

【深度学习】协同优化器和结构化知识蒸馏
【深度学习】协同优化器和结构化知识蒸馏
文章目录
1 概述
2 什么是RAdam(Rectified Adam)
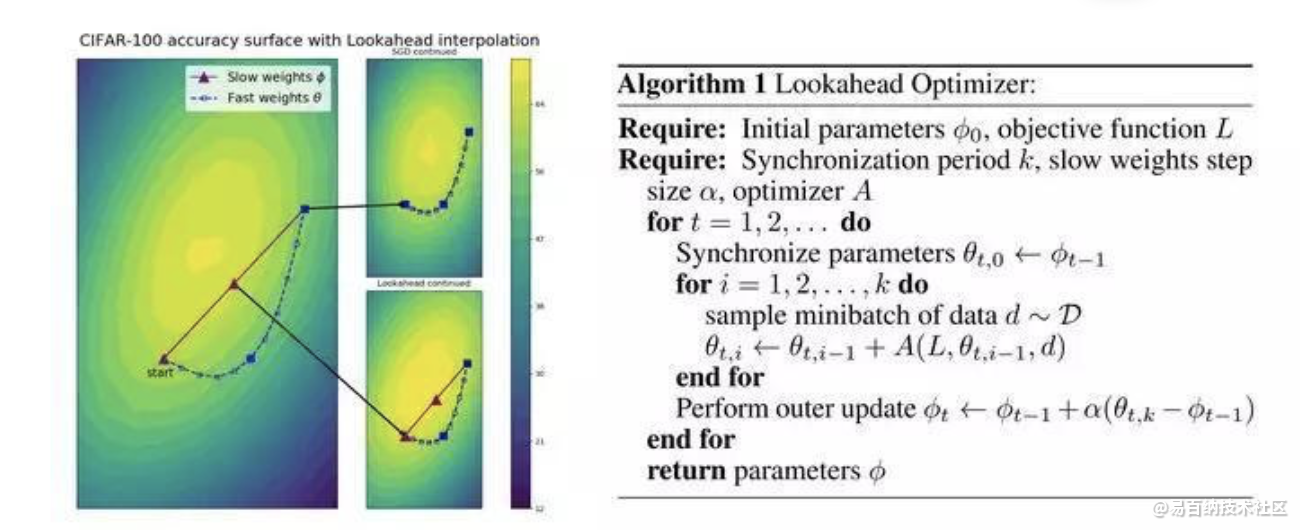
3 Lookahead - 探索损失面的伙伴系统=更快,更稳定的探索和收敛。
4 Ranger - 一个使用RAdam和LookAhead的优化器的集成代码库。
5 结构化知识蒸馏1 概述

一篇由知名深度学习研究员Geoffrey Hinton撰写的新论文介绍了LookAhead优化器(“LookAhead优化器:k步前进,后退一步”,2019年7月)。Lookahead的灵感来自对神经网络损耗表面理解的最新进展,并提出了一种稳定深度学习训练和收敛速度的全新方法。在RAdam(Rectified Adam)实现的深度学习方差管理突破的基础上,我发现将RAdam和LookAhead结合在一起可以产生一个动态的梦之队,甚至比单独的RAdam更优化。
将两者合并为一个Ranger优化器代码库,以便于使用和集成到FastAI中,Ranger源代码可供您立即使用
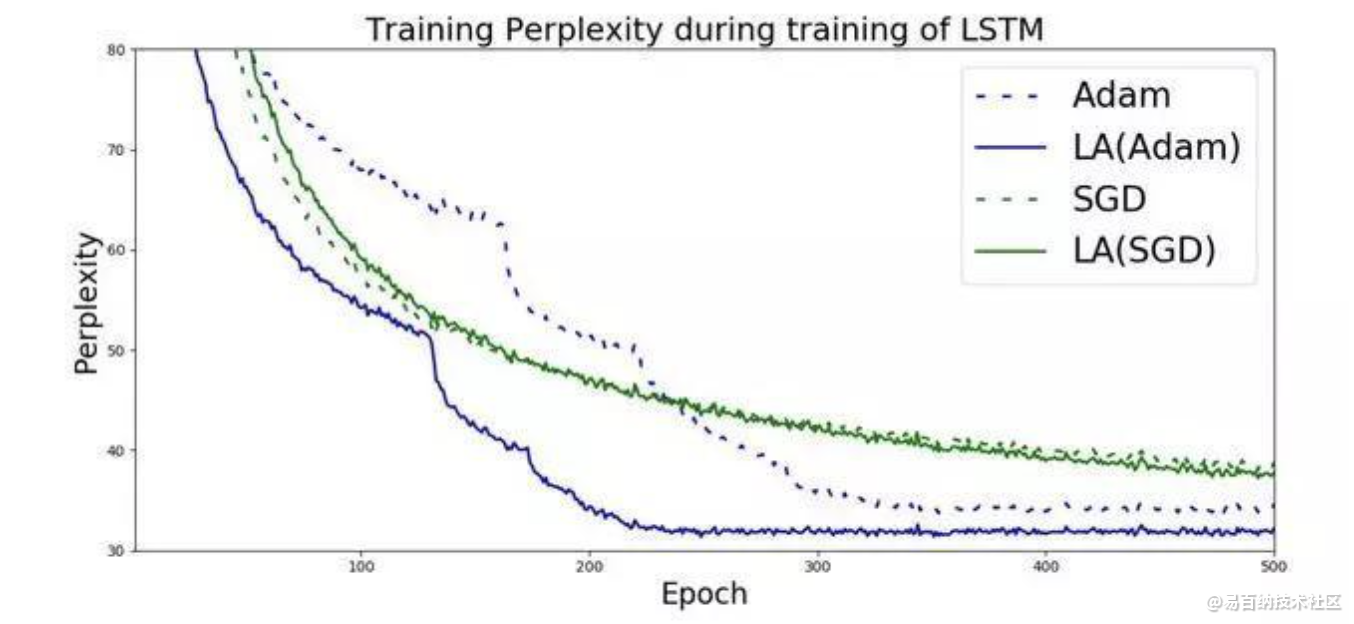
为什么RAdam和LookAhead是互补的:
RAdam可以说是优化者在培训开始时建立的最佳基础。RAdam利用动态整流器根据方差调整Adam的自适应动量,并有效地提供自动预热,根据当前数据集定制,以确保扎实的训练开始。
LookAhead受到深度神经网络损失表面理解的最新进展的启发,并在整个训练期间提供了稳健和稳定探索的突破。
引用LookAhead团队 - LookAhead“减少了对广泛超参数调整的需求”,同时实现“以最小的计算开销实现不同深度学习任务的更快收敛”。
因此,两者都在深度学习优化的不同方面提供了突破,并且这种组合具有高度协同性,可能为您的深度学习结果提供最佳的两种改进。因此,对更加稳定和强大的优化方法的追求仍在继续,通过结合两项最新突破(RAdam + LookAhead),Ranger的整合有望为深度学习提供又一步。
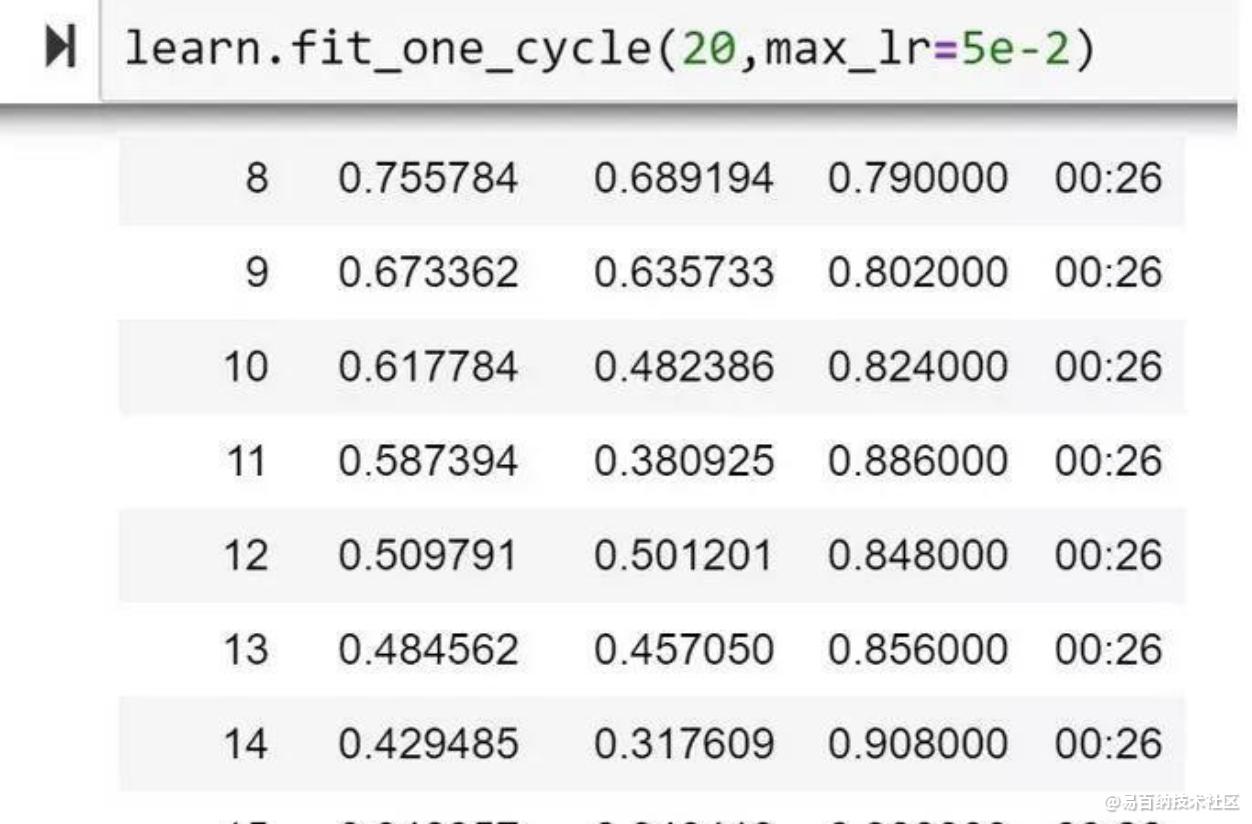
因此,本文基于之前的RAdam介绍来解释LookAhead是什么,以及如何通过将RAdam和LookAhead组合到单个优化器Ranger中,获得了新的高精度。 从字面上看,我测试的第一个20个epoch,我个人看到了一个新的高%精度,比目前的FastAI排行榜标记高1%:
深入研究驱动Ranger的两个组件--RAdam和LookAhead:
2 什么是RAdam(Rectified Adam)
我将向您介绍我之前在RAdam上详细介绍的文章。然而,简短的总结是开发RAdam的研究人员调查了自适应动量优化器(Adam,RMSProp等)的原因。所有这些都需要热身,否则他们往往会在训练开始时接近糟糕/可疑的局部最佳状态。
3 Lookahead - 探索损失面的伙伴系统=更快,更稳定的探索和收敛。
正如LookAhead的研究人员所说,目前,大多数成功的优化器都是建立在SGD基础之上的
1 - 适应性动量(Adam,AdaGrad)或
2 - 一种加速形式(Nesterov动量或Polyak Heavy Ball)
改善探索和培训过程,最终收敛。
结果是训练期间的方差减小,对次优超参数的敏感性降低,并且减少了对广泛的超参数调整的需求。这样做可以在各种深度学习任务上实现更快的收敛。换句话说,这是一个令人印象深刻的突破。
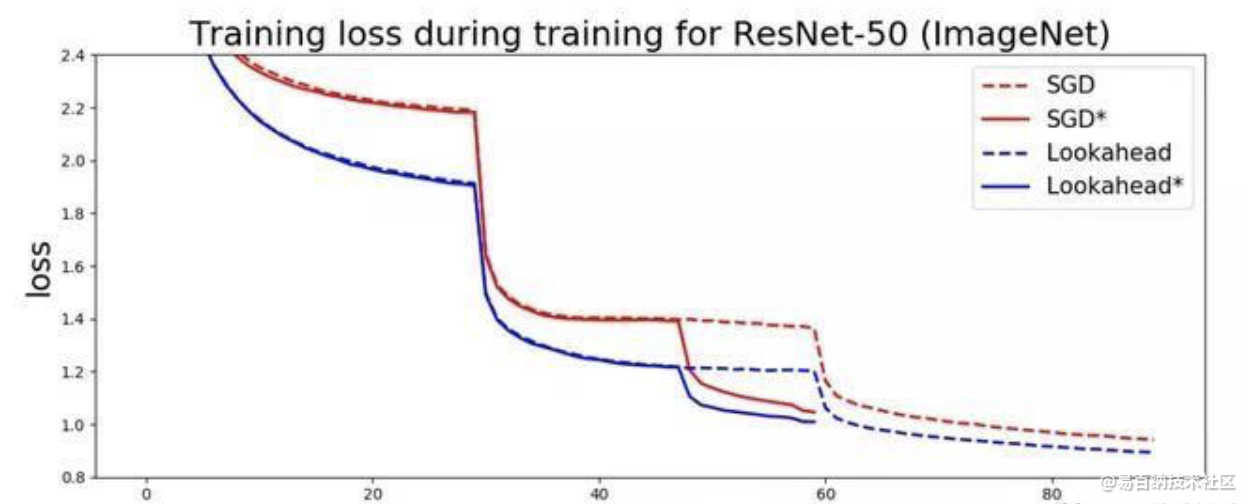
4 Ranger - 一个使用RAdam和LookAhead的优化器的集成代码库。
Lookahead可以与任何优化器一起运行以获得“快速”权重 - 该文件使用了vanilla Adam,因为RAdam在一个月前甚至没有。

然而,为了便于与FastAI进行代码集成以及一般的使用简单性,我继续将两者合并为一个名为Ranger的单一优化器(Ranger中的RA用于向Rectified Adam致敬,Ranger作为一个整体名称,因为LookAhead是杰出的 探索失落的地形,就像一个真正的Ranger。
在github上有几个LookAhead的实现,我从LonePatient开始,因为我喜欢它的代码简洁,然后构建在它上面。RAdam当然是来自官方的RAdam github代码库。
Ranger的源文件在这里:
https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
如何使用:
1 - 将ranger.py复制到您的工作目录。
2 - import ranger:
LookAhead参数:
k参数:- 它控制在与LookAhead权重合并之前要运行的批次数。5或6是常见的默认值,我相信在论文中使用了多达20个。
alpha = this控制要更新的LookAhead差异的百分比。.5是默认值。Hinton等人强有力地证明.5可能是理想的,但可能值得进行简短的实验。
5 结构化知识蒸馏
顾名思义,知识蒸馏是把知识浓缩到“小”网络模型中。一般情况下,在相同的数据上训练,模型参数量较大、计算量大的模型往往精度比较高,而用精度高、模型复杂度高的模型即Teacher网络的输出训练Student网络,以期达到使计算量小参数少的小网络精度提升的方法,就是知识蒸馏。
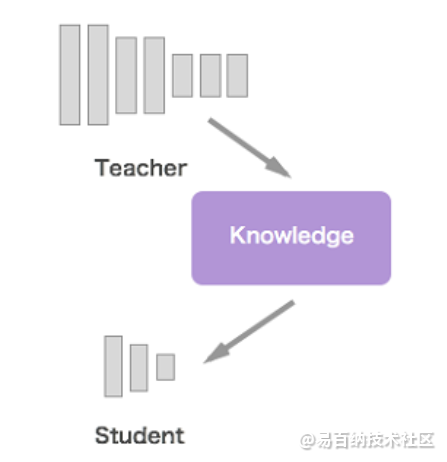
知识蒸馏的好处是显而易见的,使用知识蒸馏后的Student网络能够达到较高的精度,而且更有利于实际应用部署,尤其是在移动设备中。
下面两幅图中,作者展示了使用该文提出的结构化知识蒸馏的语义分割模型在计算量和参数量不变的情况下,精度获得了大幅提升。
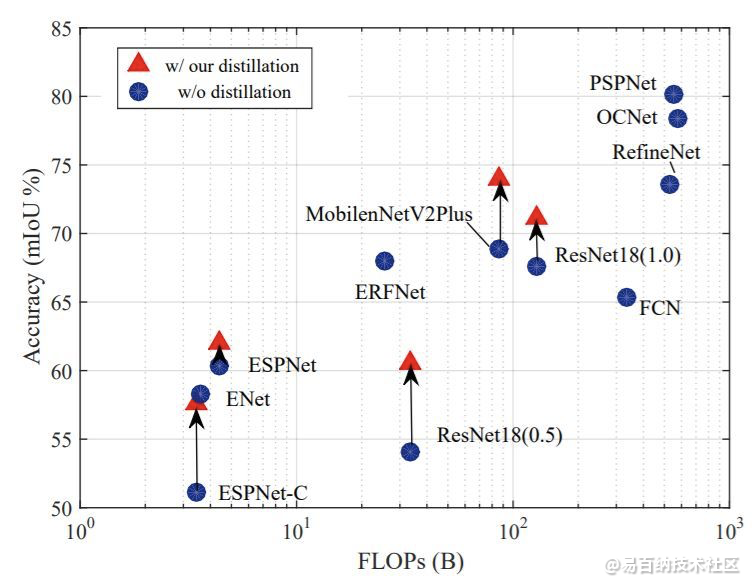
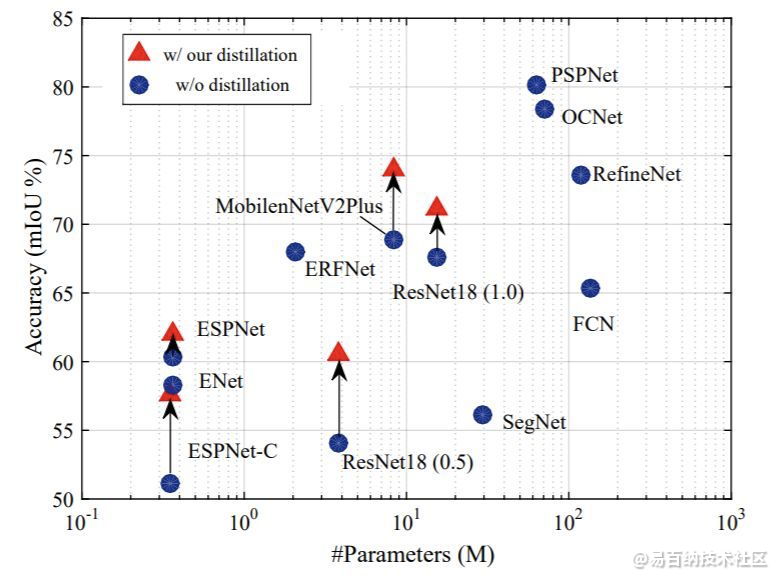
算法原理
知识蒸馏的目标是希望对于Teacher网络和Student网络给定相同的图像,输出结果尽量一样。
所以,知识蒸馏的关键,是如何衡量Teacher网络和Student网络输出结果的一致性,也就是训练过程中的损失函数设计。
该文中作者将语义分割问题看为像素分类问题,所以很自然的可以使用衡量分类差异的逐像素(Pixel-wise)的损失函数Cross entropy loss,这是在最终的输出结果Score map中计算的。
同时作者引入了图像的结构化信息损失,如下图所示。
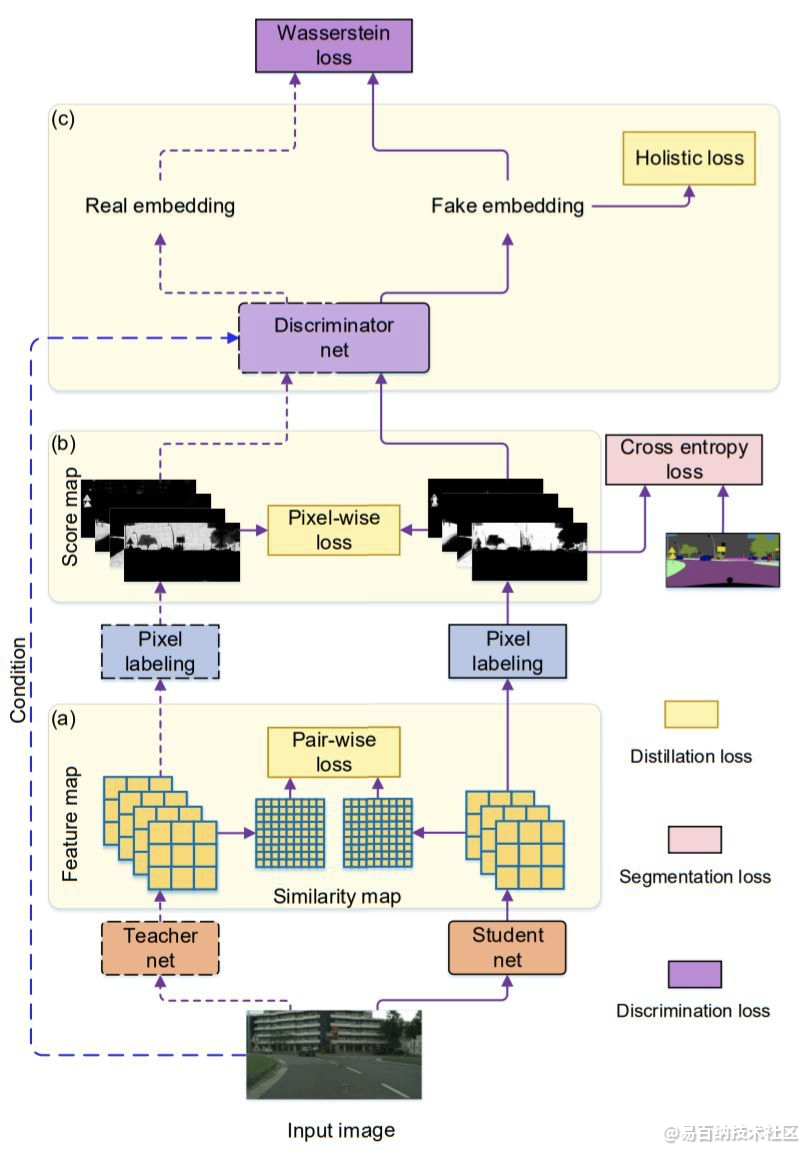
如何理解图像的结构化信息?一种很显然的结构化信息即图像中局部的一致性。在语义分割中,可以简单理解为,预测结果中存在的自相似性,作者衡量这种结构化信息的方式是Teacher预测的两像素结果和Student网络预测的两像素结果一致。衡量这种损失,作者称之为Pair-wise loss(也许可以翻译为“逐成对像素”损失)。
另一种更高层次的结构化信息是来自对图像整体结构相似性的度量,作者引入了对抗网络的思想,设计专门的网络分支分类Teacher网络和Student网络预测的结果,网络收敛的结果是该网络不能再区分Teacher网络和Student网络的输出。作者称这块损失函数为Holistic loss(整体损失)。
仔细想想,作者设计的损失函数的三部分,逐像素的损失(Pixel-wise loss,PI)、逐像素对的损失(Pair-wise loss,PA)、整体损失(Holistic loss,HO)都很有道理,是不是?
作者使用ResNet18网络模型在Cityscapes数据集上研究了作者提出的损失函数各部分对结果的影响。(ImN代表用ImageNet预训练模型初始化网络)
结果如下图。
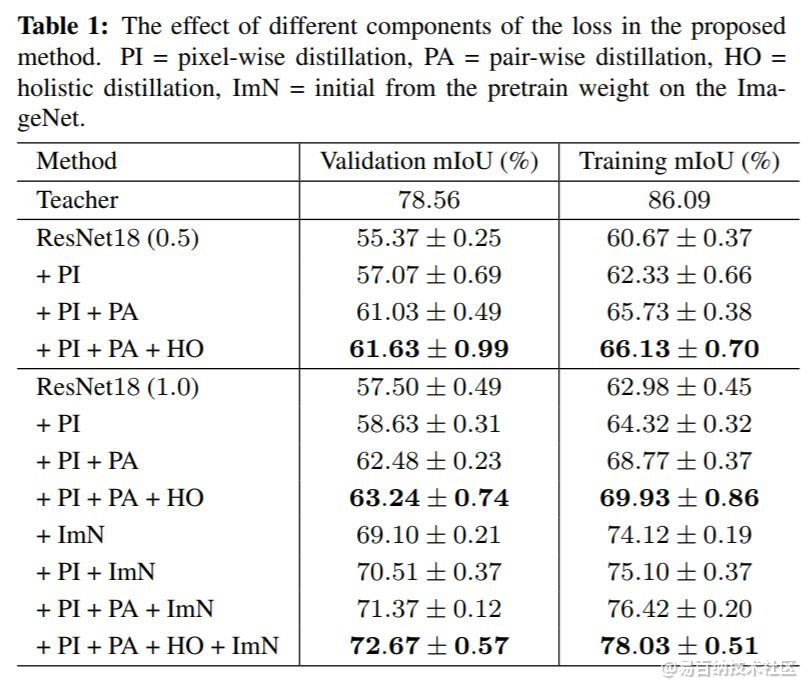
可知,作者提出的损失函数的各个部分都能使得Student网络获得精度增益,最高达15.17%!
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5937次2021-06-17 11:39:26
-
浏览量:10165次2021-05-24 15:12:00
-
浏览量:3359次2023-08-28 18:02:28
-
浏览量:7724次2021-06-24 10:38:30
-
浏览量:4962次2021-05-28 16:59:07
-
浏览量:7043次2021-05-31 17:02:05
-
浏览量:12718次2021-05-04 20:20:07
-
浏览量:881次2023-08-28 09:56:42
-
浏览量:6750次2021-07-14 09:51:09
-
浏览量:1603次2022-12-06 14:45:10
-
浏览量:4634次2021-09-08 09:30:45
-
浏览量:5242次2021-03-29 17:56:49
-
浏览量:841次2024-02-28 15:03:08
-
浏览量:7151次2021-05-24 15:13:24
-
浏览量:6244次2021-07-15 10:44:33
-
浏览量:5874次2021-06-23 15:25:25
-
浏览量:5576次2021-06-21 11:50:25
-
浏览量:6623次2021-06-11 12:41:01
-
浏览量:3235次2020-10-26 10:36:20

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
