谓的权重共享,也就是不同的网络结构共享整个有向无环图节点上的参数。如图2所示,其中左边是一个有向无环图,假设红色的连接被控制器选中,我们就可以将其转换为右边的网络结构,其中包含4个计算节点,而输入输出是固定的节点,此外激活函数也是控制器选择出来的。ENAS提出的权重共享,极大地减少了搜索时间,使用一张GTX1080Ti只需10小时就可以完成在CIFAR-10上的搜索。
2.1 搜索空间
搜索空间,即待搜索网络结构的候选集合。搜索空间大致分为全局搜索空间和基于细胞的搜索空间,前者代表搜索整个网络结构,后者只搜索一些小的结构,通过堆叠、拼接的方法组合成完整的大网络。如图3(a)所示,早期的NAS的搜索空间是链式结构,搜索的内容只是网络的层数、每层的类型和对应的超参数。而后受到ResNet等网络的启发,跳跃连接、分支结构也被引入了搜索空间中,如图3(b)所示。搜索空间的复杂程度决定了网络结构的潜力,最近的一些工作表明,精心设计的搜索空间可以大大提高网络性能的下限,换言之,在这些空间里进行随机搜索也能取得不错的效果。目前最先进的方法都得益于其适当的搜索空间,而且几乎都是类似于图4中的细胞结构,既减少了搜索代价,也提高了结构的可迁移性。
2.2 搜索策略
搜索策略,即如何在搜索空间中进行选择,根据方法的不同,搜索策略大致分为三种。
-
基于强化学习的方法。强化学习被广泛应用于连续决策建模中,该方法通过智能体(agent)与环境交互,每次agent都会执行一些动作(action),并从环境中获得回馈,强化学习的目标就是让回馈最大化。NAS可以很自然地被建模为一个强化学习任务,最初的NAS使用RNN作为控制器来采样子网络,对子网络训练、评估后使用策略梯度方法更新RNN参数。这种方法简单可操作,易于理解和实现,然而基于策略梯度的优化效率是很低的,而且对子网络的采样优化会带来很大的变异性(策略梯度有时方差很大)。其实这也是无奈之举,RNN只能生成网络描述,因而无法通过模型的准确率直接对其进行优化。同样的策略也适用于各种其他的约束,如网络时延等各项衡量网络好坏的指标。
-
基于进化算法的方法。进化算法的由来已久,该方法受生物种群进化启发,通过选择、重组和变异这三种操作实现优化问题的求解。Google在2017年的论文Large-Scale Evolution of Image Classifiers首次将进化算法应用于NAS任务,并在图像分类任务上取得了不错的成绩。该方法首先对网络结构进行编码,维护结构的集合(种群),从种群中挑选结构训练并评估,留下高性能网络而淘汰低性能网络。接下来通过预设定的结构变异操作形成新的候选,通过训练和评估后加入种群中,迭代该过程直到满足终止条件(如达到最大迭代次数或变异后的网络性能不再上升)。后续的论文Regularized Evolution for Image Classifier Architecture Search对这一方法进行了改进,为候选结构引入年代的概念(aging),即将整个种群放在一个队列中,新加入一个元素,就移除掉队首的元素,这样使得进化更趋于年轻化,也取得了网络性能上的突破。
-
基于梯度的方法。前面的方法网络空间是离散的,它们都将NAS处理为黑盒优化问题,因而效率不尽人意。如果能将网络空间表示为连续分布,就能通过基于梯度的方法进行优化。CMU和Google的学者在DARTS: Differentiable Architecture Search一文中提出可微分结构搜索方法。该方法与ENAS相同,将网络空间表示为一个有向无环图,其关键是将节点连接和激活函数通过一种巧妙的表示组合成了一个矩阵,其中每个元素代表了连接和激活函数的权重,在搜索时使用了Softmax函数,这样就将搜索空间变成了连续空间,目标函数成为了可微函数。在搜索时,DARTS会遍历全部节点,使用节点上全部连接的加权进行计算,同时优化结构权重和网络权重。搜索结束后,选择权重最大的连接和激活函数,形成最终的网络,DARTS的整个搜索过程如图5所示。
2.3 性能评估
性能评估,即在目标数据集上评估网络结构的性能好坏。上一节讨论的搜索策略旨在找到某些性能(如准确度)最高的网络,为了引导它们的搜索过程,这些策略需要考虑如何评判给定架构的性能高低。最简单的方法是在训练数据上训练每个子网络并评估其在测试数据上的表现,然而,从头训练这么多结构太过耗时。上面提到过,ENAS、DARTS和NAO都使用了权重共享来代替重新初始化,并大大加速了搜索过程。除此之外,还有别的方法吗?当然是有的,例如评估时使用数据集的一小部分、减少网络参数、训练更少的轮数或者预测网络训练的趋势等,这和充分的训练相比大大加快了速度,然而由于超参数的选择,这样会带来新的问题:我们无法公平地对比网络结构。例如,有的结构在训练早期性能突出,但最终不如其他的结构,这样就会错过最优的网络。
3 多模态
在医学图象中,多模态数据因成像机理不同而能从多种层面提供信息。多模态图像分割包含重点问题为如何融合(fusion)不同模态间信息,
描述同一对象的多媒体数据。如互联网环境下描述某一特定对象的视频、图片、语音、文本 等信息。图即为典型的多模态信息形式。
来自不同传感器的同一类媒体数据。如医学影像学中不同的检查设备所产生的图像数据,包括B超(B-Scan ultrasonography)、计算机断层扫描(CT)、核磁共振(磁共振成像是断层成像的一种,它利用磁共振现象从人体中获得电磁信号,并重建出人体信息。1)等;物联网背景下不同传感器所检测到的同一对象数据等。
具有不同的数据结构特点、表示形式的表意符号与信息。如描述同一对象的结构化、非结构化的数据单元;描述同一数学概念的公式、逻辑符号、函数图及解释性文本;描述同一语义的词向量、词袋、知识图谱以及其它语义符号单元。
4 多模态表示学习 Multimodal Representation
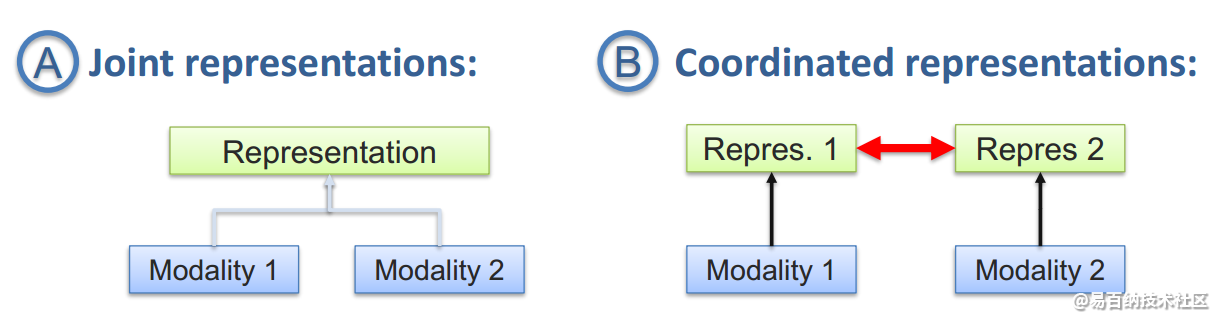
单模态的表示学习负责将信息表示为计算机可以处理的数值向量或者进一步抽象为更高层的特征向量,而多模态表示学习是指通过利用多模态之间的互补性,剔除模态间的冗余性,从而学习到更好的特征表示。主要包括两大研究方向:联合表示(Joint Representations)和协同表示(Coordinated Representations)。
联合表示将多个模态的信息一起映射到一个统一的多模态向量空间;
协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)。
利用多模态表示学习到的特征可以用来做信息检索,也可以用于的分类/回归任务。下面列举几个经典的应用。
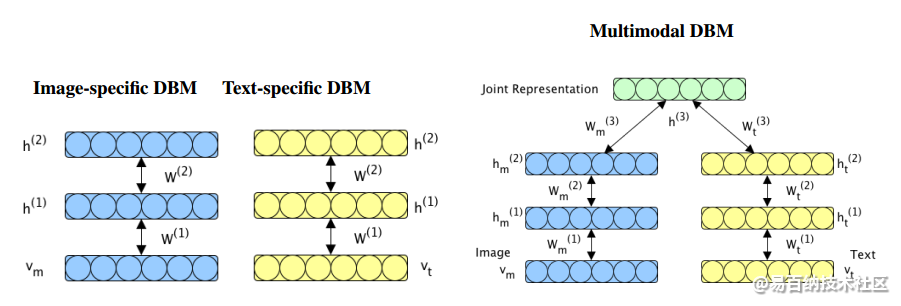
在来自 NIPS 2012 的 《Multimodal learning with deep boltzmann machines》一文中提出将 deep boltzmann machines(DBM) 结构扩充到多模态领域,通过 Multimodal DBM,可以学习到多模态的联合概率分布。
5 分享一个在线GPU(当然是colab pro)
我只能说 好香!!!!!
大家注册之后,直接选择升级就可以,过程有些繁琐哦!
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4333次2018-02-14 10:30:11
-
浏览量:5251次2021-04-23 14:09:37
-
浏览量:7043次2021-05-31 17:02:05
-
浏览量:9598次2021-05-13 12:53:50
-
浏览量:5595次2021-08-13 15:39:02
-
浏览量:4390次2021-05-14 09:47:57
-
浏览量:1143次2024-02-01 14:20:47
-
浏览量:4941次2021-04-20 15:50:27
-
浏览量:5985次2021-05-28 16:59:25
-
浏览量:9030次2021-05-28 16:59:43
-
浏览量:18030次2021-06-07 17:47:54
-
浏览量:881次2023-08-28 09:56:42
-
浏览量:1392次2024-02-01 14:28:23
-
浏览量:1125次2023-07-05 10:11:45
-
浏览量:8619次2021-05-19 16:25:40
-
浏览量:4581次2021-04-19 14:54:23
-
浏览量:6779次2021-07-05 16:39:40
-
浏览量:1549次2024-02-06 11:56:53
-
浏览量:793次2023-09-28 11:44:09

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
