

【深度学习】计算机视觉相关技术探索(一)
【深度学习】计算机视觉相关技术探索(一)
文章目录
1 计算机视觉概述
2 使用机器学习解决图像分类问题
3 Keras和神经网络简介
4 卷积神经网络(CNN),迁移学习
5 对象检测问题
6 yolo回归型的物体检测
7 图像分割和注意力模型
8 NLP和图像字幕的基础
9 低层次视觉-生成对抗网络(GAN)
10 视频分析
11 视觉SLAM(二维到三维)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1 计算机视觉概述
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取‘信息’的人工智能系统。这里所指的信息指Shannon定义的,可以用来帮助做一个“决定”的信息。因为感知可以看作是从感官信号中提取信息,所以计算机视觉也可以看作是研究如何使人工系统从图像或多维数据中“感知”的科学。
2 使用机器学习解决图像分类问题
SVM分类器
本节将使用MNIST训练数据集训练(多类)支持向量机(SVM)分类器,然后用它预测来自MNIST测试数据集的图像的标签。
支持向量机是一种非常复杂的二值分类器,它使用二次规划来最大化分离超平面之间的边界。利用1︰全部或1︰1技术,将二值SVM分类器扩展到处理多类分类问题。使用scikit-learn的实现SVC(),它具有多项式核(二次),利用训练数据集来拟合(训练)软边缘(核化)SVM分类器,然后用score()函数预测测试图像的标签。
如下代码展示了如何使用MNIST数据集训练、预测和评估SVM分类器。可以看到,使用该分类器在测试数据集上所得到的准确率提高到了98%。
from sklearn.svm import SVC
clf = SVC(C=1, kernel='poly', degree=2)
clf.fit(train_data,train_labels)
print(clf.score(test_data,test_labels))
# 0.9806
test_predictions = clf.predict(test_data)
cm = metrics.confusion_matrix(test_labels,test_predictions)
df_cm = pd.DataFrame(cm, range(10), range(10))
sn.set(font_scale=1.2)
sn.heatmap(df_cm, annot=True,annot_kws={"size": 16}, fmt="g")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

混淆矩阵
接下来,找到SVM分类器预测错误标签的测试图像(与真实标签不同)。
如下代码展示了如何找到这样一幅图像,并将其与预测的和真实的标签一起显示:
wrong_indices = test_predictions != test_labels
wrong_digits, wrong_preds, correct_labs = test_data[wrong_indices],
test_predictions[wrong_indices], test_labels[wrong_indices]
print(len(wrong_pred))
# 194
pylab.title('predicted: ' + str(wrong_preds[1]) +', actual: ' +str(correct_labs[1]))
display_char(wrong_digits[1])- 1
- 2
- 3
- 4
- 5
- 6
- 7

3 Keras和神经网络简介
Keras文档
https://keras.io/
使用Keras构建神经网络
https://www.analyticsvidhya.com/blog/2016/10/tutorial-optimizing-neural-networks-using-keras-with-image-recognition-case-study/
神经网络简介:
从零开始的神经网络
https://www.analyticsvidhya.com/blog/2017/05/neural-network-from-scratch-in-python-and-r/
斯坦福大学神经网络简介
https://youtu.be/d14TUNcbn1k
3Blue1Brown的神经网络:
https://youtu.be/aircAruvnKk
项目:识别服装
https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-apparels/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4 卷积神经网络(CNN),迁移学习
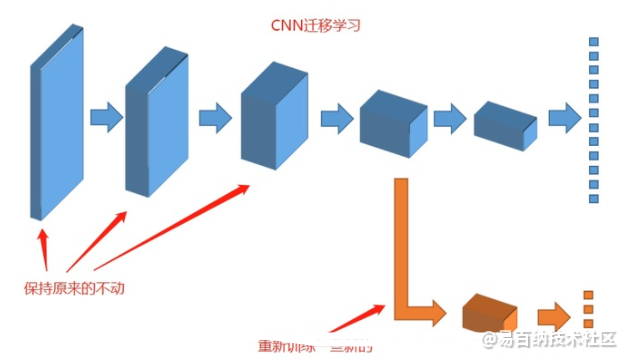
迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。
深度学习中在计算机视觉任务和自然语言处理任务中将预训练的模型作为新模型的起点是一种常用的方法,通常这些预训练的模型在开发神经网络的时候已经消耗了巨大的时间资源和计算资源,迁移学习可以将已习得的强大技能迁移到相关的的问题上。
5 对象检测问题
对象检测是一种广泛使用的计算机视觉技术(也许是使用最广泛的技术)。这是吸引我使用计算机视觉的原因!这个月就是要熟悉不同的对象检测算法。另外,我强烈建议你撰写到目前为止所学概念的文章。

目标检测技术的分步介绍
https://www.analyticsvidhya.com/blog/2018/10/a-step-by-step-introduction-to-the-basic-object-detection-algorithms-part-1
实现faster RCNN用于目标检测
https://www.analyticsvidhya.com/blog/2018/11/implementation-faster-r-cnn-python-object-detection
使用YOLO进行物体检测
https://www.analyticsvidhya.com/blog/2018/12/practical-guide-object-detection-yolo-framewor-python
斯坦福大学的物体检测:
https://youtu.be/nDPWywWRIRo
YOLO论文
https://arxiv.org/pdf/1506.02640.pdf
YOLO预训练模型
https://pjreddie.com/darknet/yolo/
项目:
数脸挑战
https://datahack.analyticsvidhya.com/contest/vista-codefest-computer-vision-1
COCO物体检测挑战
http://cocodataset.org/#download
6 yolo回归型的物体检测
发现一篇讲的非常棒的文章,就直接搬到了我的博客上:
YOLO全称You Only Look Once: Unified, Real-Time Object Detection,是在CVPR2016提出的一种目标检测算法,核心思想是将目标检测转化为回归问题求解,并基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。YOLO与Faster RCNN有以下区别:- 1
Faster RCNN将目标检测分解为分类为题和回归问题分别求解:首先采用独立的RPN网络专门求取region proposal,即计算图1中的P(objetness);然后对利用bounding box regression对提取的region proposal进行位置修正,即计算图1中的Box offsets(回归问题);最后采用softmax进行分类(分类问题)。
YOLO将物体检测作为一个回归问题进行求解:输入图像经过一次网络,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
YOLO核心思想
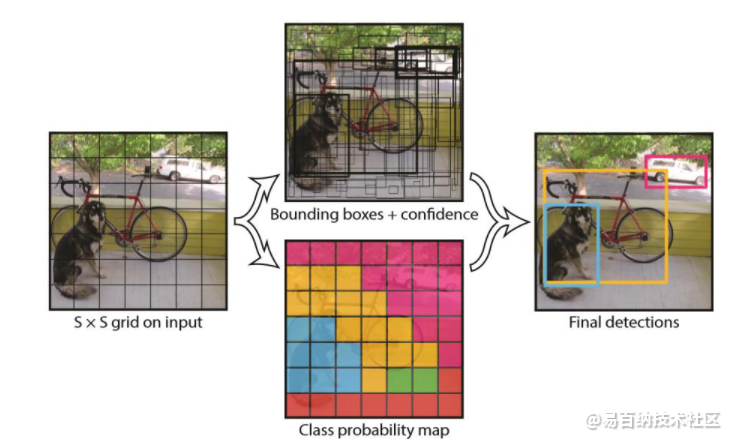
YOLO的工作过程分为以下几个过程:
(1) 将原图划分为SxS的网格。如果一个目标的中心落入某个格子,这个格子就负责检测该目标。
(2) 每个网格要预测B个bounding boxes,以及C个类别概率Pr(classi|object)。这里解释一下,C是网络分类总数,由训练时决定。在作者给出的demo中C=20,包含以下类别:
Yolov3是一个目标检测算法项目,而目标检测的本质,就是识别与回归,而处理图像用的最多的就是卷积神经网络CNN,所以,Yolov3本质上,就是一个实现了回归功能的深度卷积神经网络。
Yolo是一种实时检测方法,多年来备受欢迎。这意味着我们不仅可以对一个对象进行分类,还可以定位它并提取包围该对象的边框。
运行yolov3有多种方法。我们今天将使用的方法是最简单的方法之一,因为除了opencv和numpy之外,它不需要外部安装。
当然,我们需要下载模型文件,yolo中的模型文件将architecture(结构)和权重参数(weight)进行了分离,我们可以在YOLO: Real-Time Object Detection中下载对应的模型文件,在这里,我们推荐使用YOLOv3-320的配置(下载可能需要一点时间),因为这个模型被认为是速度和精度之间的平衡。
我们用摄像头对准需要检测的物体,就可以得到以下检测结果:
import cv2
import numpy as np
cap = cv2.VideoCapture(1)
whT = 320
confThreshold =0.5
nmsThreshold= 0.2
classsesFile = "coco.names"
classNames = []
with open(classsesFile,'rt') as f:
classNames = f.read().rstrip('\n').split('\n')
print(classNames)
modelConfiguration = "yolov3-320.cfg"
modelWeights = "yolov3.weights"
net = cv2.dnn.readNetFromDarknet(modelConfiguration,modelWeights)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
# bbox = [] # bounding box corner points
# classIds = [] # class id with the highest confidence
# confs = [] # confidence value of the highest class
def findObjects(outputs, img):
hT, wT, cT = img.shape
bbox = []
classIds = []
confs = []
for output in outputs:
for det in output:
scores = det[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
w, h = int(det[2] * wT), int(det[3] * hT)
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2)
bbox.append([x, y, w, h])
classIds.append(classId)
confs.append(float(confidence))
indices = cv2.dnn.NMSBoxes(bbox, confs, confThreshold, nmsThreshold)
for i in indices:
i = i[0]
box = bbox[i]
x, y, w, h = box[0], box[1], box[2], box[3]
# print(x,y,w,h)
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 255), 2)
cv2.putText(img, f'{classNames[classIds[i]].upper()} {int(confs[i] * 100)}%',
(x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
while True:
success, img = cap.read()
blob = cv2.dnn.blobFromImage(img,1/255,(whT,whT),[0,0,0],1,crop=False)
net.setInput(blob)
layersNames = net.getLayerNames()
outputNames = [(layersNames[i[0]-1]) for i in net.getUnconnectedOutLayers()]
outputs = net.forward(outputNames)
for output in outputs:
print(output.shape)
findObjects(outputs, img)
cv2.imshow('Image',img)
cv2.waitKey(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61

7 图像分割和注意力模型
为什么需要视觉注意力
计算机视觉(computer vision)中的注意力机制(attention)的基本思想就是想让系统学会注意力——能够忽略无关信息而关注重点信息。为什么要忽略无关信息呢?
注意力分类与基本概念
神经网络中的「注意力」是什么?怎么用?这里有一篇详解
该文分为: 硬注意力、软注意力、此外,还有高斯注意力、空间变换
就注意力的可微性来分:
Hard-attention,就是0/1问题,哪些区域是被 attentioned,哪些区域不关注.硬注意力在图像中的应用已经被人们熟知多年:图像裁剪(image cropping)
硬注意力(强注意力)与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。(参考文章:Mnih, Volodymyr, Nicolas Heess, and AlexGraves. “Recurrent models of visual attention.” Advances inneural information processing systems. 2014.)
SENET (通道域)—2017CPVR
SE
将输入特征进行 Global AVE pooling,得到 11 Channel
然后bottleneck特征交互一下,先压缩 channel数,再重构回channel数
最后接个 sigmoid,生成channel 间0~1的 attention weights,最后 scale 乘回原输入特征
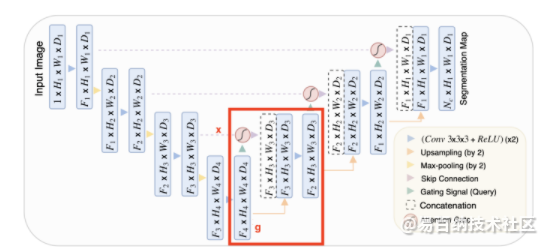
在UNet中,可将收缩路径视为编码器,而将扩展路径视为解码器。UNet的有趣之处在于,跳跃连接允许在解码器期间直接使用由编码器提取的特征。这样,在“重建”图像的掩模时,网络就学会了使用这些特征,因为收缩路径的特征与扩展路径的特征是连接在一起的。
在此连接之前应用一个注意力块,可以让网络对跳转连接相关的特征施加更多的权重。它允许直接连接专注于输入的特定部分,而不是输入每个特征。
将注意力分布乘上跳转连接特征图,只保留重要的部分。这种注意力分布是从所谓的query(输入)和value(跳跃连接)中提取出来的。注意力操作允许有选择地选择包含在值中的信息。此选择基于query。
总结:输入和跳跃连接用于决定要关注跳跃连接的哪些部分。
8 NLP和图像字幕的基础
自然语言处理(NLP)的基础知识:
斯坦福-词嵌入:
https://youtu.be/ERibwqs9p38
递归神经网络(RNN)简介:
https://youtu.be/UNmqTiOnRfg
RNN教程
http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
了解图像字幕
自动图像字幕
https://cs.stanford.edu/people/karpathy/sfmltalk.pdf
使用深度学习的图像字幕
https://www.analyticsvidhya.com/blog/2018/04/solving-an-image-captioning-task-using-deep-learning
项目:COCO字幕挑战赛
http://cocodataset.org/#download
m-RNN
Mao这篇2015-paper,根据输入语句和图片,为图片生成字幕;以DeepRNN 处理语句,用CNN处理图片。基本思路:直接将图像表示和词向量以及隐向量作为多模判断的输入。
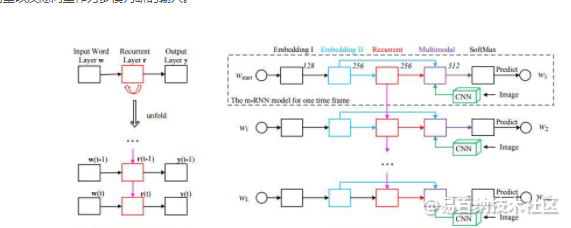
左侧是简单RNN结构,右侧是本文所提的m-RNN(多模式),输入是图片极其对应的语句描述。模型根据之前词和图像来评估下个词的概率分布,每一时间帧上,所有的权重都是共享的。
9 低层次视觉-生成对抗网络(GAN)
自从Ian Goodfellow于2014年正式推出GAN以来,GANs就火爆了起来。目前,GANs的实际应用很多,包括修复、生成图像等。

10 视频分析
视频分析是计算机视觉中一个蓬勃发展的应用。到2020年(及以后),对这项技能的需求只增不减,因此学习如何使用视频数据集的知识是必要的。
计算视频中演员的放映时间
https://www.analyticsvidhya.com/blog/2018/09/deep-learning-video-classification-python
建立视频分类模型
https://www.analyticsvidhya.com/blog/2019/09/step-by-step-deep-learning-tutorial-video-classification-python
通过视频进行人脸检测
https://www.analyticsvidhya.com/blog/2018/12/introduction-face-detection-video-deep-learning-python- 1
- 2
- 3
- 4
- 5
- 6
11 视觉SLAM(二维到三维)
什么是视觉SLAM
SLAM是“Simultaneous Localization And Mapping”的缩写,可译为同步定位与建图。概率 SLAM 问题 (the probabilistic SLAM problem) 起源于 1986 年的IEEE Robotics and Automation Conference 大会上,研究人员希望能将估计理论方法 (estimation-theoretic methods) 应用在构图和定位问题中。 SLAM最早被被应用在机器人领域,其目标是在没有任何先验知识的情况下,根据传感器数据实时构建周围环境地图,同时根据这个地图推测自身的定位。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3508次2020-02-27 10:34:09
-
浏览量:6158次2021-06-27 18:20:34
-
浏览量:780次2024-01-12 11:39:24
-
浏览量:1041次2023-01-13 11:31:19
-
浏览量:1237次2024-03-14 18:20:47
-
浏览量:6109次2021-07-28 14:21:28
-
2020-12-14 18:16:24
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:5357次2020-12-29 19:37:20
-
浏览量:1812次2020-05-06 09:55:45
-
浏览量:5753次2020-12-21 16:50:21
-
浏览量:7398次2020-12-21 20:12:30
-
浏览量:936次2023-11-30 09:18:58
-
浏览量:2751次2019-06-17 15:02:48
-
浏览量:6918次2021-01-05 18:32:12
-
浏览量:4534次2021-01-08 01:04:31
-
2021-01-12 21:31:51
-
浏览量:5074次2021-01-11 15:33:50
-
浏览量:50077次2021-07-28 14:21:08

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
