

【深度学习】Transformer解决计算机视觉问题(卷中卷)

文章目录
1 前言
2 VIT
3 图像序列patches
4 哪种结构更高效?
5 DETR
5.1 architecture
5.2 Transformer
6 Set prediction loss
7 底层视觉任务如何使用 Transformer1 前言
将Transformer应用到CV任务中现在越来越多了,这里整理了一些相关的进展给大家。

Transformer结构已经在许多自然语言处理任务中取得了最先进的成果。Transformer 模型的一个主要的突破可能是今年年中发布的GPT-3,被授予NeurIPS2020“最佳论文“。
在计算机视觉领域,CNN自2012年以来已经成为视觉任务的主导模型。随着出现了越来越高效的结构,计算机视觉和自然语言处理越来越收敛到一起,使用Transformer来完成视觉任务成为了一个新的研究方向,以降低结构的复杂性,探索可扩展性和训练效率。
以下是几个在相关工作中比较知名的项目:
DETR(End-to-End Object Detection with Transformers),使用Transformers进行物体检测和分割。
Vision Transformer (AN IMAGE IS WORTH 16X16 WORDS: Transformer FOR IMAGE RECOGNITION AT SCALE),使用Transformer 进行图像分类。
Image GPT(Generative Pretraining from Pixels),使用Transformer进行像素级图像补全,就像其他GPT文本补全一样。
End-to-end Lane Shape Prediction with Transformers,在自动驾驶中使用Transformer进行车道标记检测
结构
总的来说,在CV中采用Transformer的相关工作中主要有两种模型架构。一种是纯Transformer结构,另一种是将CNNs/主干网与Transformer相结合的混合结构。
纯Transformer
混合型:(CNNs+ Transformer)
Vision Transformer是基于完整的自注意力的Transformer结构没有使用CNN,而DETR是使用混合模型结构的一个例子,它结合了卷积神经网络(CNNs)和Transformer。
2 VIT
Vision Transformer(ViT)将纯Transformer架构直接应用到一系列图像块上进行分类任务,可以取得优异的结果。它在许多图像分类任务上也优于最先进的卷积网络,同时所需的预训练计算资源大大减少(至少减少了4倍)。
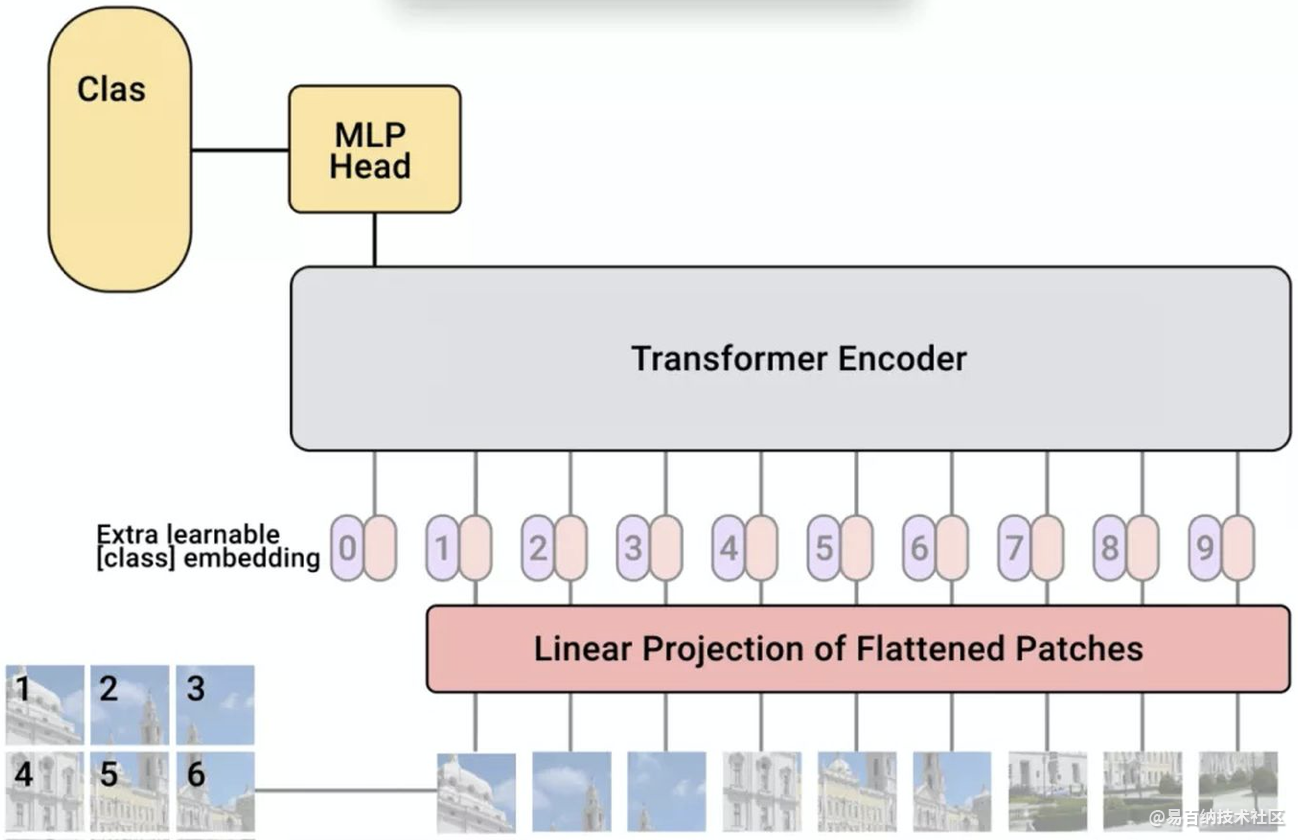
3 图像序列patches
它们是如何将图像分割成固定大小的小块,然后将这些小块的线性投影连同它们的图像位置一起输入变压器的。然后剩下的步骤就是一个干净的和标准的Transformer编码器和解码器。
在图像patch的嵌入中加入位置嵌入,通过不同的策略在全局范围内保留空间/位置信息。在本文中,他们尝试了不同的空间信息编码方法,包括无位置信息编码、1D/2D位置嵌入编码和相对位置嵌入编码。
4 哪种结构更高效?
如一开始所提到的,使用transformer进行计算机视觉的架构设计也有不同,有的用Transformer完全取代CNNs (ViT),有的部分取代,有的将CNNs与transformer结合(DETR)。下面的结果显示了在相同的计算预算下各个模型结构的性能。
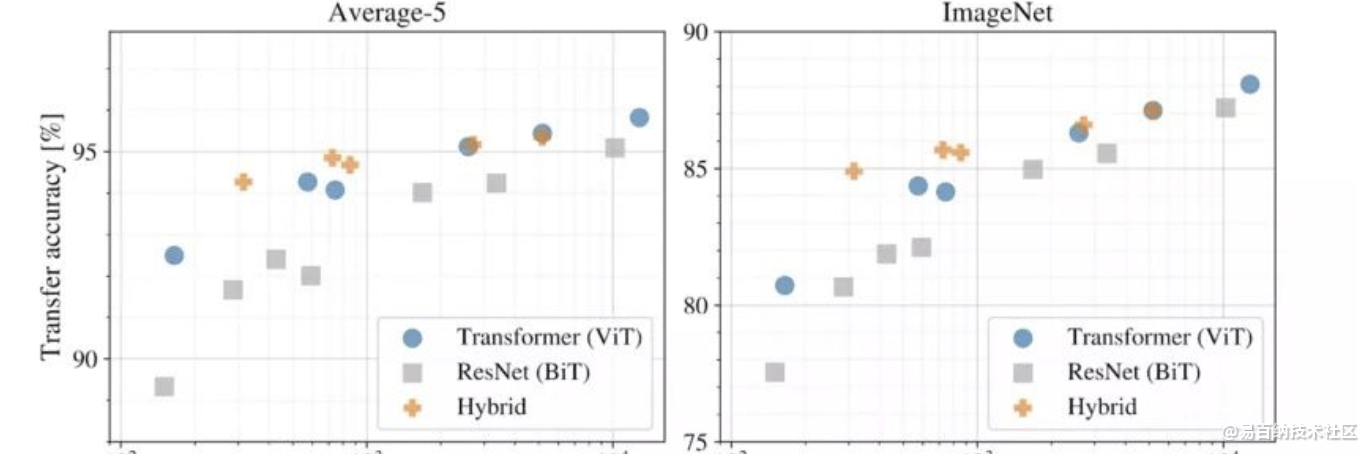
不同模型架构的性能与计算成本
以上实验表明:
纯Transformer架构(ViT)在大小和计算规模上都比传统的CNNs (ResNet BiT)更具效率和可扩展性
混合架构(CNNs + Transformer)在较小的模型尺寸下性能优于纯Transformer,当模型尺寸较大时性能非常接近
5 DETR
DETR使用set loss function作为监督信号来进行端到端训练,然后同时预测所有目标,其中set loss function使用bipartite matching算法将pred目标和gt目标匹配起来。直接将目标检测任务看成set prediction问题,使训练过程变的简洁,并且避免了anchor、NMS等复杂处理。
DETR主要有两个部分:architecture和set prediction loss。
5.1 architecture
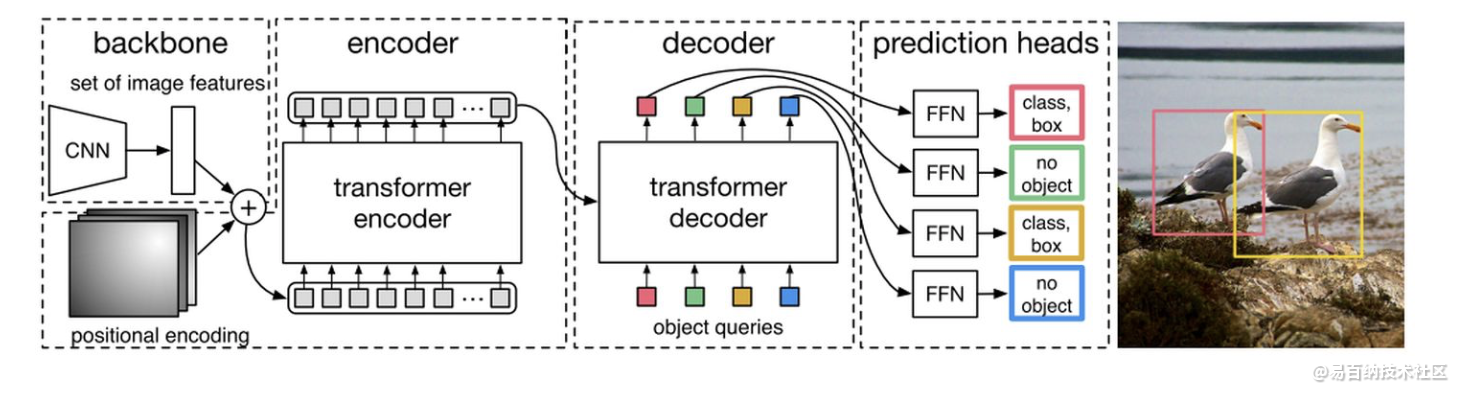
DETR先用CNN将输入图像embedding成一个二维表征,然后将二维表征转换成一维表征并结合positional encoding一起送入encoder,decoder将少量固定数量的已学习的object queries(可以理解为positional embeddings)和encoder的输出作为输入。最后将decoder得到的每个output embdding传递到一个共享的前馈网络(FFN),该网络可以预测一个检测结果(包括类和边框)或着“没有目标”的类。
5.2 Transformer
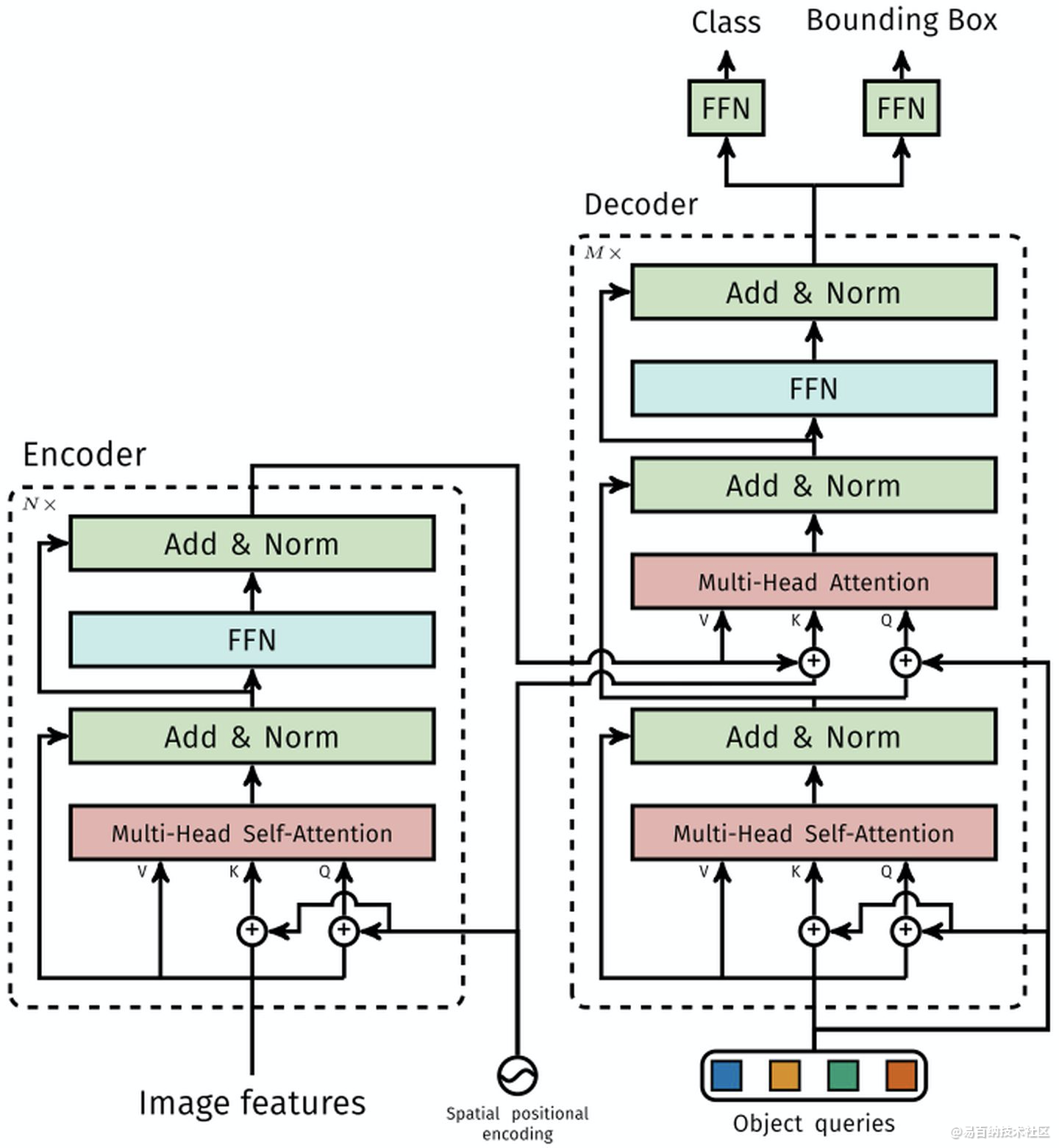
1.1.1 Encoder
将Backbone输出的feature map转换成一维表征,得到特征图,然后结合positional encoding作为Encoder的输入。每个Encoder都由Multi-Head Self-Attention和FFN组成。
和Transformer Encoder不同的是,因为Encoder具有位置不变性,DETR将positional encoding添加到每一个Multi-Head Self-Attention中,来保证目标检测的位置敏感性。
1.1.2 Decoder
因为Decoder也具有位置不变性,Decoder的N个object query(可以理解为学习不同object的positional embedding)必须是不同,以便产生不同的结果,并且同时把它们添加到每一个Multi-Head Attention中。
1.1.3 FFN
FFN由3层perceptron和一层linear projection组成。FFN预测出box的归一化中心坐标、长、宽和class。
6 Set prediction loss

7 底层视觉任务如何使用 Transformer
在自然语言任务中,Transformer 的输入是单词序列,图像数据无法作为输入。解决如何使用 Transformer 处理图像的问题是将 Transformer 应用在视觉任务的第一步。
不同于高层视觉语义任务的目标是进行特征抽取,底层视觉任务的输入和输出均为图像。除超分辨率任务之外,大多数底层视觉任务的输入和输出维度相同。相比于高层视觉任务,输入和输出维度匹配这一特性使底层视觉任务更适合由 Transformer 处理。
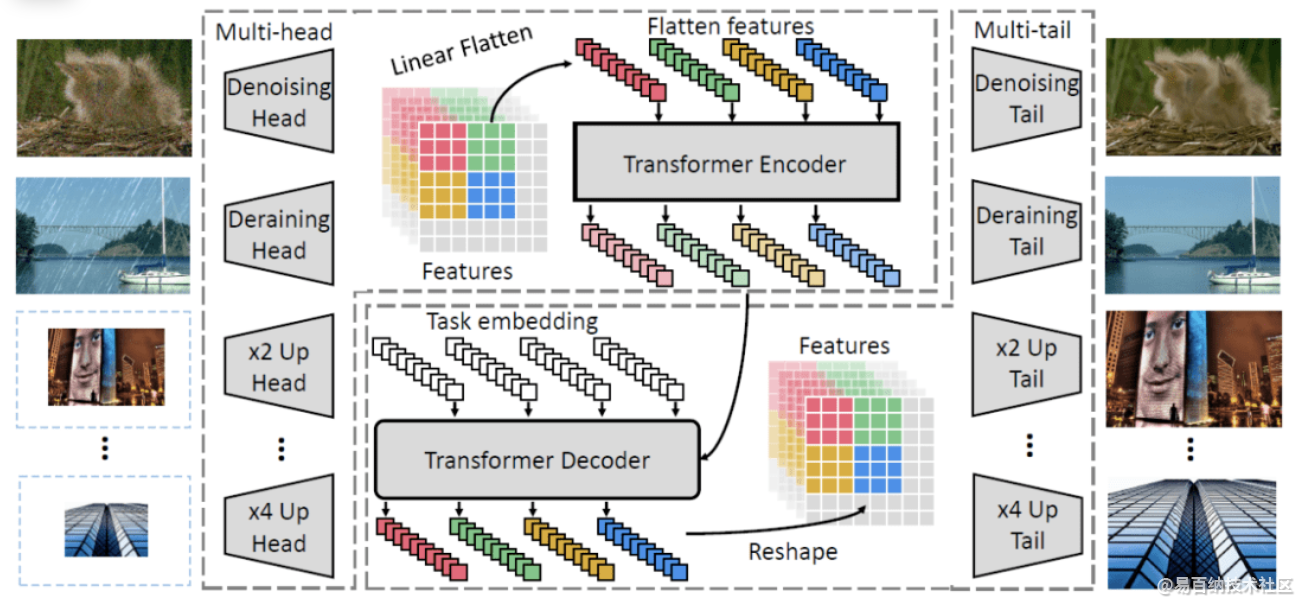
具体而言,研究者在特征图处理阶段引入 Transformer 模块,而图像维度匹配则交给了头结构与尾结构,如图所示:
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6551次2021-06-07 11:48:50
-
浏览量:3730次2020-02-27 10:34:09
-
浏览量:1301次2024-01-12 11:39:24
-
浏览量:1041次2023-01-13 11:31:19
-
浏览量:2580次2024-03-14 18:20:47
-
浏览量:5582次2020-12-29 19:37:20
-
浏览量:3002次2019-06-17 15:02:48
-
浏览量:7625次2020-12-21 20:12:30
-
浏览量:6022次2020-12-21 16:50:21
-
浏览量:7287次2021-01-05 18:32:12
-
浏览量:1170次2023-11-30 09:18:58
-
2020-12-14 18:16:24
-
2021-01-12 21:31:51
-
浏览量:5266次2021-01-11 15:33:50
-
浏览量:4759次2021-01-08 01:04:31
-
浏览量:5751次2021-01-05 22:14:42
-
浏览量:6029次2021-01-02 22:50:35
-
浏览量:6545次2020-12-29 14:13:00
-
浏览量:5224次2021-01-19 16:45:32

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
