

【深度学习】深入浅出transformer内部结构

【深度学习】深入浅出transformer内部结构
文章目录
1 概述
2 Self-Attention与Transformer
3 Feed Forward Neural Network
4 encoder-decoder attention- 1
- 2
- 3
- 4
- 5
1 概述
Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。
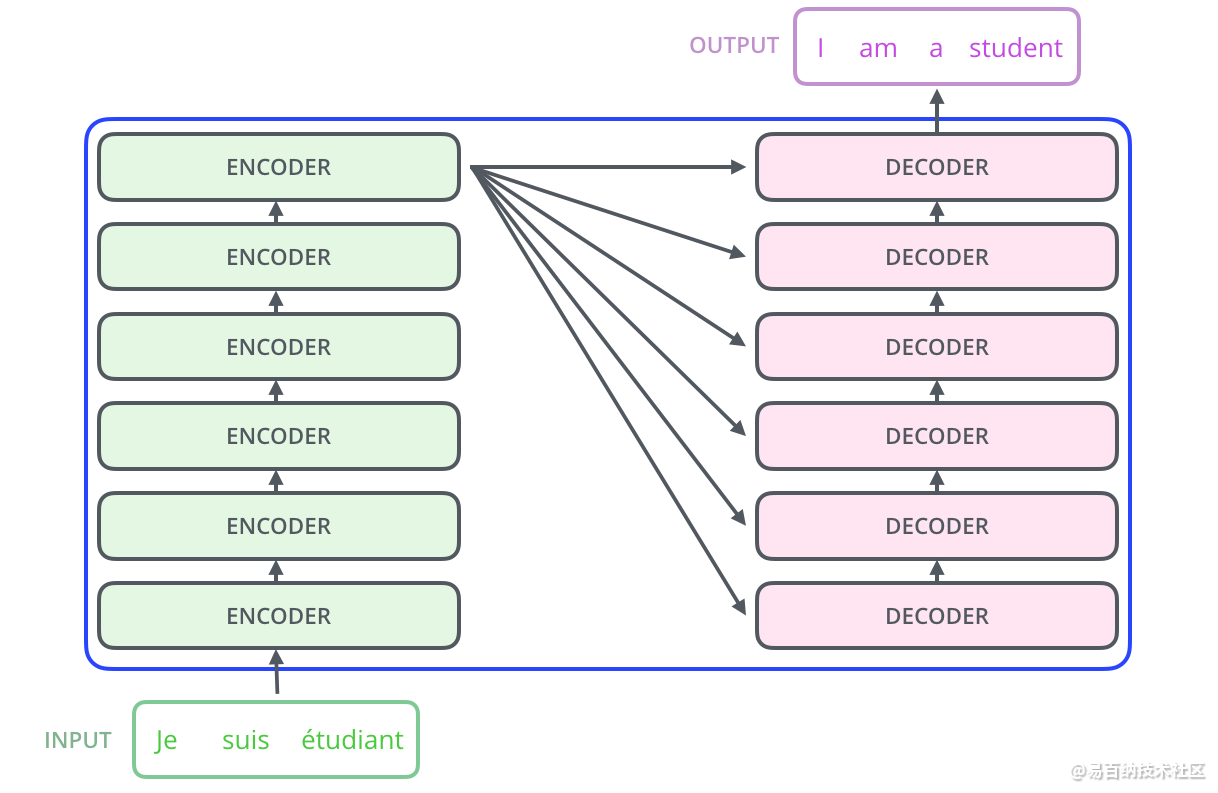
Transformer的Encoder和Decoder均由6个block堆叠而成。
Encoder的结构如下图所示
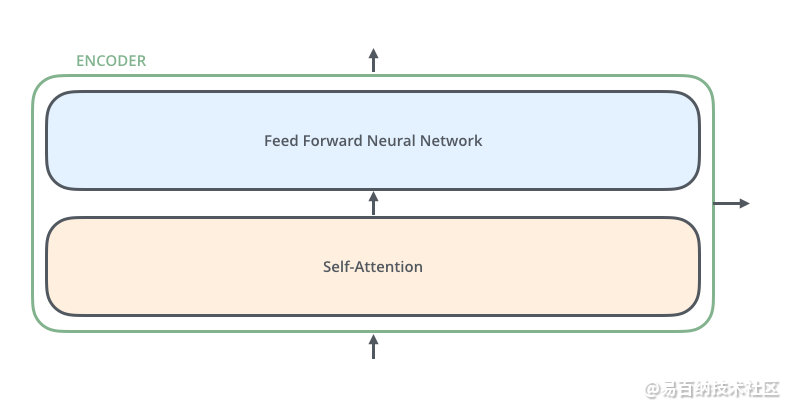
2 Self-Attention与Transformer
Transformer模型的整体结构如下图所示
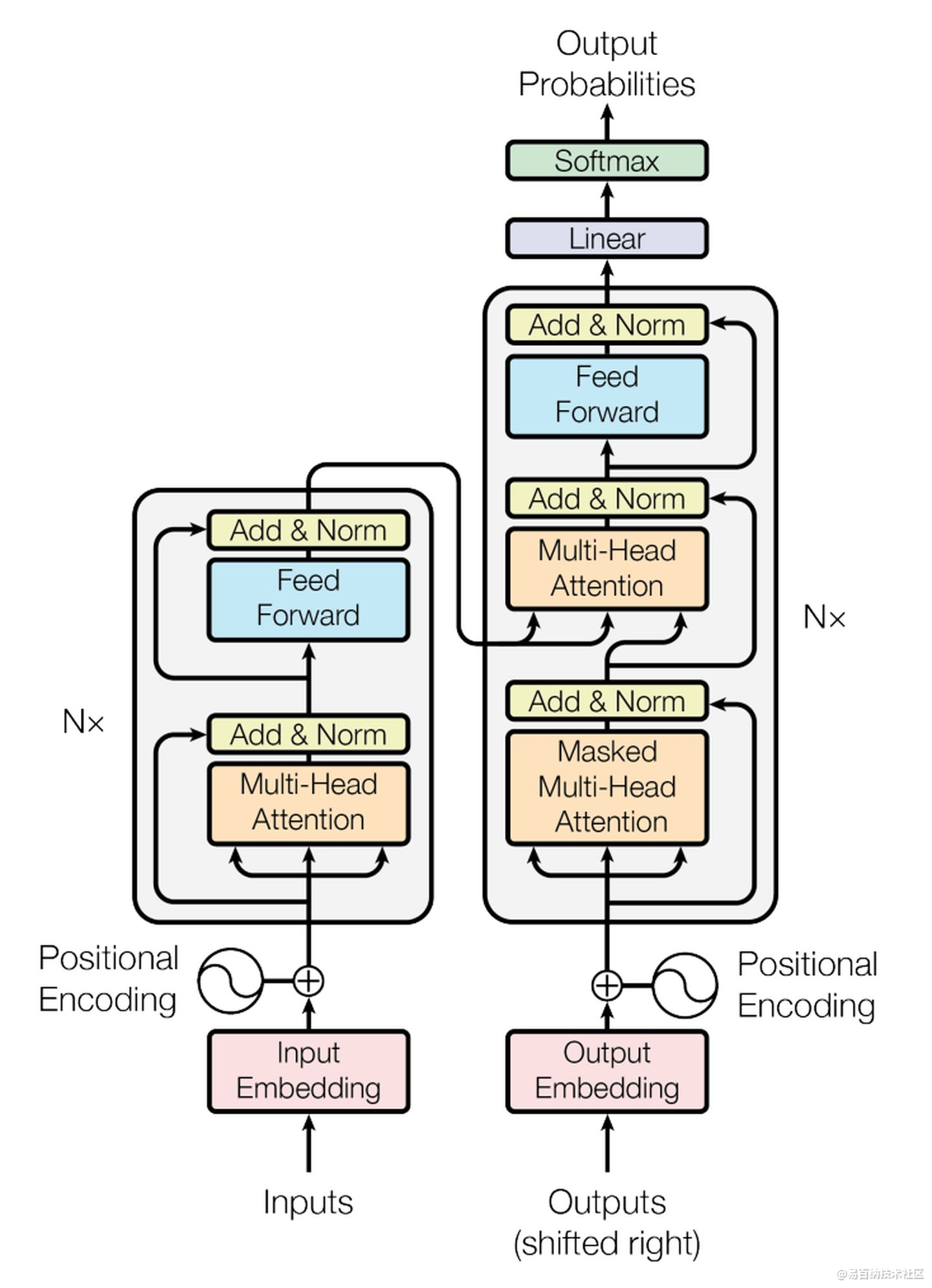
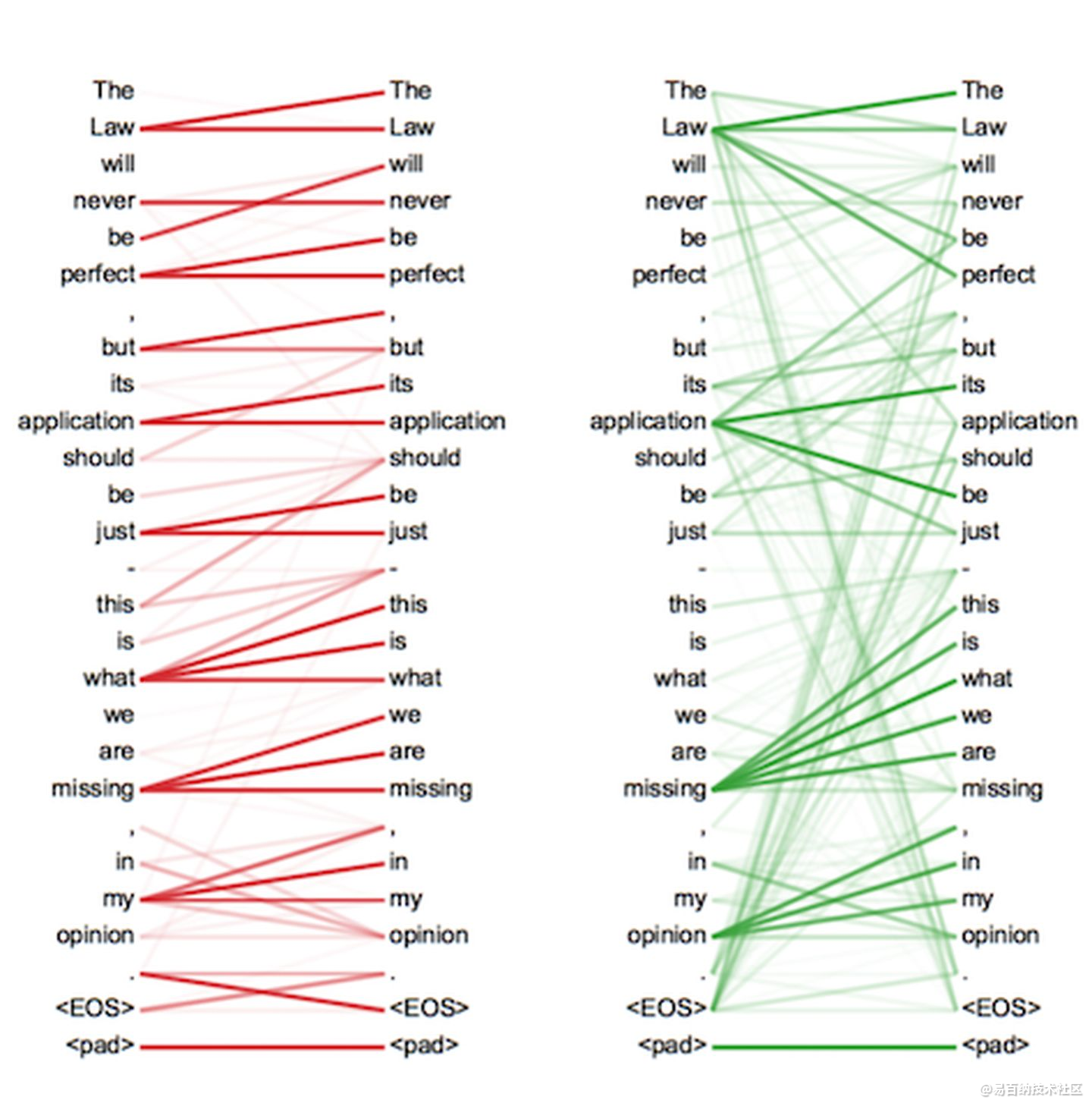
这里面Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征,如下图所示,两个head学习到的Attention侧重点可能略有不同,这样给了模型更大的容量。
Self-Attention详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
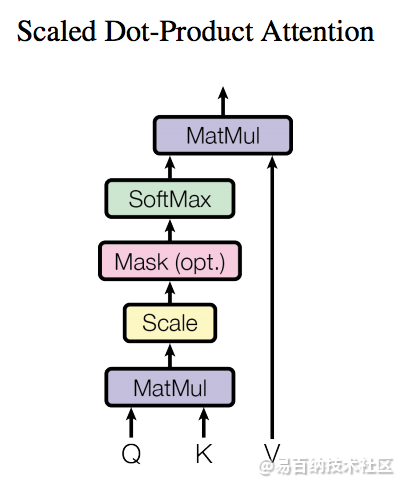
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入。

3 Feed Forward Neural Network
前馈神经网络(feedforward neural network,FNN),简称前馈网络,是人工神经网络的一种。前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层)。隐层可以是一层。也可以是多层 。
整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示 [2] 。
一个典型的多层前馈神经网络如图所示。
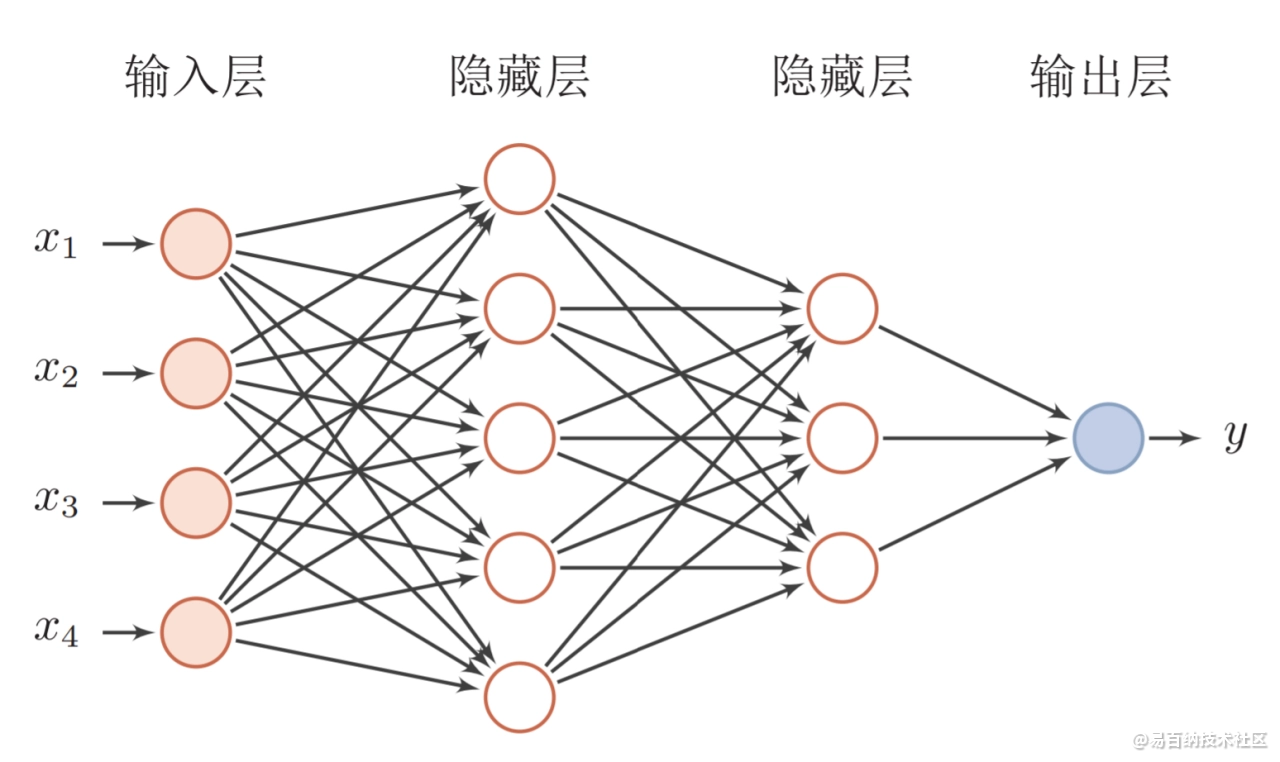
对于前馈神经网络结构设计,通常采用的方法有3类:直接定型法、修剪法和生长法。
直接定型法设计一个实际网络对修剪法设定初始网络有很好的指导意义;修剪法由于要求从一个足够大的初始网络开始,注定了修剪过程将是漫长而复杂的,更为不幸的是,BP训练只是最速下降优化过程,它不能保证对于超大初始网络一定能收敛到全局最小或是足够好的局部最小。因此,修剪法并不总是有效的,生长法似乎更符合人的认识事物、积累知识的过程,具有自组织的特点,则生长法可能更有前途,更有发展潜力。
多层前馈神经网络有一个输入层,中间有一个或多个隐含层,有一个输出层。多层感知器网络中的输入与输出变换关系为
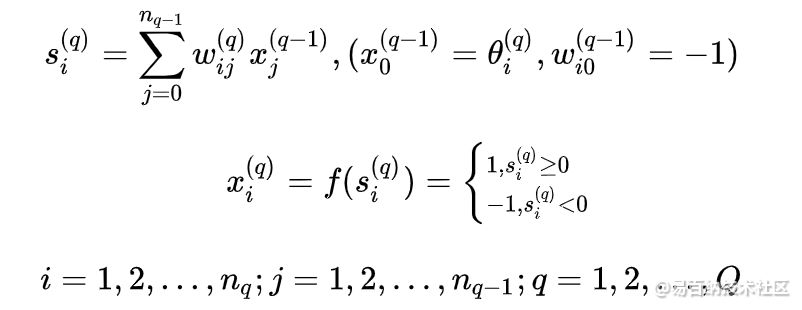
这时每一层相当于一个单层前馈神经网络,如对第层,它形成一个维的超平面。它对于该层的输入模式进行线性分类,但是由于多层的组合,最终可以实现对输入模式的较复杂的分类。
4 encoder-decoder attention
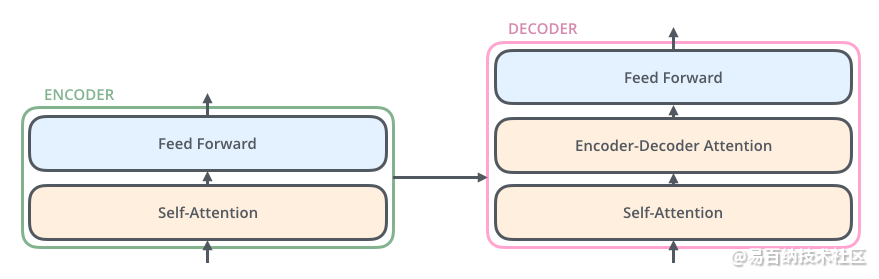
Transformer的解码器由self-attention,encoder-decoder attention以及FFNN组成
Encoder-Decoder模型
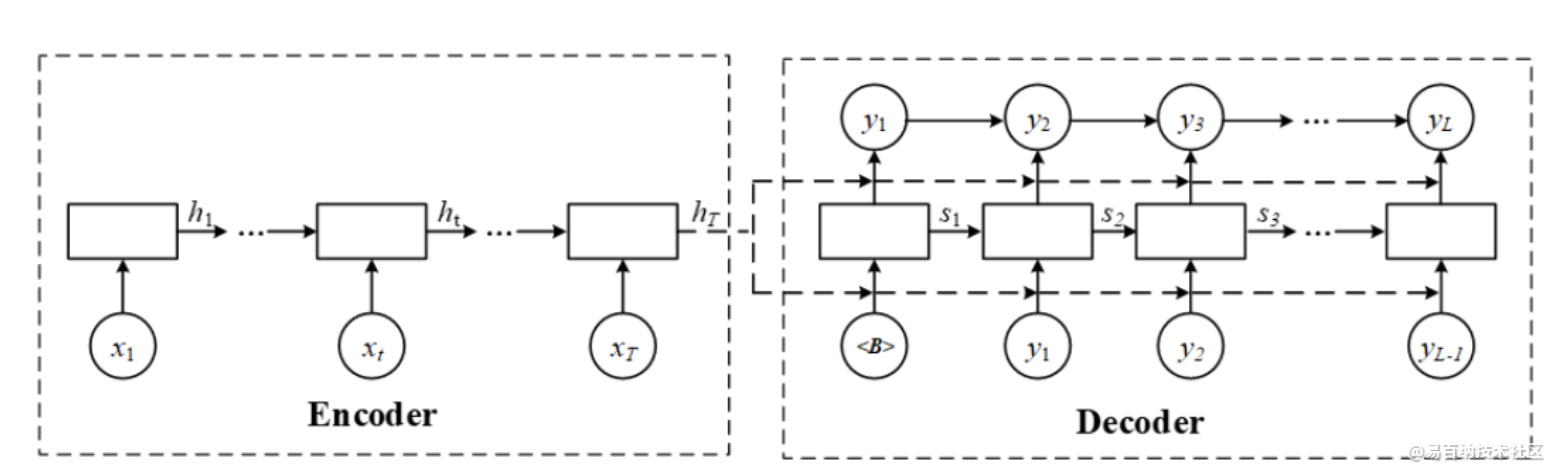
也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
具体实现的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合。比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等。
Neural Machine Translation by Jointly Learning to Align and Translate
这是 2015 年发表在 ICLR 上的论文,也是 NLP 中 Attention 机制的开山之作,Attention 机制是为了解决一般的 RNN Encoder-Decoder 对长句子表现不佳的问题而设计的。从论文题目中我们可以看到,作者希望通过 Attention 机制将输入句子 input 和输出句子 output 进行 “对齐”(SMT 中也有所谓的词对齐模型)。但是,由于不同语言的句法语法结构千差万别,想将源句子与翻译句子严格的对齐是很困难的,所以这里的对齐实际上是软对齐(soft-alignment),也就是不必将源句子显式分割,因而又被形象地称为注意力机制(Attention Mechanism)
近年来,基于神经网络的机器翻译模型经常被用来处理机器翻译任务。与传统基于统计的翻译方法相比,审计网络的机器翻译模型意在构建单个神经网络模型来提升整体翻译的准确率,主要的模型架构基本都是 Seq2Seq 家族的。在本论文中,作者认为该模型的瓶颈主要在于中间转换的向量是固定维度的。因此,作者提出了一种新的解码方式,其解码的源头不仅仅包括该向量,它们希望构建一种为当前预测词从输入序列中自动搜寻相关部分的机制(soft-search,也就是注意力机制)。作者运用这种新的机制来搭建升级版的神经翻译模型,取得了卓越的效果,并且也通过定量分析来证明了这种注意力机制的合理性
注意力机制解决的问题
传统的 Encoder-Decoder 结构对于长句子和生词过多的句子效果很不理想,因为随着序列的增长,句子越前面的词信息就会丢失的越厉害,虽然也有很多论文提出了一些 trick,比如将句子倒序输入,或者重复输入两遍,或者使用 LSTM 模型。但这些都治标不治本,对模型性能的提升并不明显,因为在解码时,当前预测词对应的输入词的上下文信息、位置信息等基本都已丢失
并且,性能的瓶颈在于 Encoder 强制将句子中所有信息都压缩在一个定长的向量中, 而当句子长度过大时,定长的向量就难以将所有的信息都编码进向量中,因此造成了性能下降。由此,作者提出,在翻译目标词的每一步,应该让 Decoder 自动抽取源句子中那些与目标词信息相关的部分,而忽略不相关的部分,这些部分的信息构成一个上下文向量 (context word) ,取代传统 Encoder 中的语义表示向量 。也就是说,Encoder 将句子编码成一个向量序列,而不是一个向量,然后再预测翻译单词的每一步选择这些向量的子集作为注意力向量输入到 Decoder 中。这是符合我们直觉的,因为人类在翻译句子时,不会每时每刻都考虑整个句子的含义,而是在翻译特定片段时,重点注意这个片段附近的上下文,而不会注意离我们正在翻译的片段较远的那些片段。
Seq2seq
简单的说,就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5519次2021-06-22 16:53:40
-
浏览量:6823次2021-05-24 15:13:24
-
浏览量:15029次2021-05-31 17:01:39
-
浏览量:10167次2021-06-09 12:09:57
-
浏览量:5161次2021-04-27 16:30:07
-
浏览量:5643次2021-08-09 16:11:19
-
浏览量:9936次2021-04-20 15:42:26
-
浏览量:5766次2021-04-20 15:43:03
-
浏览量:5866次2021-06-16 11:22:18
-
浏览量:7054次2021-06-24 10:38:30
-
浏览量:4892次2021-04-21 17:05:28
-
浏览量:4830次2021-04-21 17:05:56
-
浏览量:8060次2021-06-03 11:03:40
-
浏览量:11135次2021-06-25 15:00:55
-
浏览量:7312次2021-06-07 09:27:26
-
浏览量:6444次2021-06-27 18:19:55
-
浏览量:6153次2021-06-27 18:20:34
-
浏览量:4372次2021-05-26 15:42:50
-
浏览量:12019次2021-05-04 20:20:07

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
