

【深度学习】U-Net 网络分割多分类医学图像解析
【深度学习】U-Net 网络分割多分类医学图像解析
文章目录
【深度学习】U-Net 网络分割多分类医学图像解析
1 U-Net 多分类
2 Keras 利用Unet进行多类分割
2.1 代码实现
2.2 结果
3 多分类标签验证
4 数据变换
4.1 概述
4.2 图像数据变化代码(为了满足多分类需求)
4.3 随机亮度(为了数据增强)
5 Unet训练自己的数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

1 U-Net 多分类
Unet图像分割在大多的开源项目中都是针对于二分类,理论来说,对于多分类问题,依旧可行。
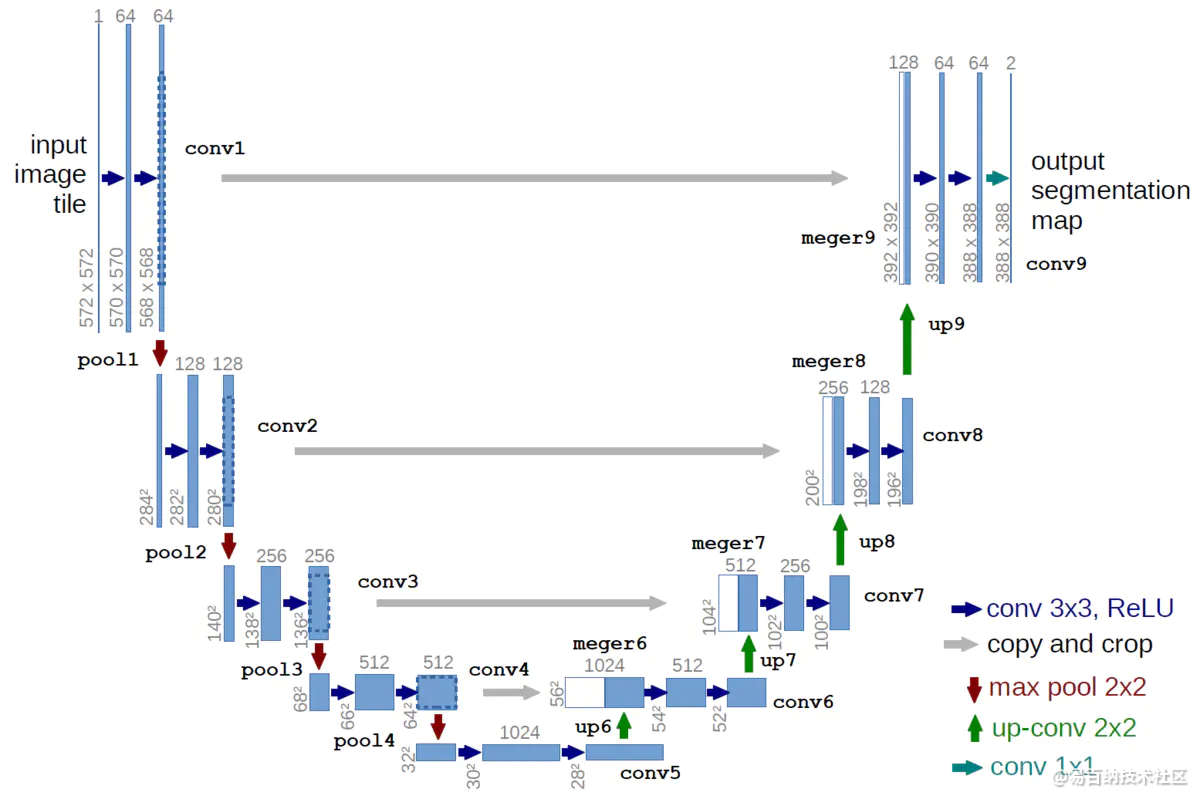
U-net前半部分作用是特征提取,后半部分是上采样。在一些文献中也把这样的结构叫做编码器-解码器结构。由于此网络整体结构类似于大写的英文字母U,故得名U-net。
U-net与其他常见的分割网络有一点非常不同的地方:U-net采用了完全不同的特征融合方式:拼接,U-net采用将特征在channel维度拼接在一起,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征。
所以语义分割网络在特征融合时有两种办法:
FCN式的对应点相加,对应于TensorFlow中的tf.add()函数;
U-net式的channel维度拼接融合,对应于TensorFlow的tf.concat()函数,比较占显存。
除了上述新颖的特征融合方式,U-net还有以下几个优点:
1、5个pooling layer实现了网络对图像特征的多尺度特征识别。
2、上采样部分会融合特征提取部分的输出,这样做实际上是将多尺度特征融合在了一起,以最后一个上采样为例,它的特征既来自第一个卷积block的输出(同尺度特征),也来自上采样的输出(大尺度特征),这样的连接是贯穿整个网络的,你可以看到上图的网络中有四次融合过程,相对应的FCN网络只在最后一层进行融合。
2 Keras 利用Unet进行多类分割
2.1 代码实现
所采用的数据集是CamVid,图片尺寸均为360*480,训练集367张,校准集101张,测试集233张,共计701张图片。所采用的深度学习框架是tensorflow+keras.数据来源在此:https://github.com/preddy5/segnet/tree/master/CamVid
我们从main2.py开始查看整个项目的实现步骤。
# -*- coding:utf-8 -*-
# Author : Ray
# Data : 2019/7/25 2:15 PM
from datapre2 import *
from model import *
import warnings
warnings.filterwarnings('ignore') #忽略警告信息
# os.environ['CUDA_VISIBLE_DEVICES'] = '0' #设置GPU
#测试集233张,训练集367张,校准集101张,总共233+367+101=701张,图像大小为360*480,语义类别为13类
aug_args = dict( #设置ImageDataGenerator参数
rotation_range = 0.2,
width_shift_range = 0.05,
height_shift_range = 0.05,
shear_range = 0.05,
zoom_range = 0.05,
horizontal_flip = True,
vertical_flip = True,
fill_mode = 'nearest'
)
train_gene = trainGenerator(batch_size=2,aug_dict=aug_args,train_path='CamVid/',
image_folder='train',label_folder='trainannot',
image_color_mode='rgb',label_color_mode='rgb',
image_save_prefix='image',label_save_prefix='label',
flag_multi_class=True,save_to_dir=None
)
val_gene = valGenerator(batch_size=2,aug_dict=aug_args,val_path='CamVid/',
image_folder='val',label_folder='valannot',
image_color_mode='rgb',label_color_mode='rgb',
image_save_prefix='image',label_save_prefix='label',
flag_multi_class=True,save_to_dir=None
)
tensorboard = TensorBoard(log_dir='./log')
model = unet(num_class=13)
model_checkpoint = ModelCheckpoint('camvid.hdf5',monitor='val_loss',verbose=1,save_best_only=True)
history = model.fit_generator(train_gene,
steps_per_epoch=100,
epochs=20,
verbose=1,
callbacks=[model_checkpoint,tensorboard],
validation_data=val_gene,
validation_steps=50 #validation/batchsize
)
# model.load_weights('camvid.hdf5')
test_gene = testGenerator(test_path='CamVid/test')
results = model.predict_generator(test_gene,233,verbose=1)
saveResult('CamVid/testpred/',results)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
从上述代码中可以看到,整个项目的思路比较明确,概括而言就是:
数据准备
模型训练
预测结果- 1
- 2
- 3
先利用trainGenerator、valGenerator准备训练数据,利用tensorboard = TensorBoard(log_dir='./log')保存日志信息,能够查看训练过程的loss、acc变化。调用ModelCheckpoint保存模型。模型训练时采用fit_generator模式输入。最后在调用predict_generatorj进行预测时先准备好测试集数据,然后调用saveResult保存预测结果。
注意到main.py中在model.fit_generator()中设置callbacks=[model_checkpoint,tensorboard],我们可以在训练结束之后查阅loss和acc的训练过程。
打开terminal,进入项目所在路径,输入tensorboard --logdir ./log(是你代码中所写的),然后出现以下界面就说明你的路径正确了
在浏览器键入http://http:localhost:6006即可查阅loss及acc的训练过程。
2.2 结果
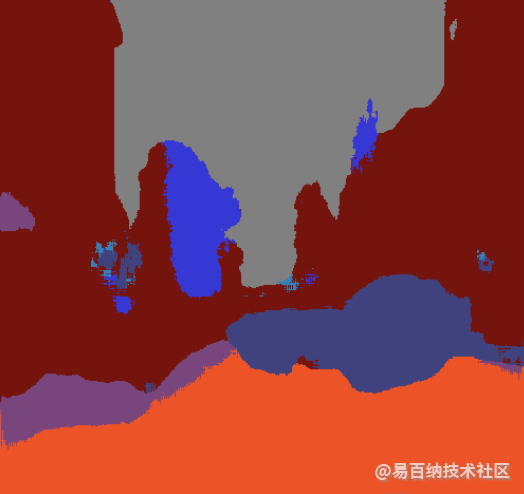
3 多分类标签验证
0 255 128=>0 1 2
a = np.unique(A)
对于一维数组或者列表,unique函数去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表
import numpy as np
A = [1, 2, 2, 5,3, 4, 3]
a = np.unique(A)
B= (1, 2, 2,5, 3, 4, 3)
b= np.unique(B)
C= ['fgfh','asd','fgfh','asdfds','wrh']
c= np.unique(C)
print(a)
print(b)
print(c)
# 输出为 [1 2 3 4 5]
# [1 2 3 4 5]
# ['asd' 'asdfds' 'fgfh' 'wrh']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
c,s=np.unique(b,return_index=True)
return_index=True表示返回新列表元素在旧列表中的位置,并以列表形式储存在s中。
a, s= np.unique(A, return_index=True)
print(a)
print(s)
运行结果
[1 2 3 4 5]
[0 1 4 5 3]
a, s,p = np.unique(A, return_index=True, return_inverse=True)
return_inverse=True 表示返回旧列表元素在新列表中的位置,并以列表形式储存在p中
a, s,p = np.unique(A, return_index=True, return_inverse=True)
print(a)
print(s)
print(p)
运行结果
[1 2 3 4 5]
[0 1 4 5 3]
1. 对于一维列表或数组A:
import numpy as np
A = [1, 2, 2, 3, 4, 3]
a = np.unique(A)
print a # 输出为 [1 2 3 4]
a, b, c = np.unique(A, return_index=True, return_inverse=True)
print a, b, c # 输出为 [1 2 3 4], [0 1 3 4], [0 1 1 2 3 2]
2. 对于二维数组(“darray数字类型”):
A = [[1, 2], [3, 4], [5, 6], [1, 2]]
A = np.array(A) #列表类型需转为数组类型
a, b, c = np.unique(A.view(A.dtype.descr * A.shape[1]), return_index=True, return_inverse=True)
print a, b, c #输出为 [(1, 2) (3, 4) (5, 6)], [0 1 2], [0 1 2 0]
可以看出, Python中unique函数与Matlab完全一致. - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
数据预处理最重要的一步就是要对gt进行one-hot编码,
4 数据变换
4.1 概述
图像方面的数据增强可以从下面几个角度来看.
仿射变换 (Random crop, Random flip, Random rotation, Random zoom, Random shear, Random translation…)
彩色失真 (Random gamma, Random brightness, Random hue, Random contrast, Gaussian Noise …)
信息丢弃(Gridmask, Cutout, Random Erasing, Hide-and-seek…)
多图融合(Mixup, Cutmix, Fmix…)
另类 (Augmix …)
4.2 图像数据变化代码(为了满足多分类需求)
下面代码主要目的是将一个不符合网络输出要求的图像进行处理,可以理解为一个标准化的流程。
class CenterCrop(object):
def __init__(self, size):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img, mask):
assert img.size == mask.size
w, h = img.size
th, tw = self.size
x1 = int(math.ceil((w - tw) / 2.))
y1 = int(math.ceil((h - th) / 2.))
return img.crop((x1, y1, x1 + tw, y1 + th)), mask.crop((x1, y1, x1 + tw, y1 + th))
class SingleCenterCrop(object):
def __init__(self, size):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
def __call__(self, img):
w, h = img.size
th, tw = self.size
x1 = int(math.ceil((w - tw) / 2.))
y1 = int(math.ceil((h - th) / 2.))
return img.crop((x1, y1, x1 + tw, y1 + th))
class CenterCrop_npy(object):
def __init__(self, size):
self.size = size
def __call__(self, img, mask):
assert img.shape == mask.shape
if (self.size <= img.shape[1]) and (self.size <= img.shape[0]):
x = math.ceil((img.shape[1] - self.size) / 2.)
y = math.ceil((img.shape[0] - self.size) / 2.)
if len(mask.shape) == 3:
return img[y:y + self.size, x:x + self.size, :], mask[y:y + self.size, x:x + self.size, :]
else:
return img[y:y + self.size, x:x + self.size, :], mask[y:y + self.size, x:x + self.size]
else:
raise Exception('Crop shape (%d, %d) exceeds image dimensions (%d, %d)!' % (
self.size, self.size, img.shape[0], img.shape[1]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
4.3 随机亮度(为了数据增强)
随机亮度通过调整图像像素值改变图像亮度,这种方式对图像进行数据增强的代码如下:
defrandom_brightness():
results = np.copy(batch_xs)
fori inrange( 9):
image = sess.run(tf.image.random_brightness(batch_xs[i].reshape( 28, 28), 0.9))
results[i, :, :, :] = image.reshape( -1, 28, 28)
show_images(results, "random_brightness")

5 Unet训练自己的数据
整个模型训练过程如下图所示:
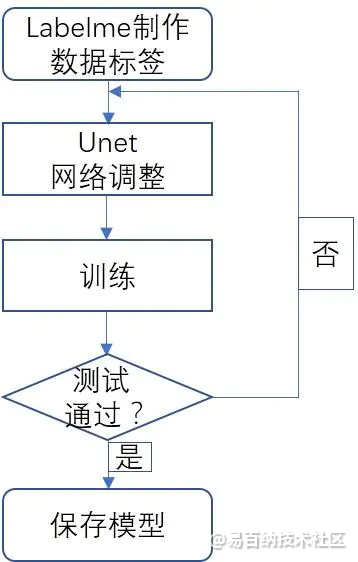
Unet网络调参
网络调参涉及以下几个方面:
(1)加入BN层
(2)将最后一层激活函数替换成ReLU
(3)损失函数替换成mse
多分类一般最后一层原本是softmax,使用了这个激活函数跑完后,没有达到分割效果,所以替换成了之前做过的图对图项目激活函数,效果就出来了,纯属经验之谈,理论还没有进行验证。多分类的损失函数多是交叉熵,经过验证也是不能达到效果,替换成均方根误差。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4350次2021-04-19 14:54:23
-
浏览量:15735次2021-05-31 17:01:00
-
浏览量:6641次2021-06-07 09:26:53
-
浏览量:8887次2021-07-19 17:09:44
-
浏览量:7440次2021-07-19 17:10:27
-
浏览量:7562次2021-07-19 17:08:40
-
浏览量:13486次2021-07-05 09:47:30
-
浏览量:6923次2021-04-08 11:11:30
-
浏览量:157次2023-08-30 15:28:02
-
浏览量:9298次2021-06-21 11:49:58
-
浏览量:7326次2021-06-07 09:27:26
-
浏览量:14427次2021-05-04 20:16:03
-
浏览量:961次2023-06-03 15:59:06
-
浏览量:15948次2021-07-29 10:22:10
-
浏览量:5154次2021-04-12 16:28:50
-
浏览量:14506次2021-05-11 15:09:38
-
浏览量:5169次2021-06-09 14:02:36
-
浏览量:6839次2021-06-08 14:50:34
-
浏览量:11161次2021-06-25 15:00:55

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
