

【深度学习】nnU-Net(优秀的前处理和后处理框架)
【深度学习】nnU-Net(优秀的前处理和后处理框架)
1 概述
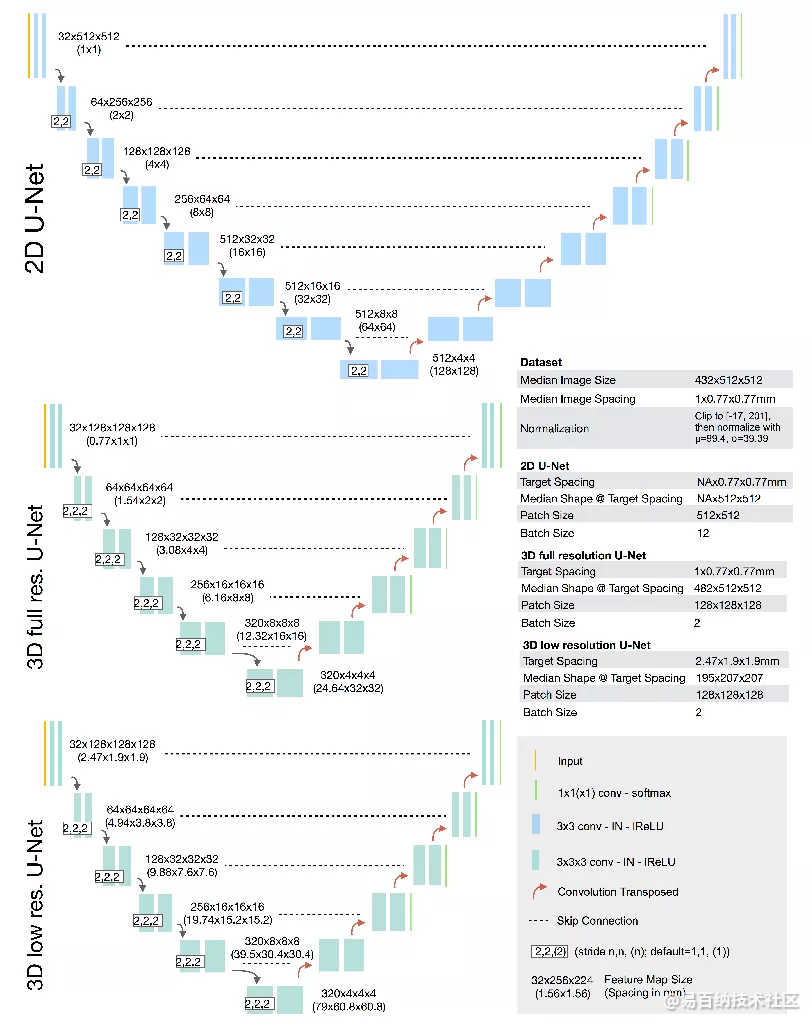
2 网络结构
3 training部分
3.1 nnUNetTrainer(版本一的训练方法)
3.2 nnUNetTrainerV2(版本二的训练方法)
4 前处理
5 自适应生成网络结构
6 模型选择
7 训练
8 后处理
9 推理
10 总结1 概述
nnUnet虽然不是新的论文,但是这个框架效果很好。它并没有提出新的网络结构,没有抓人眼球的地方,仅依靠一些技巧,将分割任务进行了大统一,并在很多任务上得到了非常好的成绩上,可以看出作者的功底之深。
对于分割任务,从unet出来之后的几年里,其实在网络结构上已经没有多少的突破了,结构修改越多,反而越容易过拟合。因此作者认为更多的提升其实在于理解数据,并针对医学数据采用适当的预处理和训练方法。
提出一种鲁棒的基于2D UNet和3D UNet的自适应框架nnUMet。作者在各种任务上拿这个框架和目前的STOA方法进行了比较,且该方法不需要手动调参。最终nnUNet得到了最高的平均dice。
作者提出一种nnUNet(no-new-Net)框架,基于原始的UNet(很小的修改),不去采用哪些新的结构,如相残差连接、dense连接、注意力机制等花里胡哨的东西。相反的,把重心放在:预处理(resampling和normalization)、训练(loss,optimizer设置、数据增广)、推理(patch-based策略、test-time-augmentations集成和模型集成等)、后处理(如增强单连通域等)。
2 网络结构
基础版UNet:2D UNet,3D UNet,UNet级联(第一级对下采样低分辨率图像进行粗分割,第二级结合第一级的结果进行微调,两级都用UNet)
微小修改:
(1)ReLU换 leaky ReLU(neg.slope 1e-2);
(2)Batch Norm换Instance Norm
默认参数设置:
2D UNet:crop-size<=256x256(中值尺寸小于256时,采用中值尺寸); batch-size<=42; base-channel=30; pooling to size>=8; pooling_num<6
3D UNet: crop-size<=128x128x128(中值尺寸小于128时,采用中值尺寸); batch-size>=2; base_channel=30; pooling to size>=8; poolingnum<6
3 training部分
· 拿到训练plans(计划)
· 初始化数据增强参数
· 采用五折交叉验证
· dataset与dataloader/数据加载过程
· 初始化网络
· 初始化优化器与学习率函数
3.1 nnUNetTrainer(版本一的训练方法)
··· 损失函数:
self.loss = DC_and_CE_loss({'batch_dice': self.batch_dice, 'smooth': 1e-5, 'do_bg': False}, {})
··· 优化器与学习率函数:
优化器用adam
学习率的调整是用的损失函数的加权平均值来判断是否变动的方法
def initialize_optimizer_and_scheduler(self):
assert self.network is not None, "self.initialize_network must be called first"
self.optimizer = torch.optim.Adam(self.network.parameters(), self.initial_lr, weight_decay=self.weight_decay,
amsgrad=True)
self.lr_scheduler = lr_scheduler.ReduceLROnPlateau(self.optimizer, mode='min', factor=0.2,
patience=self.lr_scheduler_patience,
verbose=True, threshold=1e-3,
threshold_mode="abs")
# 学习率函数设置
self.train_loss_MA_alpha = 0.93 # alpha * old + (1-alpha) * new
def update_train_loss_MA(self):
if self.train_loss_MA is None:
self.train_loss_MA = self.all_tr_losses[-1]
else:
self.train_loss_MA = self.train_loss_MA_alpha * self.train_loss_MA + (1 - self.train_loss_MA_alpha) * \
self.all_tr_losses[-1]
# lr scheduler is updated with moving average val loss. should be more robust
self.lr_scheduler.step(self.train_loss_MA)
3.2 nnUNetTrainerV2(版本二的训练方法)
··· 加强了损失函数(深监督):
还是原来损失,但是添加了一个策略:给每层的损失加一个权重,分辨率越高的权重越大,简单说就是针对中间隐藏层特征透明度不高以及深层网络中浅层以及中间网络难以训练的问题。
################# 封装损失函数进入深度学习(深监督) ############
# 需要知道网络深度
# net_numpool = len(self.plans['pool_op_kernel_sizes'])
# 我们给每个输出一个权重,该权重随着分辨率的降低呈指数递减(除以2)
# 这使得更高的分辨率输出在损失中有更大的权重
weights = np.array([1 / (2 ** i) for i in range(self.net_numpool)])
# 我们不使用最低的2个输出。标准化权重,使其总和为1
mask = np.array([True] + [True if i < self.net_numpool - 1 else False for i in range(1, self.net_numpool)])
weights[~mask] = 0
weights = weights / weights.sum()
self.ds_loss_weights = weights
# 封装损失函数
self.loss = MultipleOutputLoss2(self.loss, self.ds_loss_weights)
··· 重写了优化器与学习率函数
采用SGD与自定义的学习率下降函数
def initialize_optimizer_and_scheduler(self):
assert self.network is not None, "self.initialize_network must be called first"
self.optimizer = torch.optim.SGD(self.network.parameters(), self.initial_lr, weight_decay=self.weight_decay,
momentum=0.99, nesterov=True)
self.lr_scheduler = None
def maybe_update_lr(self, epoch=None):
if epoch is None:
ep = self.epoch + 1
else:
ep = epoch
self.optimizer.param_groups[0]['lr'] = poly_lr(ep, self.max_num_epochs, self.initial_lr, 0.9)
def poly_lr(epoch, max_epochs, initial_lr, exponent=0.9):
return initial_lr * (1 - epoch / max_epochs)**exponent
··· 重写了数据增强参数
3.后面还有DP等等三四个版本,是基于版本二改变的,主要是通过混合精度进行训练增加训练速度
4 前处理
标准化。对除了CT模态之外的其他模态数据(比如MRI和电镜数据),都使用Z-score进行标准化。也就是说,每张图片都减去自身图片的均值并除以标准差。对CT模态的影像来说,对前景(qiguan和病灶)进行基于所有数据的前景信息的标准化。背景就是空气等部分。除此之外,还需要进行Clipping,也就是超过99.5%直方图分布外的像素值都统一设置为99.5%那个阈值的灰度值,低于0.5%直方图分布的像素值都统一设置为0.5%那个阈值的灰度值。
数据扩增。使用旋转、缩放、添加高斯噪声、进行高斯模糊、亮度调节、对比度调节、Gamma调节、上下和左右镜像等常见的Data Augmentation操作。
插值。总体目标是保证从物理意义上来说各个轴上的体素间距是一致的,也就是要做到三维上的各向同性。体素间距越小,分辨率越高。如果某两个轴的分辨率是第三轴的三倍以上,那么这个数据集就被判定为各向异性。对于各向异性数据,主要处理思路是保留高分辨率的两个轴的信息,插值增加低分辨率的那个轴的信息。
5 自适应生成网络结构
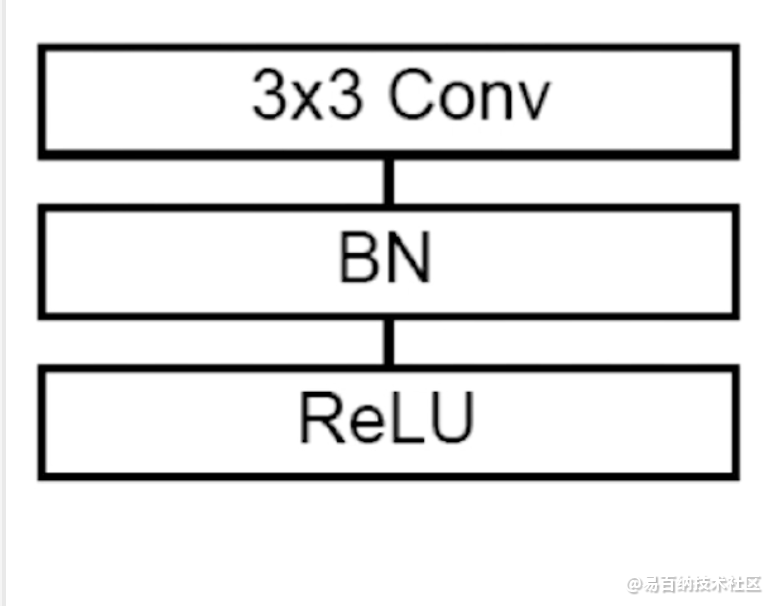
基本的Conv Block的构成为Conv->Instance Norm->Leaky ReLU。每一个encoder和decoder都由2个Conv Block构成。下采样和上采样均使用基础的strided convolutions即可。作者尝试过max pooling和bi\trilinear upsampling的采样方法,发觉与基础方法无实质性差异。当feature map为44(4)时,不再进行下采样。为了尽可能增大感受野,所以patch size的优先级高于batch size。在显存的束缚下,在3D U-Net中,batch size默认为2,以此尽量增加patch size的大小。
6 模型选择
基础的网络模型包括2D U-Net、3D U-Net和级联3D U-Net。对正常分辨率的医学影像,使用2D U-Net + 3D U-Net。当分辨率过高导致模型的感受野不足时,会影响分割性能,这时就需要使用2D U-Net + 级联3D U-Net。当Patch Size在单轴上小于1/2长时,就将3D U-Net替换为级联3D U-Net。本文的实验结果表明,3D U-Net的分割性能总体来说是最好的。
模型选择的总体思路是进行五折交叉验证,选择最好的模型。有些时候单模型不够好,所以还需要进行Ensemble,以尝试出最佳的输出模型。这个步骤与打比赛时的套路挺一致。
7 训练
训练的超参数等相关设置大多是固定的。经验表明,如果不使用这些固定参数,会降低分割的精细程度。Epoch设置为1000,training iteration设置为250。Opimizer选择Stochastic Gradient Descent(initial Learning Rate=0.01,nesterov Momentum=0.99)。Learning Rate选择polyLR(多项式曲线下降)。损失函数选择Dice与交叉熵的均值,经验表明,这个设置可以提升分割精度和训练稳定性。
8 后处理
后处理会使用一个生物医学影像的先验知识:医学影像中常常只有1个主体目标,比如一个人只有1个心脏左心室。在这个先验知识的指导下,后处理会尝试仅保留五折交叉验证后选择的2个模型的重叠的最大连通域,再进行测试。如果测试效果好,就保留此后处理;反之则不保留。
9 推理
Validation集是被五折交叉验证中对应的训练模型所推理。Test集是被五折交叉验证训练得到的所有模型的最佳模型或Ensemble模型所推理。推理时使用的Patch Size等于 训练时使用的Patch Size。为了避免缝合伪影,使用1/2 Patch Size的间隔进行邻域推理。
10 总结
本文通过简单的使用UNet一种结构,一棒子打死了近年来所有的新的网络结构。作者认为网络结构上的改进并没有什么用,应该更多的关注结构以外的部分,比如预处理、训练和推理策略、后处理等部分。
目前为止nnUNet的代码已经被很多地方使用并且证明了它的效果,这不禁引起我们的深思,确实网络结构在这么多年来的所谓的创新。
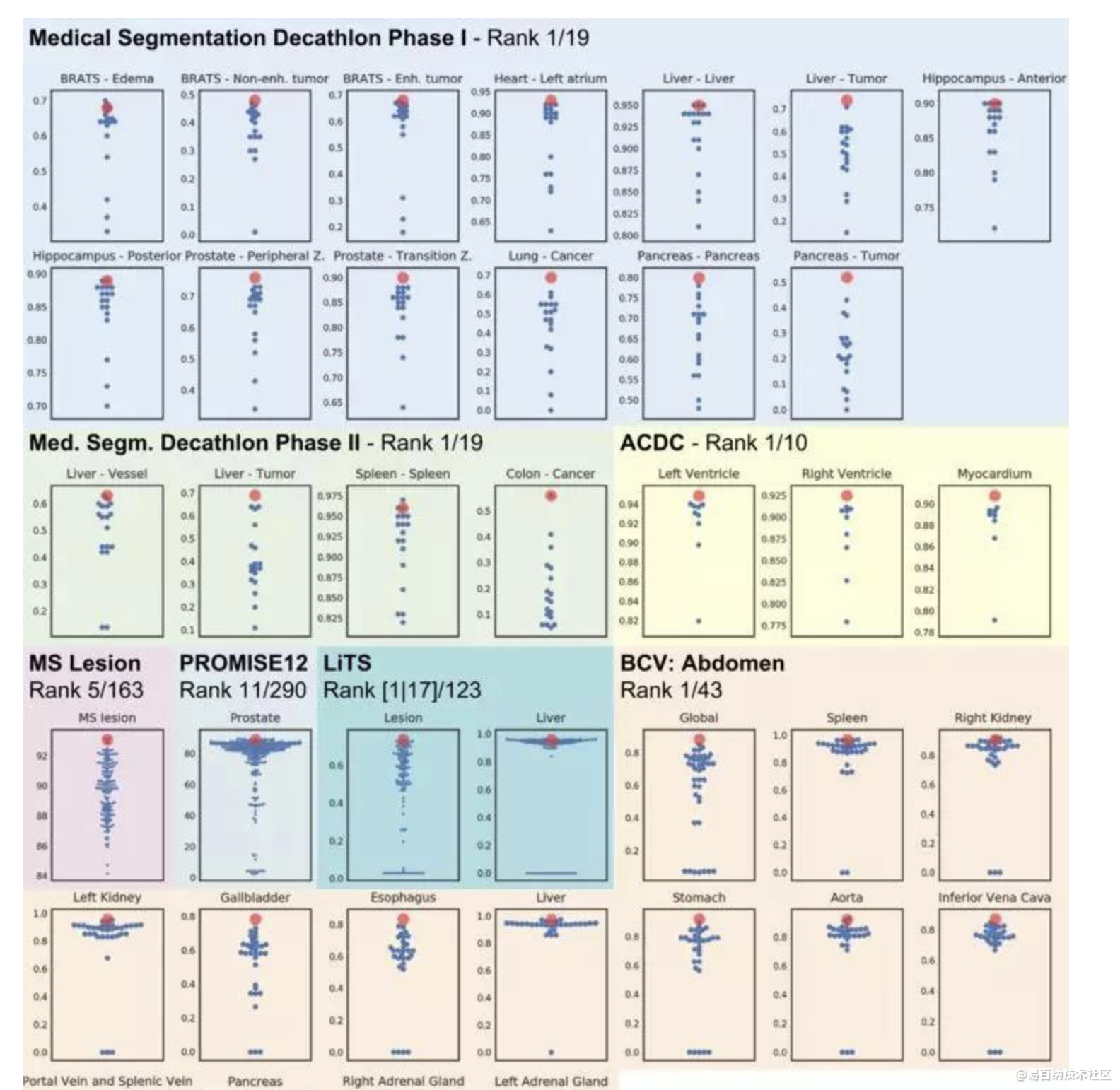
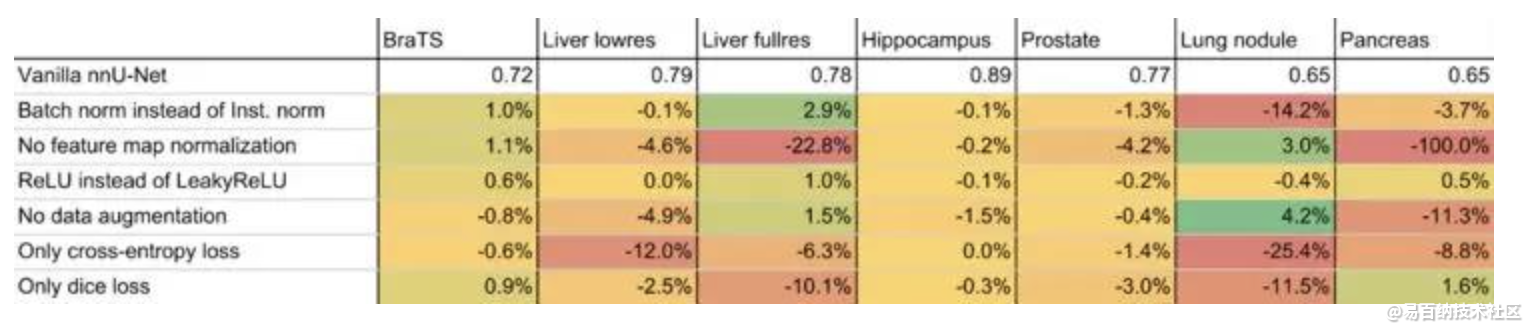
效果真的很好,对于很复杂的医学图像,只要你数据处理工作正常,那么只要你数据处理工作很好,效果远远好于普通的U-Net网络,具体的操作流程,我会继续更新。(等实验做完)。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5576次2021-06-21 11:50:25
-
浏览量:7037次2021-06-07 09:26:53
-
浏览量:18030次2021-06-07 17:47:54
-
浏览量:2645次2023-08-07 12:05:31
-
浏览量:10616次2021-06-09 12:09:57
-
浏览量:2726次2024-01-18 14:56:15
-
浏览量:9520次2021-07-19 17:09:44
-
浏览量:7955次2021-07-19 17:10:27
-
浏览量:14478次2021-07-08 09:43:47
-
浏览量:7315次2021-06-18 17:21:06
-
浏览量:6245次2021-05-17 16:52:58
-
浏览量:33004次2021-07-06 10:18:59
-
浏览量:3025次2020-05-13 18:25:41
-
浏览量:6885次2021-06-27 18:19:55
-
浏览量:17485次2021-05-31 17:01:39
-
浏览量:5251次2021-04-23 14:09:37
-
浏览量:16939次2021-07-29 10:22:10
-
浏览量:8131次2021-07-12 11:03:00
-
浏览量:5492次2021-06-09 14:02:36

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
