

【深度学习】Squeeze-and-Excitation (SE) 模块优势解读
文章目录
1 概念辨析—下采样和上采样
2 Squeeze-and-Excitation (SE)
3 压缩(Squeeze)
4 激励(Excitation)
5 scale操作
6 相乘特征融合
7 SE模块的实现
8 优势- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1 概念辨析—下采样和上采样
概念
上采样(upsampling):又名放大图像、图像插值;
主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上;
上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling);
下采样
概念
下采样(subsampled):又名降采样、缩小图像;
主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图;
其实下采样就是池化;
池化(保留哪些特征,这些特征是最重要的)
池化最直观的作用便是降维,常见的池化有最大池化、平均池化和随机池化;池化层不需要训练参数;
最大池化可以获取局部信息,可以更好保留纹理上的特征;如果不用观察物体在图片中的具体位置,只关心其是否出现,则使用最大池化效果比较好。
平均池化往往能保留整体数据的特征,能凸出背景的信息。
随机池化中元素值大的被选中的概率也大,但不是像最大池化总是取最大值。随机池化一方面最大化地保证了Max值的取值,一方面又确保了不会完全是max值起作用,造成过度失真;除此之外,其可以在一定程度上避免过拟合。
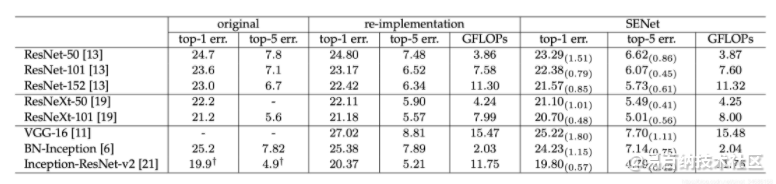
2 Squeeze-and-Excitation (SE)
SENet的全称是Squeeze-and-Excitation Networks,中文可以翻译为压缩和激励网络。主要由两部分组成:
-
Squeeze部分。即为压缩部分,原始feature map的维度为HWC,其中H是高度(Height),W是宽度(width),C是通道数(channel)。Squeeze做的事情是把HWC压缩为11C,相当于把HW压缩成一维了,实际中一般是用global average pooling实现的。HW压缩成一维后,相当于这一维参数获得了之前H*W全局的视野,感受区域更广。
-
Excitation部分。得到Squeeze的11C的表示后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用(激励)到之前的feature map的对应channel上,再进行后续操作。
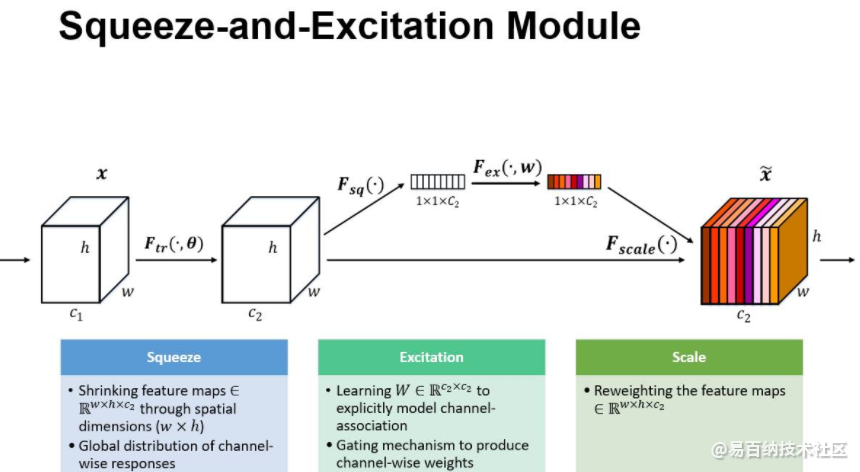
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以Inception和ResNet为例。对于Inception网络,没有残差结构,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。
在我们提出的结构中,Squeeze 和 Excitation 是两个非常关键的操作,所以我们以此来命名。我们的动机是希望显式地建模特征通道之间的相互依赖关系。另外,我们并不打算引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的「特征重标定」策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征
上图是我们提出的 SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来我们通过三个操作来重标定前面得到的特征。
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
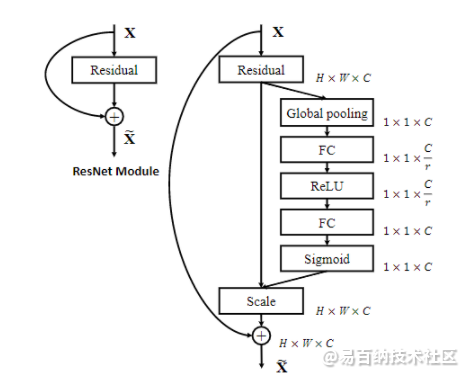
SE实现注意力机制原因
SE可以实现注意力机制最重要的两个地方一个是全连接层,另一个是相乘特征融合
假设输入图像H×W×C,通过global pooling+FC层,拉伸成1×1×C,然后再与原图像相乘,将每个通道赋予权重。在去噪任务中,将每个噪声点赋予权重,自动去除低权重的噪声点,保留高权重噪声点,提高网络运行时间,减少参数计算。这也就是SE模块具有attention机制的原因。
3 压缩(Squeeze)
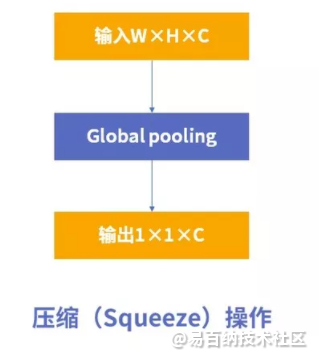
这个操作就是一个全局平均池化(global average pooling)。经过压缩操作后特征图被压缩为1×1×C向量。
4 激励(Excitation)
接下来就是激励(Excitation)操作,如下图所示

由两个全连接层组成,其中SERatio是一个缩放参数,这个参数的目的是为了减少通道个数从而降低计算量。
第一个全连接层有C*SERatio个神经元,输入为1×1×C,输出1×1×C×SERadio。
第二个全连接层有C个神经元,输入为1×1×C×SERadio,输出为1×1×C。
5 scale操作
最后是scale操作,在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
这里我们可以得出SE模块的属性:
参数量 = 2×C×C×SERatio
计算量 = 2×C×C×SERatio
总体来讲SE模块会增加网络的总参数量,总计算量,因为使用的是全连接层计算量相比卷积层并不大,但是参数量会有明显上升,所以MobileNetV3-Large中的总参数量比MobileNetV2多了2M。
6 相乘特征融合
将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘.
7 SE模块的实现
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
对于SE-ResNet模型,只需要将SE模块加入到残差单元(应用在残差学习那一部分)就可以:
class SEBottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=16):
super(SEBottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.se = SELayer(planes * 4, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
8 总结
SE模块主要为了提升模型对channel特征的敏感性,这个模块是轻量级的,而且可以应用在现有的网络结构中,只需要增加较少的计算量就可以带来性能的提升。
另一种实现:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:16457次2021-05-11 15:08:39
-
浏览量:5582次2021-05-08 15:04:36
-
浏览量:2436次2020-06-05 11:16:53
-
浏览量:8006次2021-03-16 15:27:50
-
浏览量:3384次2021-04-13 11:59:54
-
浏览量:7426次2021-06-15 10:28:29
-
浏览量:4543次2021-04-09 16:28:04
-
浏览量:4493次2021-05-18 15:15:50
-
浏览量:5507次2021-06-17 11:39:26
-
浏览量:9629次2021-05-24 15:12:00
-
浏览量:940次2023-02-13 15:29:10
-
浏览量:1350次2023-08-18 10:36:32
-
浏览量:999次2023-08-18 14:08:55
-
浏览量:2759次2018-04-26 15:20:37
-
浏览量:6670次2021-05-31 17:02:05
-
浏览量:4986次2021-04-23 14:09:37
-
2020-08-10 09:21:07
-
浏览量:1058次2023-04-04 11:14:12
-
浏览量:949次2023-06-02 17:41:27

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
