

【深度学习】深度学习之对抗样本问题和知识蒸馏技术
文章目录
1 什么是深度学习对抗样本
2 深度学习对于对抗样本表现的脆弱性产生的原因
3 深度学习的对抗训练
4 深度学习中的对抗攻击和对抗防御
5 知识蒸馏技术
5.1 知识蒸馏介绍
5.2 为什么要有知识蒸馏?
5.3 知识蒸馏基本框架1 什么是深度学习对抗样本
Christian Szegedy等人在ICLR2014发表的论文中,他们提出了对抗样本(Adversarial examples)的概念,即在数据集中通过故意添加细微的干扰所形成的输入样本,受干扰之后的输入导致模型以高置信度给出一个错误的输出。在他们的论文中,他们发现包括卷积神经网络(Convolutional Neural Network, CNN)在内的深度学习模型对于对抗样本都具有极高的脆弱性。他们的研究提到,很多情况下,在训练集的不同子集上训练得到的具有不同结构的模型都会对相同的对抗样本实现误分,这意味着对抗样本成为了训练算法的一个盲点。Anh Nguyen等人在CVPR2015上发表的论文中,他们发现面对一些人类完全无法识别的样本(论文中称为Fooling Examples),可是深度学习模型会以高置信度将它们进行分类。这些研究的提出,迅速抓住了公众的注意力,有人将其当做是深度学习的深度缺陷,可是kdnuggets上的一篇文章(Deep Learning’s Deep Flaws)’s Deep Flaws指出,事实上深度学习对于对抗样本的脆弱性并不是深度学习所独有的,在很多的机器学习模型中普遍存在,因此进一步研究有利于抵抗对抗样本的算法实际上有利于整个机器学习领域的进步。
2 深度学习对于对抗样本表现的脆弱性产生的原因
是什么原因造成了深度学习对于对抗样本表现出脆弱性。一个推断性的解释是深度神经网络的高度非线性特征,以及纯粹的监督学习模型中不充分的模型平均和不充分的正则化所导致的过拟合。Ian Goodfellow 在ICLR2015年的论文中,通过在一个线性模型加入对抗干扰,发现只要线性模型的输入拥有足够的维度(事实上大部分情况下,模型输入的维度都比较大,因为维度过小的输入会导致模型的准确率过低),线性模型也对对抗样本表现出明显的脆弱性,这也驳斥了关于对抗样本是因为模型的高度非线性的解释。相反深度学习的对抗样本是由于模型的线性特征。
3 深度学习的对抗训练
所谓深度学习对抗训练,就是通过在对抗样本上训练模型。既然深度学习的对抗样本是由于模型的线性特征所导致,那就可以设计一种快速的方法来产生对抗样本进行对抗训练。Szegedy等人的研究认为对抗样本可以通过使用标准正则化技术解决,可是Goodfellow等人使用常见的正则化方法,如dropout, 预训练和模型平均进行测试,并没能显著地提高深度模型对于对抗样本的抗干扰能力。根据神经网络的Universal Approximation Theory,至少拥有一个隐层的神经网络只要拥有足够的隐层单元,就可以任意逼近任何一个非线性函数,这是浅层模型所不具备的。因此,对于解决对抗样本问题,Goodfellow等人认为深度学习至少有希望的,而浅层模型却不太可能。Goodfellow等人通过利用对抗样本训练,对抗样本上的误分率被大大降低。同时他们发现选择原始模型产生的对抗样本作为训练数据可以训练得到具有更高抵抗力的模型。此外,他们还发现,对于误分的对抗样本,对抗训练得到的模型的置信度依然很高。所以通过对抗训练能够提高深度学习的对于对抗样本的抗干扰能力。
4 深度学习中的对抗攻击和对抗防御
在深度学习(deep leaming,DL)算法驱动的数据计算时代,确保算法的安全性和鲁棒性至关重要。最近,研究者发现深度学习算法无法有效地处理对抗样本。这些伪造的样本对人类的判断没有太大影响,但会使深度学习模型输出意想不到的结果。最近,在物理世界中成功实施的一系列对抗性攻击证明了此问题是所有基于深度学习系统的安全隐患。因此有关对抗性攻击和防御技术的研究引起了机器学习和安全领域研究者越来越多的关注。本文将介绍深度学习对抗攻击技术的理论基础、算法和应用。然后,讨论了防御方法中的一些代表性研究成果。这些攻击和防御机制可以为该领域的前沿研究提供参考。此外,文章进一步提出了一些开放性的技术挑战,并希望读者能够从所提出的评述和讨论中受益。
对抗攻击
以下是文中部分攻击方法的描述。
快速梯度符号法(FGSM)
Goodfellow等首先提出了一种有效的无目标攻击方法,称为快速梯度符号法(FGSM),该方法通过在良性样本的L∞范数限制下生成对抗样本,如图1所示。FGSM是典型的一步攻击算法,它沿着对抗性损失函数J(θ, x, y)的梯度方向(即符号)执行一步更新,以增加最陡峭方向上的损失。FGSM生成的对抗性样本表示如下:
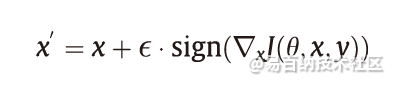
式中,ε 是扰动大小。通过降低J(θ, x, y′)的梯度(其中y′表示目标类别)可以将FGSM轻松地扩展为目标攻击算法(targeted FGSM)。如果将交叉熵作为对抗损失,则此更新过程可以减少预测概率向量和目标概率向量之间的交叉熵。目标攻击算法的梯度更新可以表示为:
基本迭代攻击和投影梯度下降
Kurakin等提出了BIA方法,该方法通过将一个迭代优化器迭代优化多次来提高FGSM的性能。BIA以较小的步长执行FGSM,并将更新后的对抗样本裁剪到有效范围内,通过这样的方式总共T次迭代,在第k次迭代中的梯度更新方式如下:
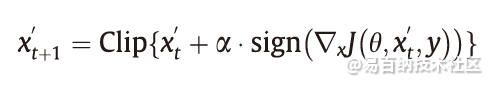
上述所有攻击都是针对良性样本来精心设计对抗性扰动的。换句话说,对抗性扰动不会在良性样本之间传递。因此一个自然的问题是:是否存在一种普遍的扰动会欺骗大多数良性样本的网络?在每次迭代中,对于当前扰动无法欺骗的良性样本,将求解一个类似于L-BFGS的优化问题,以找到危害这些样本所需的最小附加扰动。附加扰动将添加到当前扰动中。最终,扰动使大多数良性样本欺骗了网络。实验表明,这种简单的选代算法可以有效地攻击深度神经网络,如CaffeNet、GoogleNet、VGG和ResNet。出乎意料的是,这种可在不同样本中传递的扰动同时可以应用到其他不同的模型中,例如,在VGG上制作的通用扰动在其他模型上也可以达到53%以上的欺骗率。
对抗防御
对抗训练
对抗训练是一种针对对抗样本的直观防御方法,该方法试图通过利用对抗样本进行训练来提高神经网络的鲁棒性。从形式上讲,这是一个Min-Max的游戏,可以表述为:
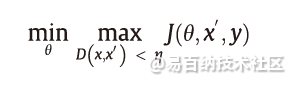
式中,J(θ, x′, y)是对抗损失函数;θ是网络权重;x′是对抗输入;y是标签真值。D(x, x′)表示x和x′之间的某种距离度量。内部的最大化优化问题是找到最有效的对抗样本,这可以通过精心设计的对抗攻击实现,如FGSM和PGD。外部的最小化优化问题是损失函数最小化的标准训练流程。最终的网络应该能够抵抗训练阶段用的生成对抗性样本的对抗性攻击。最近的研究表明:对抗性训练是对抗性攻击最有效的防御手段之一。主要是因为这种方法在几个基准数据集上达到了最高的精度。因此在本节中,我们将详细介绍过去几年里表现最好的对抗训练技术。
FGSM 对抗训练:Goodfellow等首先提出用良性和FGSM生成的对抗样本训练神经网络以增强网络其鲁棒性的方法。他们提出的对抗目标函数可以表达为:
随机化
最近的许多防御措施都采用随机化来减轻输入/特征域中对抗性扰动的影响,因为从直觉上看,DNN总是对随机扰动具有鲁棒性。基于随机化的防御方法试图将对抗性效应随机化为随机性效应,当然这对大多数DNN而言都不是问题。在黑盒攻击和灰盒攻击的设置下,基于随机化的防御获得了不错的性能,但是在白盒攻击下,EoT方法能够通过在攻击过程中考虑随机过程来破坏大多数防御方法。本节将详细介绍几种基于随机化的代表性防御方式,并介绍其针对不同环境中各种防御的性能。
去噪
就减轻对抗性扰动/效果而言,降噪是一种非常简单的方法。之前的工作指出了设计这种防御的两个方向,包括输入降噪和特征图降噪。其中第一个方向试图从输入中部分或完全消除对抗性扰动,第二个方向是减轻对抗性扰动对DNN学习高级功能的影响。本节将详细介绍这两个方向上的几种著名防御方法。
5 知识蒸馏技术
5.1 知识蒸馏介绍
什么是知识蒸馏?
在化学中,蒸馏是一种有效的分离不同沸点组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。化学蒸馏条件:
(1)蒸馏的液体是混合物;(2)各组分沸点不同。
蒸馏的液体是混合物,这个混合物一定是包含了各种组分,即在我们今天讲的知识蒸馏中指原模型包含大量的知识。各组分沸点不同,蒸馏时要根据目标物质的沸点设置蒸馏温度,即在我们今天讲的知识蒸馏中也有“温度”的概念,那这个“温度“代表了什么,又是如何选取合适的”温度“?这里先埋下伏笔,在文中给大家揭晓答案。
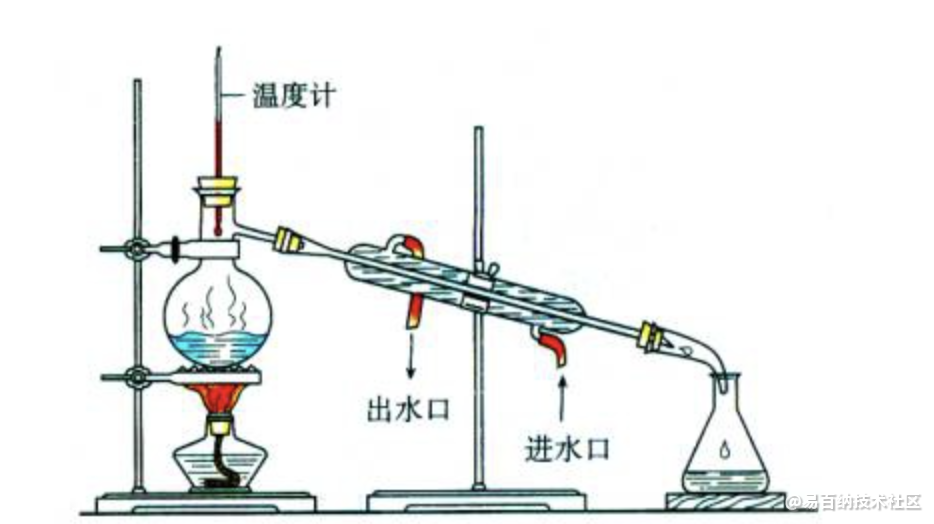
进入我们今天正式的主题,到底什么是知识蒸馏?一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
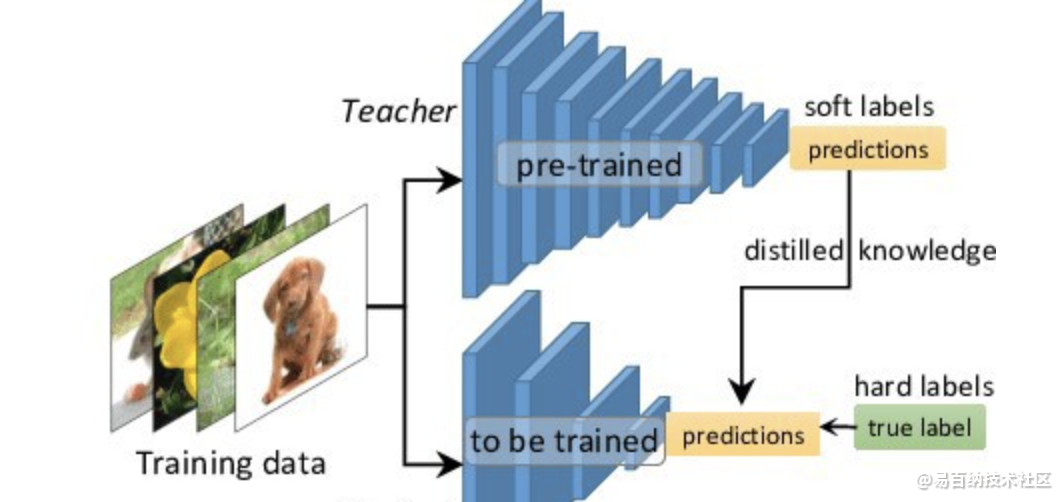
Hinton等人最早在文章《Distilling the Knowledge in a Neural Network》中提出了知识蒸馏这个概念,其核心思想是先训练一个复杂网络模型,然后使用这个复杂网络的输出和数据的真实标签去训练一个更小的网络,因此知识蒸馏框架通常包含了一个复杂模型(被称为Teacher模型)和一个小模型(被称为Student模型)。
5.2 为什么要有知识蒸馏?
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,大多数模型在计算上过于昂贵,无法在移动端或嵌入式设备上运行。因此需要对模型进行压缩,且知识蒸馏是模型压缩中重要的技术之一。
(1)提升模型精度
如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的A模型。
(2)降低模型时延,压缩网络参数
如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
(3)标签之间的域迁移
假如使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗、猫、香蕉以及苹果的模型,将两个不同域的数据集进行集成和迁移。
因此,在工业界中对知识蒸馏和迁移学习也有着非常强烈的需求。
5.3 知识蒸馏基本框架
知识蒸馏采取Teacher-Student模式:将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
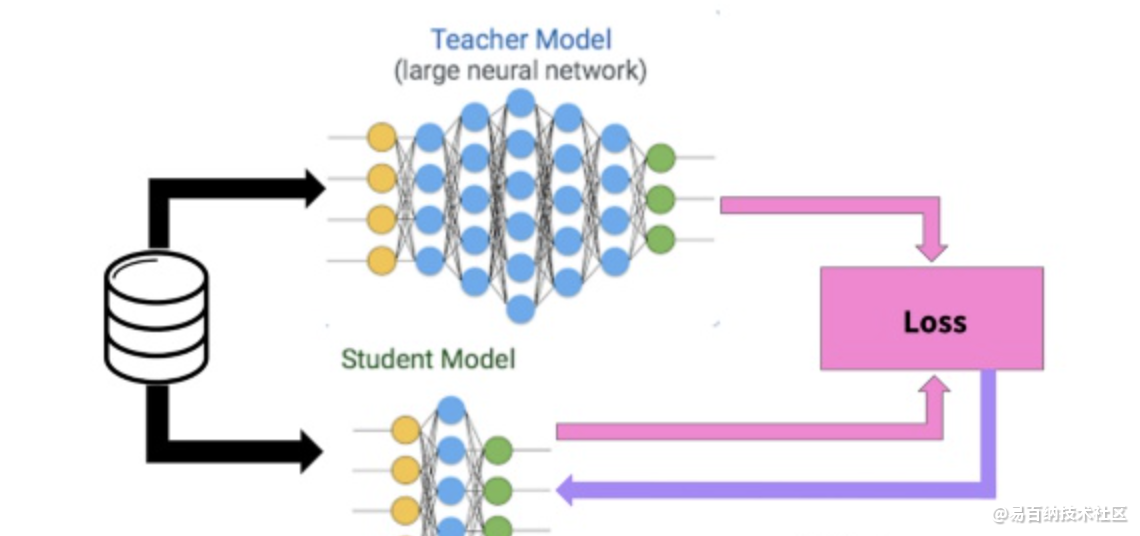
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向,下面我们对其进行介绍。
知识蒸馏
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法。
知识蒸馏损失函数:
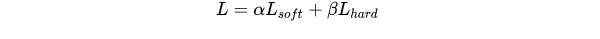

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4689次2021-05-26 15:42:50
-
浏览量:6667次2021-05-24 15:12:30
-
浏览量:7151次2021-05-24 15:13:24
-
浏览量:881次2023-08-28 09:56:42
-
浏览量:7817次2021-06-15 10:28:29
-
浏览量:5362次2021-08-05 09:21:07
-
浏览量:5527次2021-08-05 09:20:49
-
浏览量:7322次2021-05-04 20:17:10
-
浏览量:1306次2023-09-08 10:47:07
-
浏览量:4855次2023-09-04 14:32:32
-
浏览量:14753次2021-06-15 10:27:34
-
浏览量:6551次2021-06-11 10:08:48
-
浏览量:4838次2021-04-09 16:28:04
-
浏览量:4860次2021-05-18 15:15:50
-
浏览量:18030次2021-06-07 17:47:54
-
浏览量:254次2023-07-25 11:30:01
-
浏览量:5937次2021-06-17 11:39:26
-
浏览量:6080次2021-08-12 14:06:09
-
浏览量:6186次2021-06-15 11:49:53

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
