

【深度学习】移动翻转瓶颈卷积的实现
【深度学习】移动翻转瓶颈卷积的实现(mobile inverted bottleneck convolution)
文章目录
1 MBConv
1.1 Depthwise Convolution
1.2 SE-Net
1.3 EfficientNet-B0网络结构
2 卷积层的变体和替代
3 MobileNetV31 MBConv
移动翻转瓶颈卷积(mobile inverted bottleneck convolution,MBConv),类似于 MobileNetV2 和 MnasNet,由深度可分离卷积Depthwise Convolution和SENet构成。
每个MBConv的网络结构如下:
MBConv = 1x1升维 + Depthwise Convolution + SENet + 1x1降维 + add
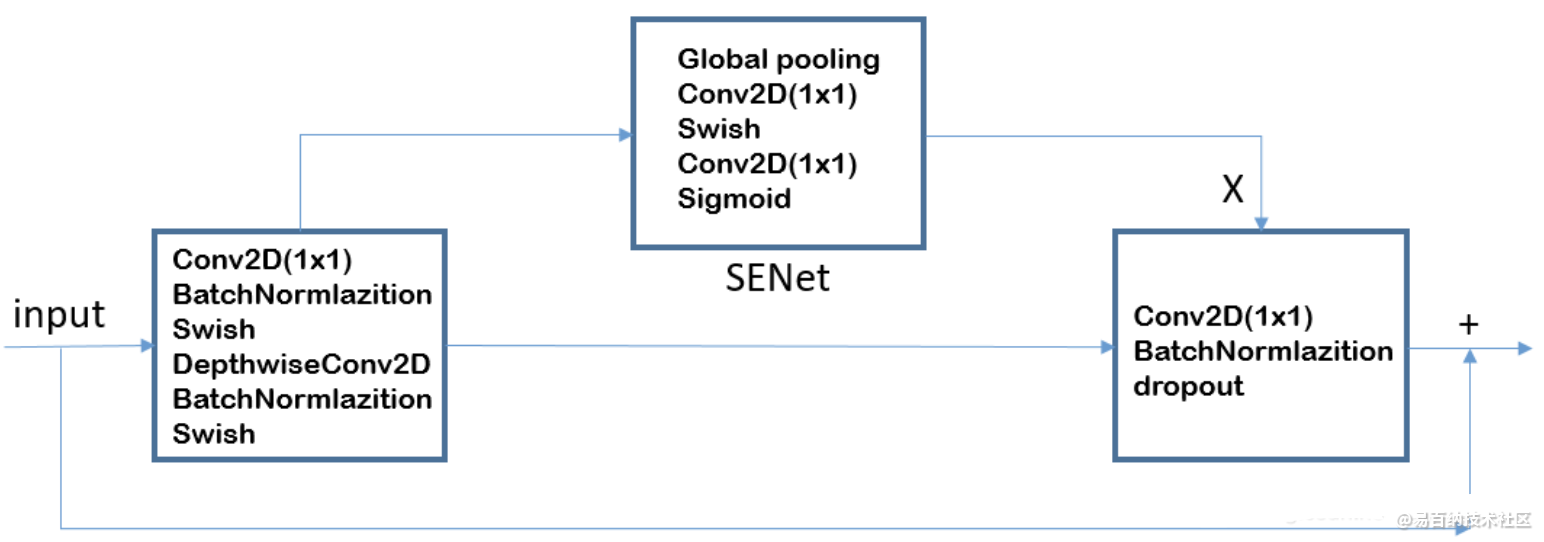
1.1 Depthwise Convolution


1.2 SE-Net
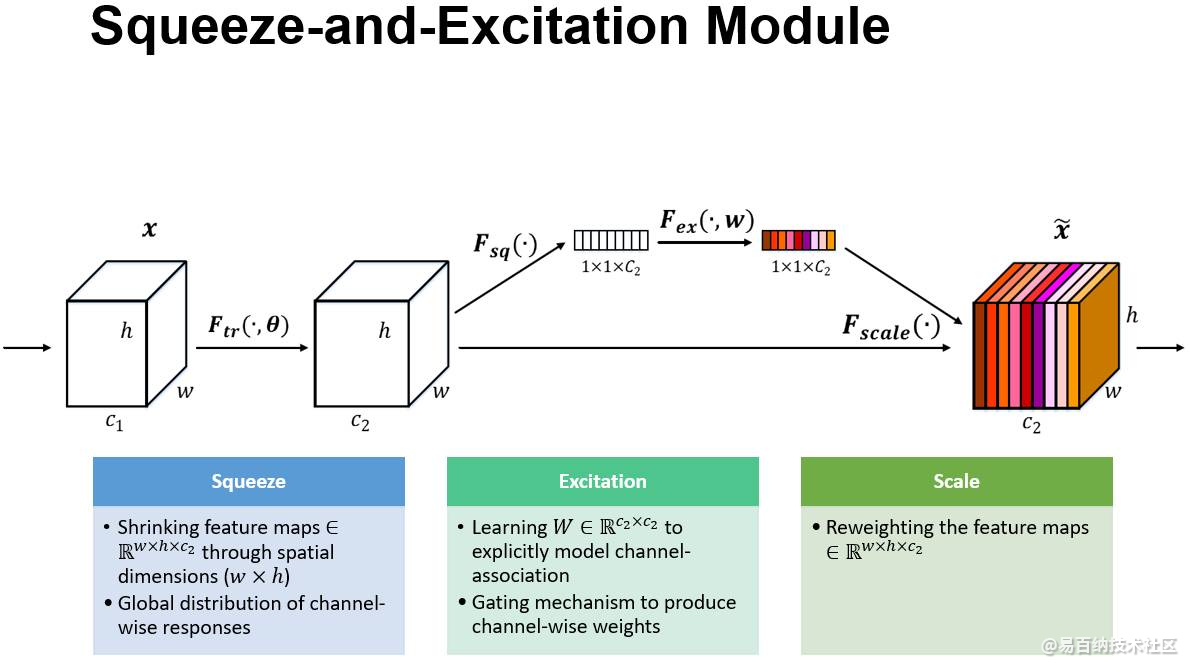
上图是我们提出的 SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来我们通过三个操作来重标定前面得到的特征。
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
1.3 EfficientNet-B0网络结构
1.该网络结构 = 16个MBConv + 2个Conv + 1个Global average pooling + 1个FC分类层;
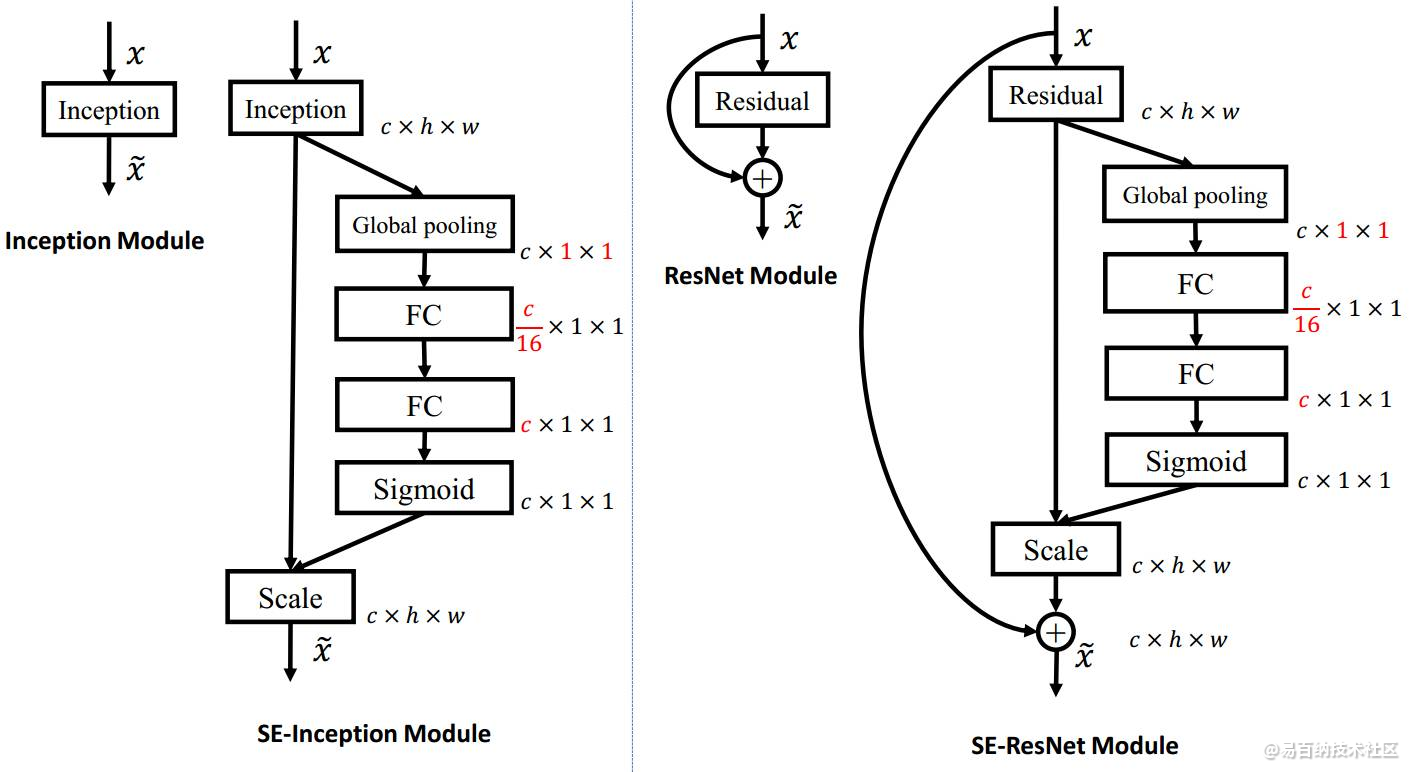
2.该网络利用了移动翻转瓶颈卷积(mobile inverted bottleneck convolution,MBConv)模块,还引入了压缩与激发网络(Squeeze-and-Excitation Network,SENet)的注意力思想。
网络整体结构如下:
基线B0的16个Block结构如下:
BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16,
expand_ratio=1, id_skip=True, strides=[1, 1], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112,
expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192,
expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320,
expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25)
2 卷积层的变体和替代
在MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 中提出将Conv + BN + ReLU分解为DepthwiseConv + BN +ReLU + PointwiseConv + BN + ReLU.
这就是一个深度可分离卷积神经网络哦~~~还不是完整的MNConv。
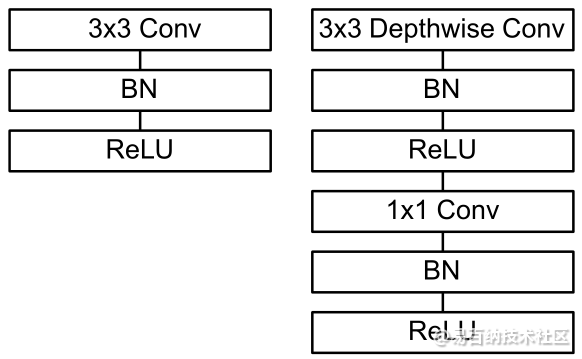
Xception 使用了去掉中间激活函数的变体.
在MobileNetV2中DepthwiseConv被整合到一般的残差结构中用于取代中间的卷积操作, 并去掉了最后一个激活函数. 此外, 与原本先降维再升维相反, 新的残差结构先对输入进行升维.

SE结构在MobileNetV3中被有选择性地加到DepthwiseConv这一层上.
3 MobileNetV3
MobilenetV3继承V1 的 Depthwise separable convolution、V2的先放大再收缩的概念,并加入了Squeeze-and-Excitation Networks,所以整个架构上与EfficientNet的MBConvBlock很相似。
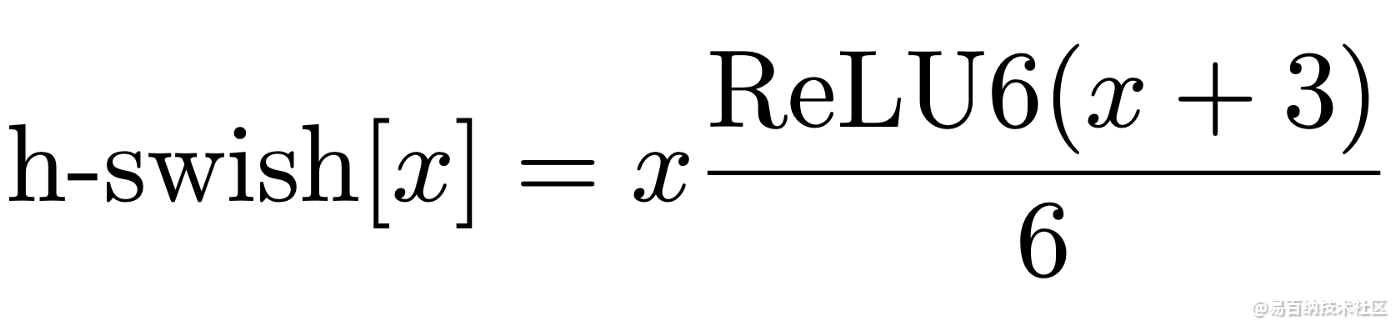
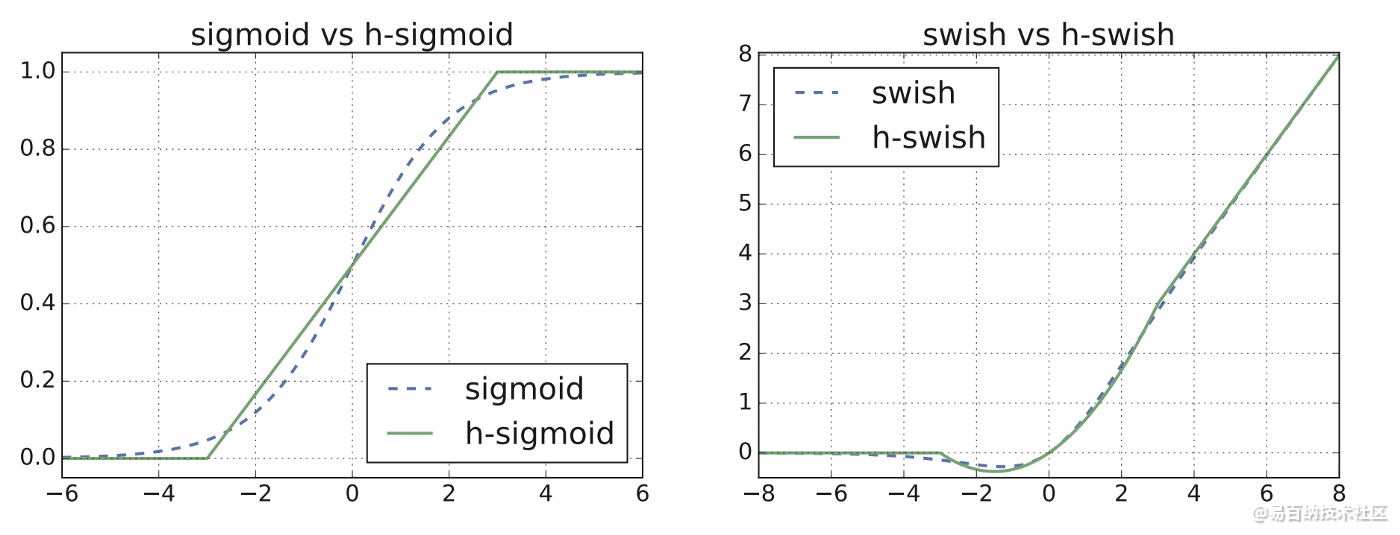
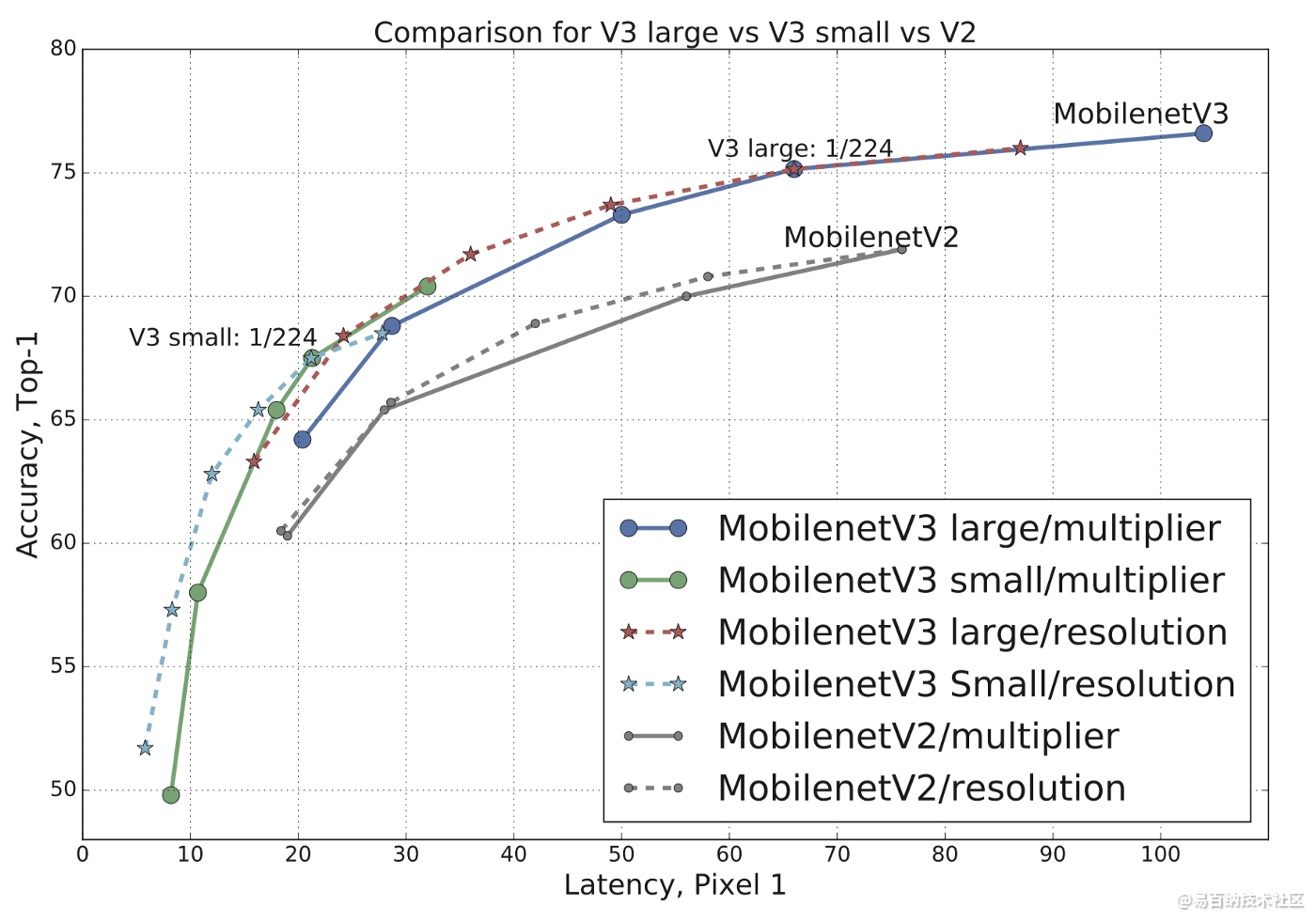
下图为MobileNetV3与 V2的比较图,可以发现相同Latency下,V3模型在Top-1 Accuracy上都较胜出。
代码实现Bottleneck:
import tensorflow as tf
def Hswish(input_):
return input_* tf.nn.relu6(input_ + 3.) / 6.
def Hsigmoid(input_):
return tf.nn.relu6(input_ + 3.) / 6.
def depthwise_conv(
x, kernel=3, stride=1, padding='SAME',
activation_fn=None, normalizer_fn=None,
weights_initializer=tf.contrib.layers.xavier_initializer(),
data_format='NHWC', scope='depthwise_conv'): ##一般的depthwise_conv
with tf.variable_scope(scope):
assert data_format == 'NHWC'
in_channels = x.shape[3].value
W = tf.get_variable(
'depthwise_weights',
[kernel, kernel, in_channels, 1], dtype=tf.float32,
initializer=weights_initializer
)
x = tf.nn.depthwise_conv2d(x, W, [1, stride, stride, 1], padding, data_format='NHWC',)
x = tf.layers.batch_normalization(x) if normalizer_fn is not None else x # batch normalization
x = tf.nn.leaky_relu(x) if activation_fn is not None else x # nonlinearity
return x
def SEBlock(input_, squeeze=4):
in_dim=int(input_.get_shape().as_list()[-1])
Squeeze = tf.layers.average_pooling2d(input_, input_.get_shape()[1:-1], 1)
Squeeze = tf.nn.relu(tf.layers.dense(Squeeze, use_bias=False, units=in_dim//squeeze))
Excitation = tf.nn.relu(tf.layers.dense(Squeeze, use_bias=False, units=in_dim))
Excitation = Hsigmoid(Excitation) ##Hsigmoid replace Sigmoid
Excitation = tf.reshape(Excitation, [-1,1,1,in_dim])
return input_*Excitation
def MobileV3Bottleneck(input_,expand_size, squeeze,out_size, kernel_size,stride=1, relu=True, se=True):
Shortcut = input_
in_dim = int(input_.get_shape().as_list()[-1])
out = tf.layers.batch_normalization(tf.layers.conv2d(input_,expand_size, (1,1), (1,1), use_bias=False))
if relu:
out = tf.nn.relu(out) #or relu6
else:
out = Hswish(out)
out = depthwise_conv(out, kernel=kernel_size, stride=stride, padding='SAME')
out = tf.layers.batch_normalization(out)
if relu:
out = tf.nn.relu(out) #or relu6
else:
out = Hswish(out)
out = tf.layers.batch_normalization(tf.layers.conv2d(out, out_size, (1,1), (1,1), use_bias=False))
if (in_dim != out_size) and (stride == 1):
Shortcut = tf.layers.conv2d(Shortcut,out_size, (1,1), strides = (stride, stride), use_bias=False)
Shortcut = tf.layers.batch_normalization(Shortcut)
if se:
assert squeeze <= out_size
out = SEBlock(out,squeeze=squeeze)
out = out + Shortcut if stride == 1 else out
return out
tf.reset_default_graph()
inputs = tf.placeholder(tf.float32, [None, 300, 300, 80])
out = MobileBottleneck(inputs,480,4,112,3,stride=1,relu=False,se=True)
MobileNet:引入Depthwise Separable Convolution (DWConv)
MobileNetv2:在DWConv基础上引入inverted residuals and linear bottlenecks
作者提出了MobileNetV3-Large和MobileNetV3-Small两种不同大小的网络结构。
4 代码分析
以下代码主要实现深度可分离卷积。
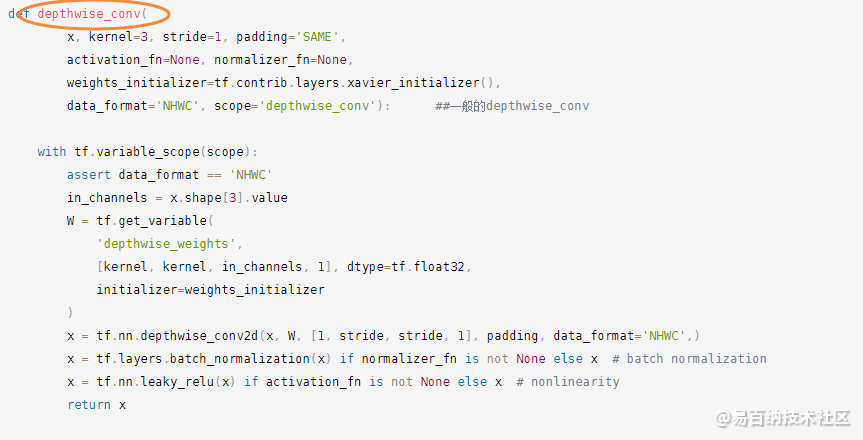
以下代码实现压缩和激励模块。

这与MBConv的实现是类似的。
MnasNet结构分析:
模型使用更多 5x5 depthwise convolutions。对于 depthwise separable convolution, 一个 5x5 卷积核比两个 3x3 卷积核更高效:
假如输入分辨率为(H,W,M),输出分辨率为(H,W,N),C5x5 和 C3x3 分别代表 5x5 卷积核和 3x3 卷积核计算量,通过计算可以看到,N>7 时,C5x5 计算效率大于 C3x3 计算效率:
层分级的重要性。很多轻量化模型重复 block 架构,只改变滤波器尺寸和空间维度。论文提出的层级搜索空间允许模型的各个 block 包括不同的卷积层。轮的ablation study比较了 MnasNet 的各种变体(即单独重复使用各个 block),在准确率和实时性方面难以达到平衡,验证了层分级的重要性。
个人观点:论文使用强化学习的思路,首先确定了 block 的连接方式,在每个 block 使用层级搜索空间,确定每个卷积层的卷积类型,卷积核、跳跃层连接方式,滤波器的尺寸等。如果让强化学习自己选择模型的架构,比如 Encoder-Decoder,U-Net,FPN 等,是否在目标检测语义分割方面有更好的表现。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4581次2021-04-19 14:54:23
-
浏览量:1392次2024-02-01 14:28:23
-
浏览量:12718次2021-05-04 20:20:07
-
浏览量:1549次2024-02-06 11:56:53
-
浏览量:5324次2021-07-26 11:28:05
-
浏览量:1143次2024-02-01 14:20:47
-
浏览量:4333次2018-02-14 10:30:11
-
浏览量:1298次2023-04-04 11:14:12
-
浏览量:7162次2021-05-06 12:40:04
-
浏览量:1044次2023-09-18 15:02:26
-
浏览量:2127次2024-02-06 11:41:16
-
浏览量:189次2023-07-30 17:57:28
-
浏览量:1125次2023-07-05 10:11:45
-
浏览量:5143次2021-04-21 17:05:28
-
浏览量:2015次2022-12-08 17:12:46
-
浏览量:6583次2021-08-03 11:36:37
-
浏览量:6411次2021-08-03 11:36:18
-
浏览量:7208次2021-04-19 14:56:57
-
浏览量:7817次2021-06-15 10:28:29

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
