

【深度学习】基于注意力机制的Transformer处理医疗影像

文章目录
1 前言
2 Self-Attention
3 Multi-Head Attention
4 MedT:用于医学图像分割的Transformer
5 基于Transformer的端到端视频实例分割方法1 前言
注意力(Attention)机制由Bengio团队与2014年提出并在近年广泛的应用在深度学习中的各个领域,例如在计算机视觉方向用于捕捉图像上的感受野,或者NLP中用于定位关键token或者特征。谷歌团队近期提出的用于生成词向量的BERT算法在NLP的11项任务中取得了效果的大幅提升,堪称2018年深度学习领域最振奋人心的消息。而BERT算法的最重要的部分便是本文中提出的Transformer的概念。
正如论文的题目所说的,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力;
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。论文中给出Transformer的定义是:Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
2 Self-Attention
Self-Attention是Transformer最核心的内容,然而作者并没有详细讲解,下面我们来补充一下作者遗漏的地方。回想Bahdanau等人提出的用Attention,其核心内容是为输入向量的每个单词学习一个权重,例如在下面的例子中我们判断it代指的内容,
The animal didn't cross the street because it was too tired
通过加权之后可以得到类似图8的加权情况,在讲解self-attention的时候我们也会使用图8类似的表示方式

3 Multi-Head Attention

优点:(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
4 MedT:用于医学图像分割的Transformer
并提出局部-全局训练策略(LoGo),进一步提高性能,优于Res-UNet、U-Net++等网络,代码刚刚开源!

在过去的十年中,深度卷积神经网络已被广泛用于医学图像分割,并显示出足够的性能。但是,由于卷积架构中存在固有的inductive biases,因此他们对图像中的远程依存关系缺乏了解。
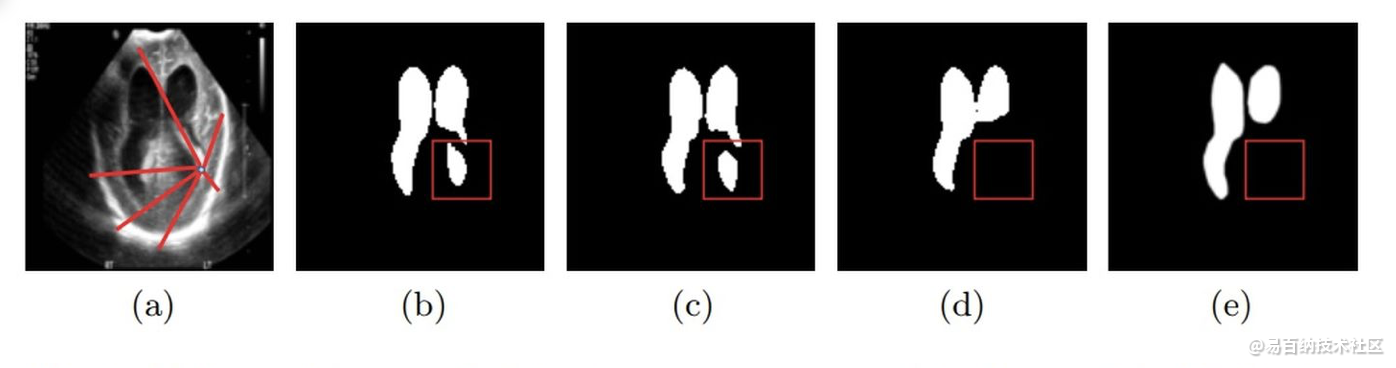
最近提出的利用自注意力机制的基于Transformer的体系结构对远程依赖项进行编码,并学习高度表达的表示形式。这促使我们探索基于Transformer的解决方案,并研究将基于Transformer的网络体系结构用于医学图像分割任务的可行性。提出用于视觉应用的大多数现有的基于Transformer的网络体系结构都需要大规模的数据集才能正确地进行训练。但是,与用于视觉应用的数据集相比,对于医学成像而言,数据样本的数量相对较少,从而难以有效地训练用于医学应用的Transformer。
为此,我们提出了Gated Axial-Attention模型,通过在自注意力模块中引入附加的控制机制来扩展现有体系结构。
此外,为了有效地在医学图像上训练模型,我们提出了局部-全局训练策略(LoGo),可以进一步提高性能。具体来说,我们对整个图像和patch进行操作以分别学习全局和局部特征。
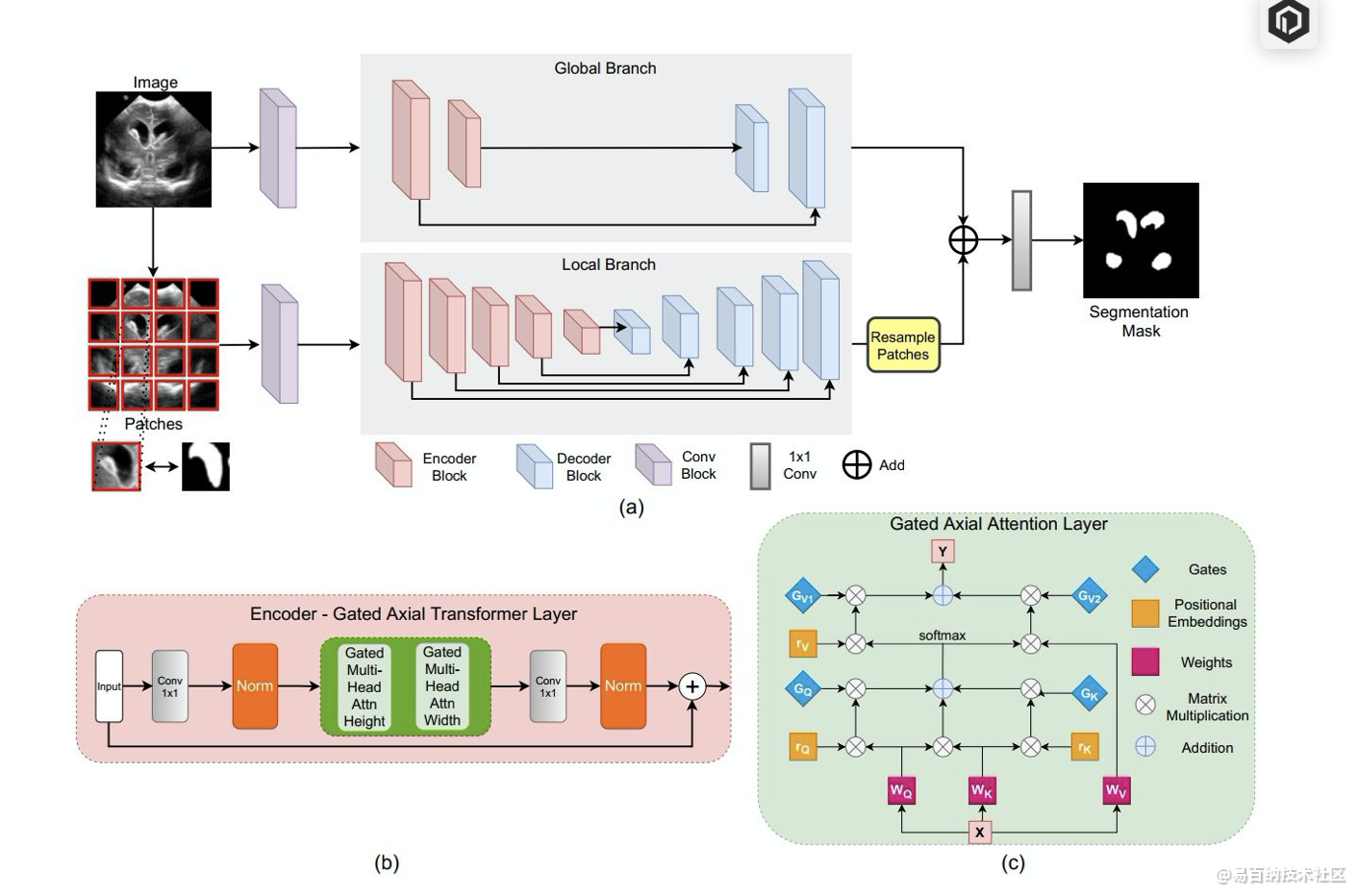
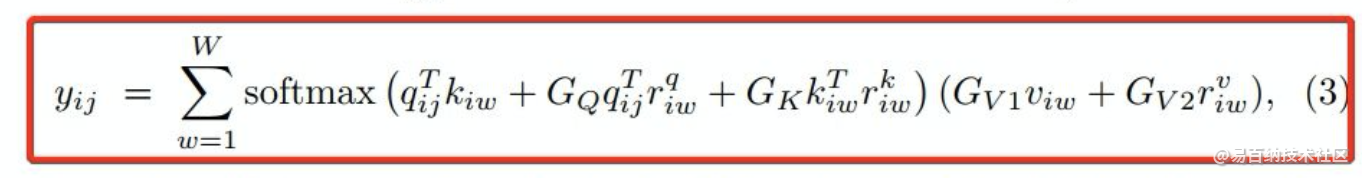

实验结果
在三个不同的医学图像分割数据集上对提出的Medical Transformer(MedT)进行了评估,结果表明,与基于卷积和其他基于transformer的其他架构相比,它具有更好的性能。

5 基于Transformer的端到端视频实例分割方法
背景
图像的实例分割指的是对静态图像中感兴趣的物体进行检测和分割的任务。视频是包含多帧图像的信息载体,相对于静态图像来说,视频的信息更为丰富,因而建模也更为复杂。不同于静态图像仅含有空间的信息,视频同时含有时间维度的信息,因而更接近对真实世界的刻画。其中,视频的实例分割指的是对视频中感兴趣的物体进行检测、分割和跟踪的任务。如图1所示,第一行为给定视频的多帧图像序列,第二行为视频实例分割的结果,其中相同颜色对应同一个实例。视频实例分割不光要对单帧图像中的物体进行检测和分割,而且要在多帧的维度下找到每个物体的对应关系,即对其进行关联和跟踪。

相关工作
现有的视频实例分割算法通常为包含多模块、多阶段的复杂流程。最早的Mask Track R-CNN[1]算法同时包含实例分割和跟踪两个模块,通过在图像实例分割算法Mask R-CNN[2]的网络之上增加一个跟踪的分支实现,该分支主要用于实例特征的提取。在预测阶段,该方法利用外部Memory模块进行多帧实例特征的存储,并将该特征作为实例关联的一个要素进行跟踪。该方法的本质仍然是单帧的分割加传统方法进行跟踪关联。Maskprop[3]在Mask Track R-CNN的基础上增加了Mask Propagation的模块以提升分割Mask生成和关联的质量,该模块可以实现当前帧提取的mask到周围帧的传播,但由于帧的传播依赖于预先计算的单帧的分割Mask,因此要得到最终的分割Mask需要多步的Refinement。该方法的本质仍然是单帧的提取加帧间的传播,且由于其依赖多个模型的组合,方法较为复杂,速度也更慢。
Stem-seg[4]将视频实例分割划分为实例的区分和类别的预测两个模块。为了实现实例的区分,模型将视频的多帧Clip构建为3D Volume,通过对像素点的Embedding特征进行聚类实现不同物体的分割。由于上述聚类过程不包含实例类别的预测,因此需要额外的语义分割模块提供像素的类别信息。根据以上描述,现有的算法大多沿袭单帧图像实例分割的思想,将视频实例分割任务划分为单帧的提取和多帧的关联多个模块,针对单个任务进行监督和学习,处理速度较慢且不利于发挥视频时序连续性的优势。本文旨在提出一个端到端的模型,将实例的检测、分割和跟踪统一到一个框架下实现,有助于更好地挖掘视频整体的空间和时序信息,且能够以较快的速度解决视频实例分割的问题。
VisTR算法介绍
重新定义问题
首先,我们对视频实例分割这一任务进行了重新的思考。相较于单帧图像,视频含有关于每个实例更为完备和丰富的信息,比如不同实例的轨迹和运动模态,这些信息能够帮助克服单帧实例分割任务中一些比较困难的问题,比如外观相似、物体邻近或者存在遮挡的情形等。另一方面,多帧所提供的关于单个实例更好的特征表示也有助于模型对物体进行更好的跟踪。因此,我们的方法旨在实现一个端到端对视频实例目标进行建模的框架。为了实现这一目标,我们第一个思考是:视频本身是序列级别的数据,能否直接将其建模为序列预测的任务?比如,借鉴自然语言处理(NLP)任务的思想,将视频实例分割建模为序列到序列(Seq2Seq)的任务,即给定多帧图像作为输入,直接输出多帧的分割Mask序列,这时需要一个能够同时对多帧进行建模的模型。
第二个思考是:视频的实例分割实际同时包含实例分割和目标跟踪两个任务,能否将其统一到一个框架下实现?针对这个我们的想法是:分割本身是像素特征之间相似度的学习,而跟踪本质是实例特征之间相似度的学习,因此理论上他们可以统一到同一个相似度学习的框架之下。
基于以上的思考,我们选取了一个同时能够进行序列的建模和相似度学习的模型,即自然语言处理中的Transformer[5]模型。Transformer本身可以用于Seq2Seq的任务,即给定一个序列,可以输入一个序列。并且该模型十分擅长对长序列进行建模,因此非常适合应用于视频领域对多帧序列的时序信息进行建模。其次,Transformer的核心机制,自注意力模块(Self-Attention),可以基于两两之间的相似度来进行特征的学习和更新,使得将像素特征之间相似度以及实例特征之间相似度统一在一个框架内实现成为可能。以上的特性使得Transformer成为VIS任务的恰当选择。除此之外,Transformer已经有被应用于计算机视觉中进行目标检测的实践DETR[6]。因此我们基于transformer设计了视频实例分割(VIS)的模型VisTR。
VisTR算法流程
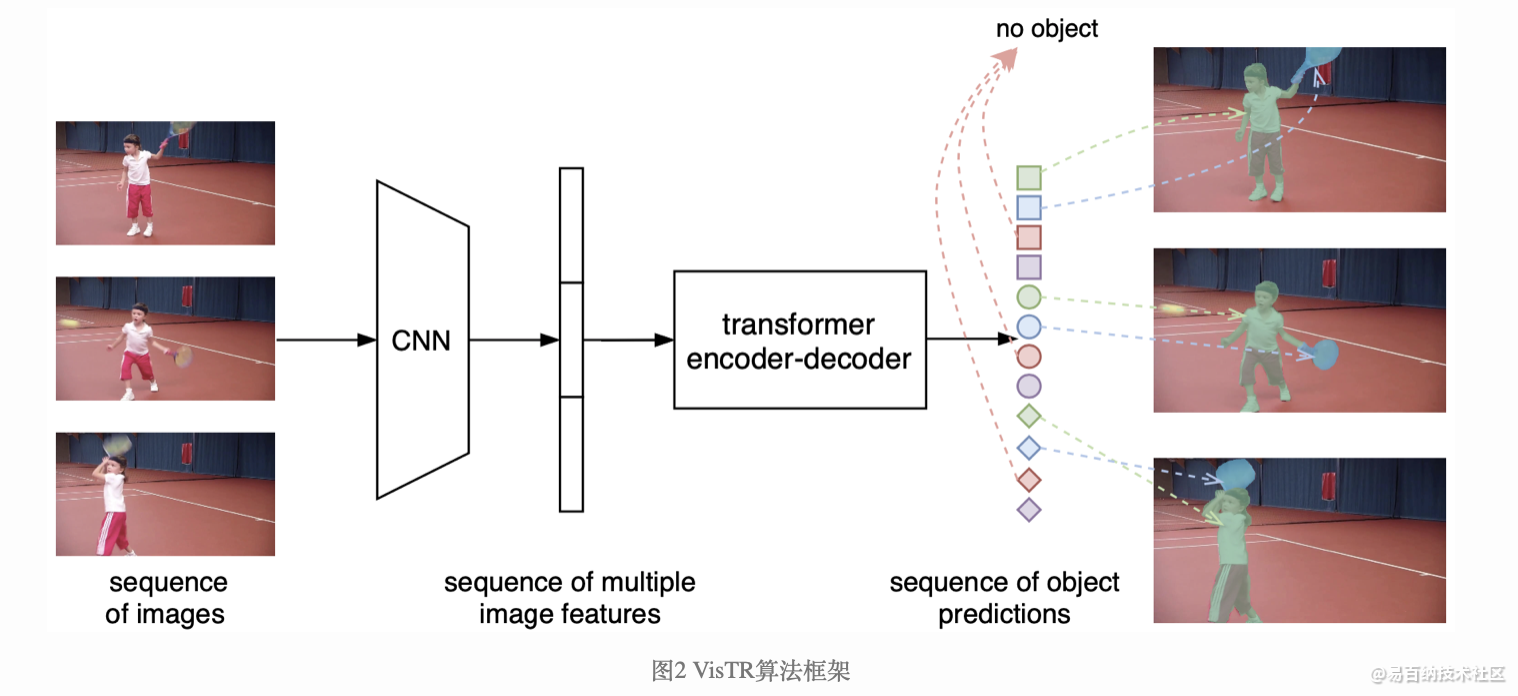
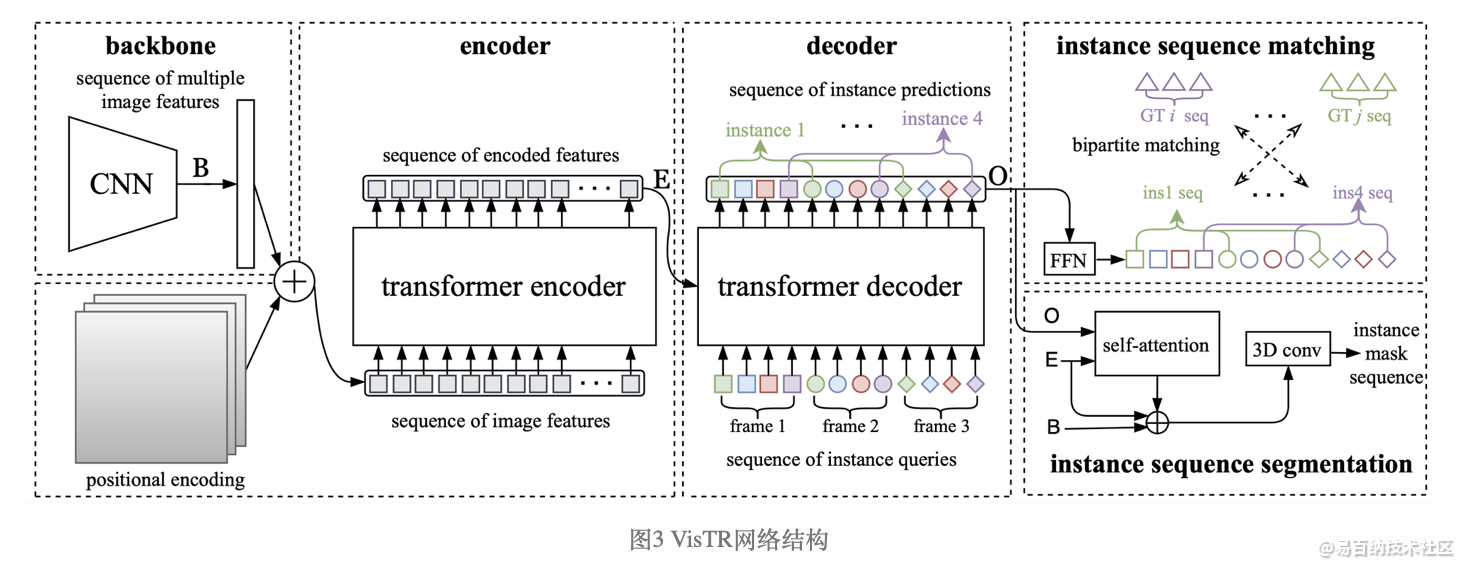
遵照上述思想,VisTR的整体框架如图2所示。图中最左边表示输入的多帧原始图像序列(以三帧为例),右边表示输出的实例预测序列,其中相同形状对应同一帧图像的输出,相同颜色对应同一个物体实例的输出。给定多帧图像序列,首先利用卷积神经网络(CNN)进行初始图像特征的提取,然后将多帧的特征结合作为特征序列输入Transformer进行建模,实现序列的输入和输出。
不难看出,首先,VisTR是一个端到端的模型,即同时对多帧数据进行建模。建模的方式即:将其变为一个Seq2Seq的任务,输入多帧图像序列,模型可以直接输出预测的实例序列。虽然在时序维度多帧的输入和输出是有序的,但是单帧输入的实例的序列在初始状态下是无序的,这样仍然无法实现实例的跟踪关联,因此我们强制使得每帧图像输出的实例的顺序是一致的(用图中同一形状的符号有着相同的颜色变化顺序表示),这样只要找到对应位置的输出,便可自然而然实现同一实例的关联,无需任何后处理操作。为了实现此目标,需要对属于同一个实例位置处的特征进行序列维度的建模。针对性地,为了实现序列级别的监督,我们提出了Instance Sequence Matching的模块。同时为了实现序列级别的分割,我们提出了Instance Sequence Segmentation的模块。端到端的建模将视频的空间和时间特征当做一个整体,可以从全局的角度学习整个视频的信息,同时Transformer所建模的密集特征序列又能够较好的保留细节的信息。
VisTR网络结构
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5195次2021-08-09 16:10:30
-
浏览量:5628次2021-08-09 16:10:57
-
浏览量:7051次2021-08-09 16:09:53
-
浏览量:353次2023-07-24 11:00:24
-
浏览量:2524次2023-12-01 14:35:39
-
浏览量:11694次2021-06-25 15:00:55
-
浏览量:14477次2021-07-08 09:43:47
-
浏览量:5874次2021-06-23 15:25:25
-
浏览量:147次2023-08-23 09:02:52
-
浏览量:14753次2021-06-15 10:27:34
-
浏览量:7723次2021-06-24 10:38:30
-
浏览量:6752次2021-05-17 16:48:29
-
浏览量:7754次2021-06-07 09:27:26
-
浏览量:8745次2021-06-03 11:03:40
-
浏览量:5853次2021-06-22 16:53:40
-
浏览量:15051次2021-05-04 20:16:03
-
浏览量:5324次2021-08-02 09:33:43
-
浏览量:285次2023-08-02 20:35:16
-
浏览量:13576次2021-05-12 12:35:30

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
