

【深度学习】Swin-Unet图像分割网络解析(文末提供剪枝仓库)
【深度学习】Swin-Unet图像分割网络解析(文末提供剪枝仓库)
文章目录
1 概述
2 Swin-Unet架构
3 bottleneck理解
4 具体结构
4.1 Swin Transformer block
5 通过剪枝和量化压缩Transformer
- 1
- 2
- 3
- 4
- 5
- 6
- 7

1 概述

Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
论文:https://arxiv.org/abs/2105.05537
代码:https://github.com/HuCaoFighting/Swin-Unet
首个基于纯Transformer的U-Net形的医学图像分割网络,其中利用Swin Transformer构建encoder、bottleneck和decoder,表现SOTA!性能优于TransUnet、Att-UNet等,代码即将开源!
在过去的几年中,卷积神经网络(CNN)在医学图像分析中取得了里程碑式的进展。尤其是,基于U形结构和skip-connections的深度神经网络已广泛应用于各种医学图像任务中。但是,尽管CNN取得了出色的性能,但是由于卷积操作的局限性,它无法很好地学习全局和远程语义信息交互。
在本文中,作者提出了Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer模型。标记化的图像块通过跳跃连接被送到基于Transformer的U形Encoder-Decoder架构中,以进行局部和全局语义特征学习。
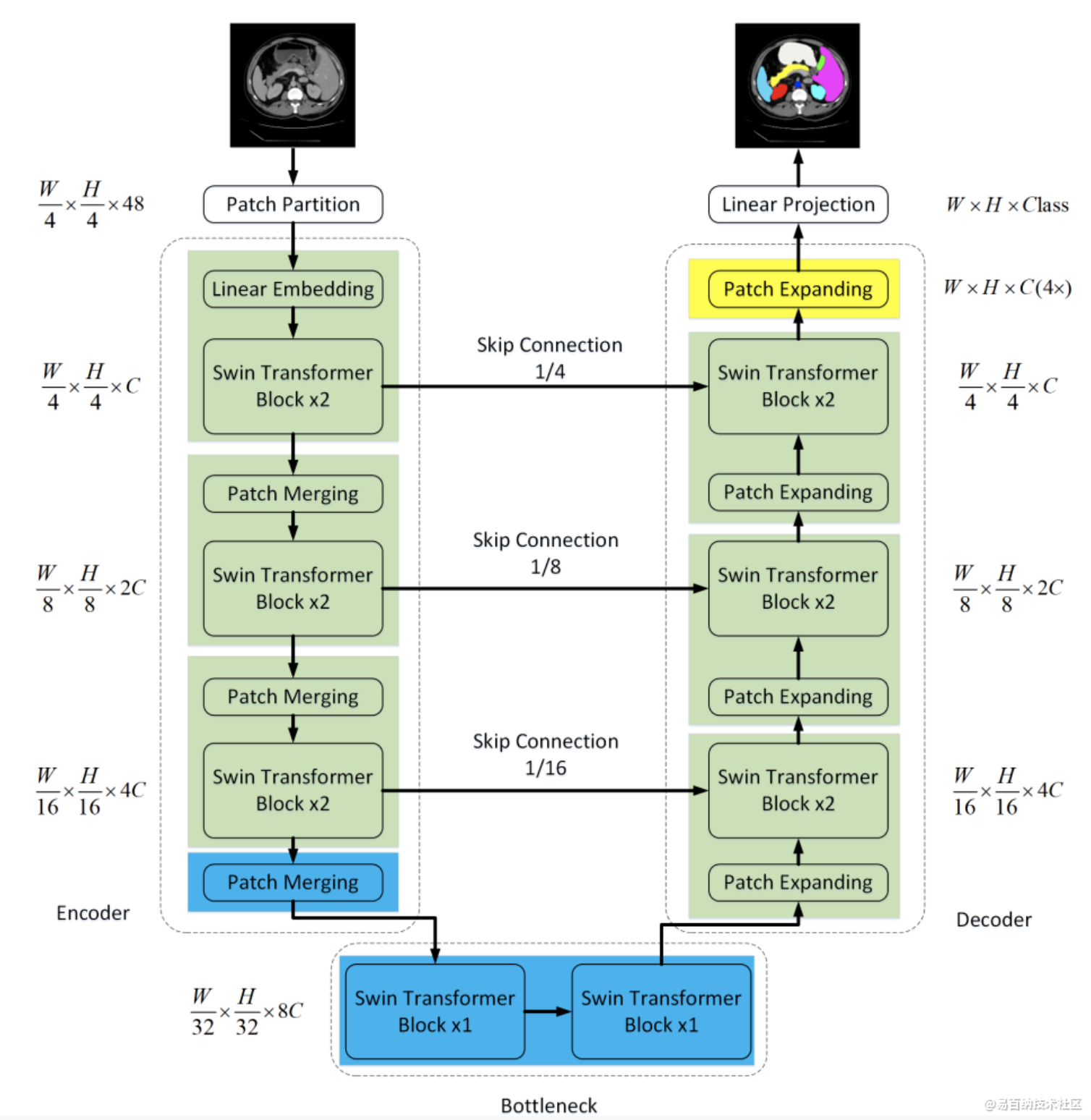
2 Swin-Unet架构
3 bottleneck理解
bottleneck简单翻译就是瓶颈层,一般在深度较高的网络(如resnet101)中使用,一般结构如下图所示。
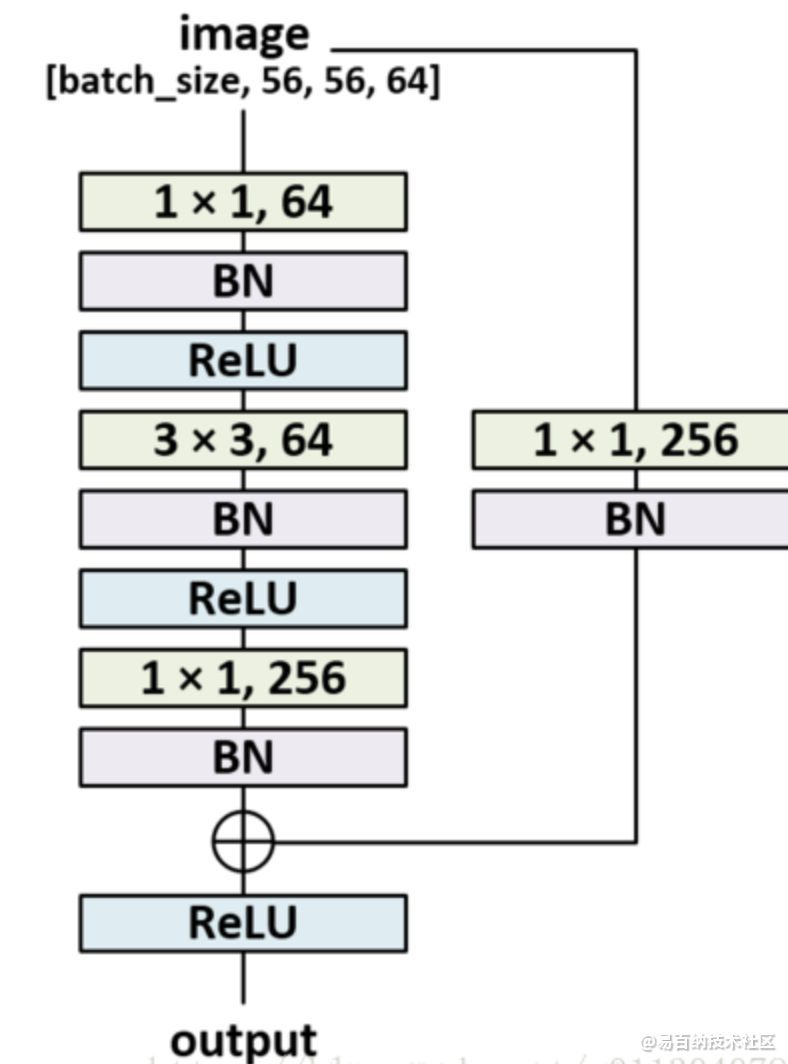
其中两个1X1fliter分别用于降低和升高特征维度,主要目的是为了减少参数的数量,从而减少计算量,且在降维之后可以更加有效、直观地进行数据的训练和特征提取,对比如下图所示。
Bottleneck layer又称之为瓶颈层,使用的是1*1的卷积神经网络。之所以称之为瓶颈层,是因为长得比较像一个瓶颈。
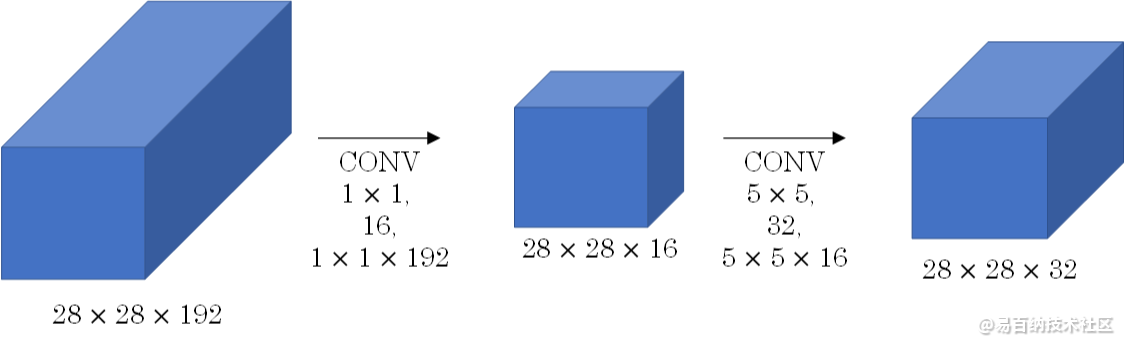
如上图所示,经过 [公式] 的网络,中间那个看起来比较细。像一个瓶颈一样。使用 [公式] 网络的一大好处就是可以大幅减少计算量。深度可分离卷积中,也有这样的设计考虑。
ResNet中的Bottleneck layer
Bottleneck layer这种结构比较常见的出现地方就是ResNet block了。
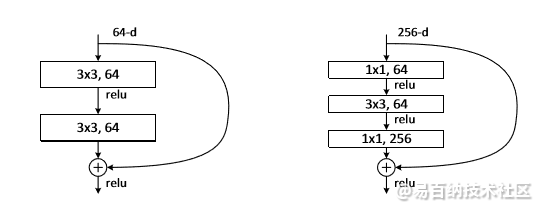
如图所示分别是有bottleneck和没有bottleneck的ResNet模块。
4 具体结构
Swin-Unet架构:由Encoder, Bottleneck, Decoder和Skip Connections组成。
Encoder, Bottleneck以及Decoder都是基于Swin-Transformer block构造的实现。
4.1 Swin Transformer block
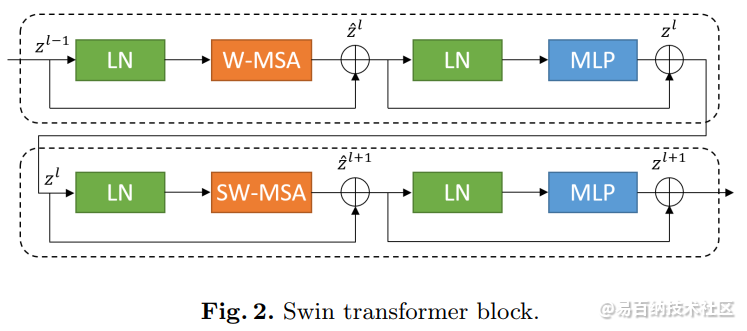
与传统的multi-head self attention(MSA)模块不同,Swin Transformer是基于平移窗口构造的。在图2中,给出了2个连续的Swin Transformer Block。每个Swin Transformer由LayerNorm(LN)层、multi-head self attention、residual connection和2个具有GELU的MLP组成。在2个连续的Transformer模块中分别采用了windowbased multi-head self attention(W-MSA)模块和 shifted window-based multi-head self attention (SW-MSA)模块。基于这种窗口划分机制的连续Swin Transformer Block可表示为:
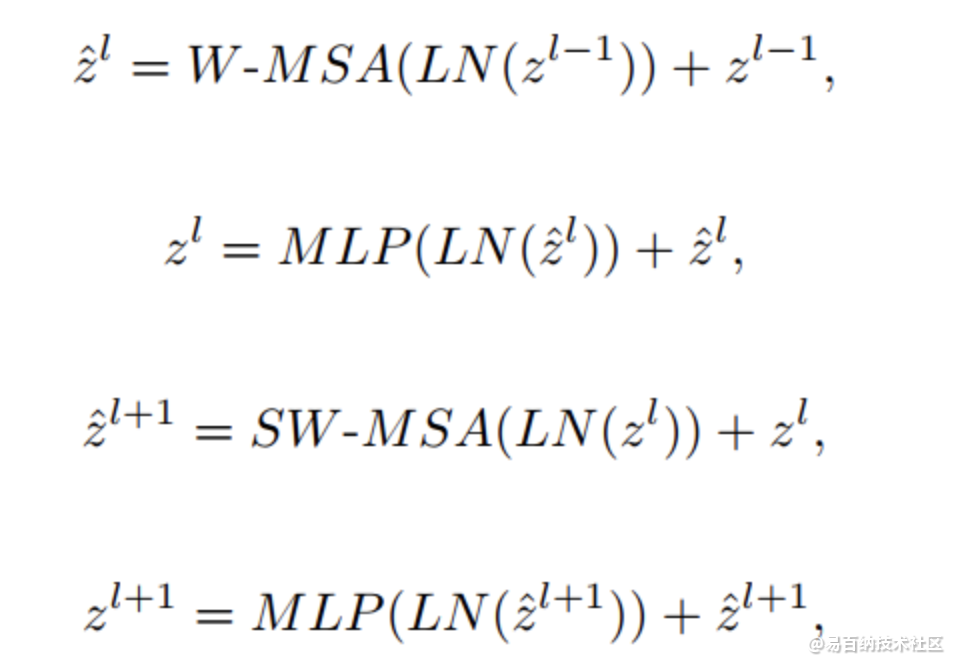


Up-Sampling会带来什么影响?
针对Encoder中的patch merge层,作者在Decoder中专门设计了Patch expanding layer,用于上采样和特征维数增加。为了探索所提出Patch expanding layer的有效性,作者在Synapse数据集上进行了双线性插值、转置卷积和Patch expanding layer的Swin-Unet实验。实验结果表明,本文提出的Swin-Unet结合Patch expanding layer可以获得更好的分割精度。
Skip connection
与U-Net类似,Skip connection用于融合来自Encoder的多尺度特征与上采样特征。这里将浅层特征和深层特征连接在一起,以减少降采样带来的空间信息损失。然后是一个线性层,连接特征尺寸保持与上采样特征的尺寸相同。
5 通过剪枝和量化压缩Transformer
剪枝
文中使用的是iterative magnitude pruning方法,这个方法特别简单,将权值小于某一个阈值的参数全部用零替换

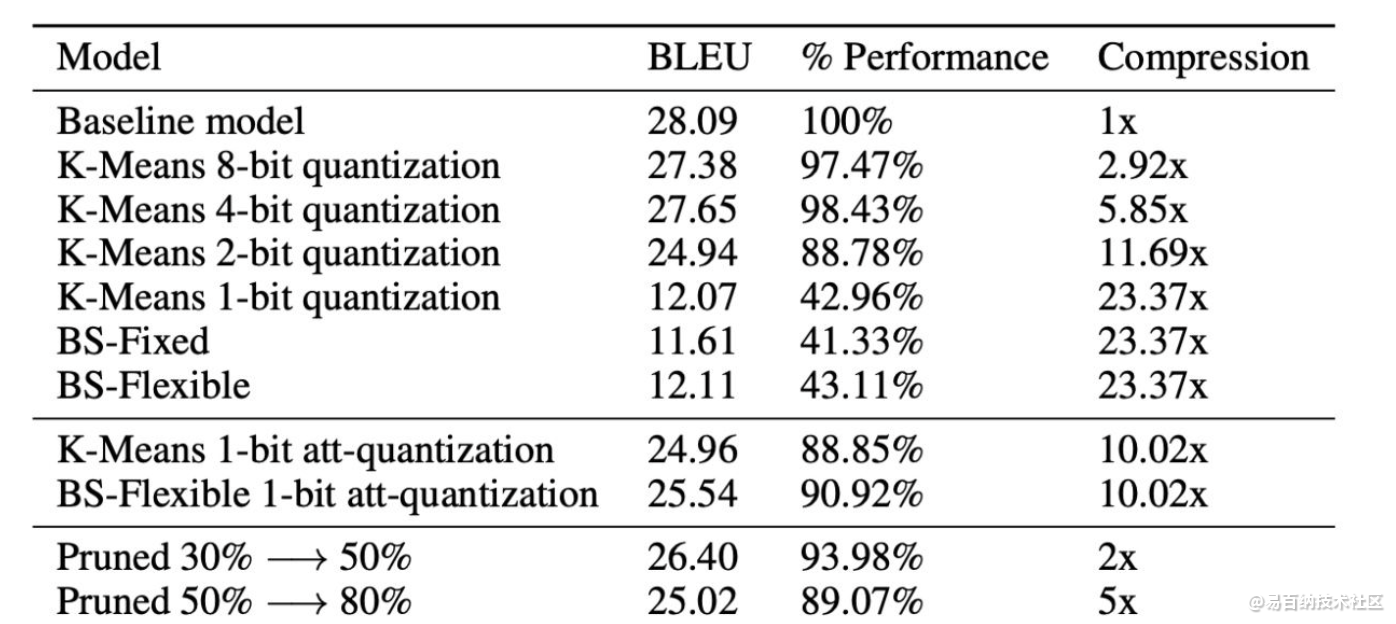
结果
量化方面4bit的量化效果依然足够好,压缩比能够达到5倍多,剪枝方面效果相对有限,文中解释说有一些超参需要tuning(比如阈值),二值化的方法如果使用到整个transformer则效果比较差,但是如果能够只在self-attention上进行使用,则效果就会非常好(对应到BS-Flexible 1-bit att-quantization方法)
上面两个仓库可以看下源码!
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:7565次2021-07-19 17:08:40
-
浏览量:13055次2021-05-11 15:08:10
-
浏览量:11167次2021-06-25 15:00:55
-
浏览量:6683次2021-05-31 17:02:05
-
浏览量:14433次2021-05-04 20:16:03
-
浏览量:4586次2021-04-19 14:55:34
-
浏览量:7327次2021-06-07 09:27:26
-
浏览量:5608次2021-05-28 16:59:25
-
浏览量:8593次2021-05-28 16:59:43
-
浏览量:13502次2021-07-05 09:47:30
-
浏览量:6644次2021-06-07 09:26:53
-
浏览量:8894次2021-07-19 17:09:44
-
浏览量:7446次2021-07-19 17:10:27
-
浏览量:7093次2021-06-24 10:38:30
-
浏览量:5471次2021-05-04 20:20:52
-
浏览量:6845次2021-05-04 20:17:10
-
浏览量:7012次2021-06-18 17:21:06
-
浏览量:157次2023-08-30 15:28:02
-
浏览量:9302次2021-06-21 11:49:58

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
