

【深度学习】迁移学习方法的妙用(有效提升准确率)
..```python
文章目录
1 一个普通的神经网络
1.1 数据预处理
1.2 分割训练集和测试集合
1.3 搭建模型
2 使用ImageNet数据集
2.1 搭建模型
2.2 训练后结果
3 快速迁移学习
3.1 搭建特征提取模型并导出特征
3.2 训练全联接分类器
4 模型融合
# 1 一个普通的神经网络

接下来的内容,我们以 gaggle 上的一个比赛一猫狗大战(htps: / www. Kaggle.com/c/dogs-vs-cats-redux-kernels-edition)的数据集为例,来谈谈如何基于迁移学习实现高准确率的猫狗图像分类。该比赛提供了 25000 张图作为训练集,猫狗各占一半,测试集 12500 张,没有标定是猫还是狗。
```python
➜ 猫狗大战 ls train | head
cat.0.jpg
cat.1.jpg
cat.10.jpg
cat.100.jpg
cat.1000.jpg
cat.10000.jpg
cat.10001.jpg
cat.10002.jpg
cat.10003.jpg
cat.10004.jpg
➜ 猫狗大战 ls test | head
1.jpg
10.jpg
100.jpg
1000.jpg
10000.jpg
10001.jpg
10002.jpg
10003.jpg
10004.jpg
10005.jpg
1.1 数据预处理
由于我们的数据集的文件名是以type.num.jpg这样的方式命名的,比如cat.0.jpg,但是使用 Keras 的 ImageDataGenerator 需要将不同种类的图片分在不同的文件夹中,因此我们需要对数据集进行预处理。这里我们采取的思路是创建符号链接(symbol link),这样的好处是不用复制一遍图片,占用不必要的空间。
我们可以从下面看到文件夹的结构,train2里面有两个文件夹,分别是猫和狗,每个文件夹里是12500张图。
├── test [12500 images]
├── test.zip
├── test2
│ └── test -> ../test/
├── train [25000 images]
├── train.zip
└── train2
├── cat [12500 images]
└── dog [12500 images]
1.2 分割训练集和测试集合
这部分工作不再赘述。
1.3 搭建模型
inputs = Input((width, width, 3))
x = inputs
for i, layer_num in enumerate([2, 2, 3, 3, 3]):
for j in range(layer_num):
x = Conv2D(32*2**i, 3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(2)(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs, x)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])h = model.fit(X_train, y_train, batch_size=32, epochs=50, validation_data=(X_valid, y_valid))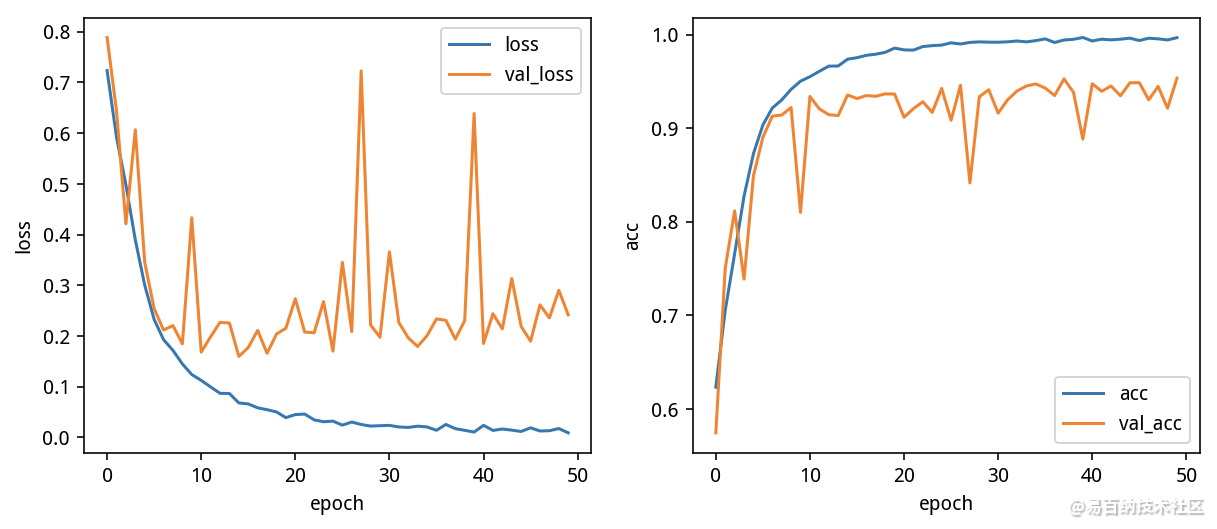
2 使用ImageNet数据集
迁移学习是一个很有意义的技术,它能够直接利用一个身经百战的模型脑子里的知识来学习新的数据集,达到与之前相当、甚至比之前的模型还好的表现。
在没有迁移学习以前,人们训练一个模型通常要非常久的时间。例如,如果有 4 块 NVIDIA Titan Black 显卡,想在 Imagenet 数据集上训练一个 VGG16 模型,那么进行完整的训练需要 2~3 周的时间。这是非常浪费时间、浪费电费的做法,完全可以利用别人已经训练好的 GG16 模型的权值,然后利用其中的卷积核权重。
在 Imagenet 数据集上预训练过的权重,靠近输入的那几层卷积层一般都是识别各种边缘信息或者颜色信息,除非是与 Imagenet 差异非常大的数据集。
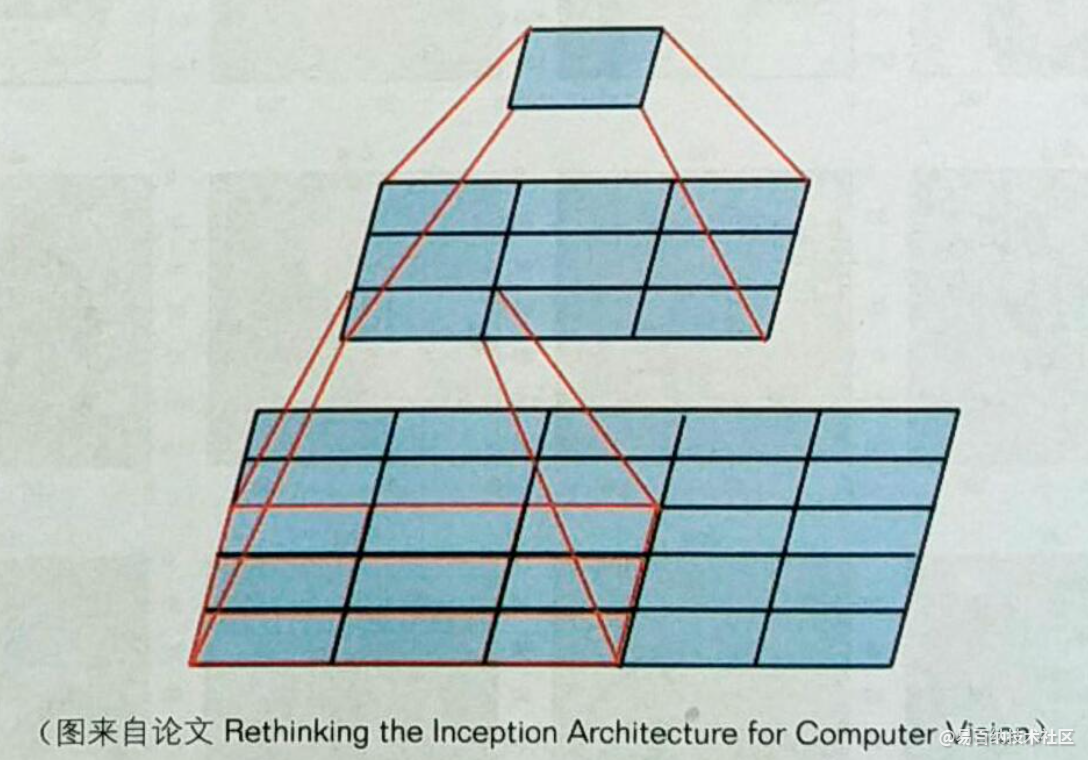
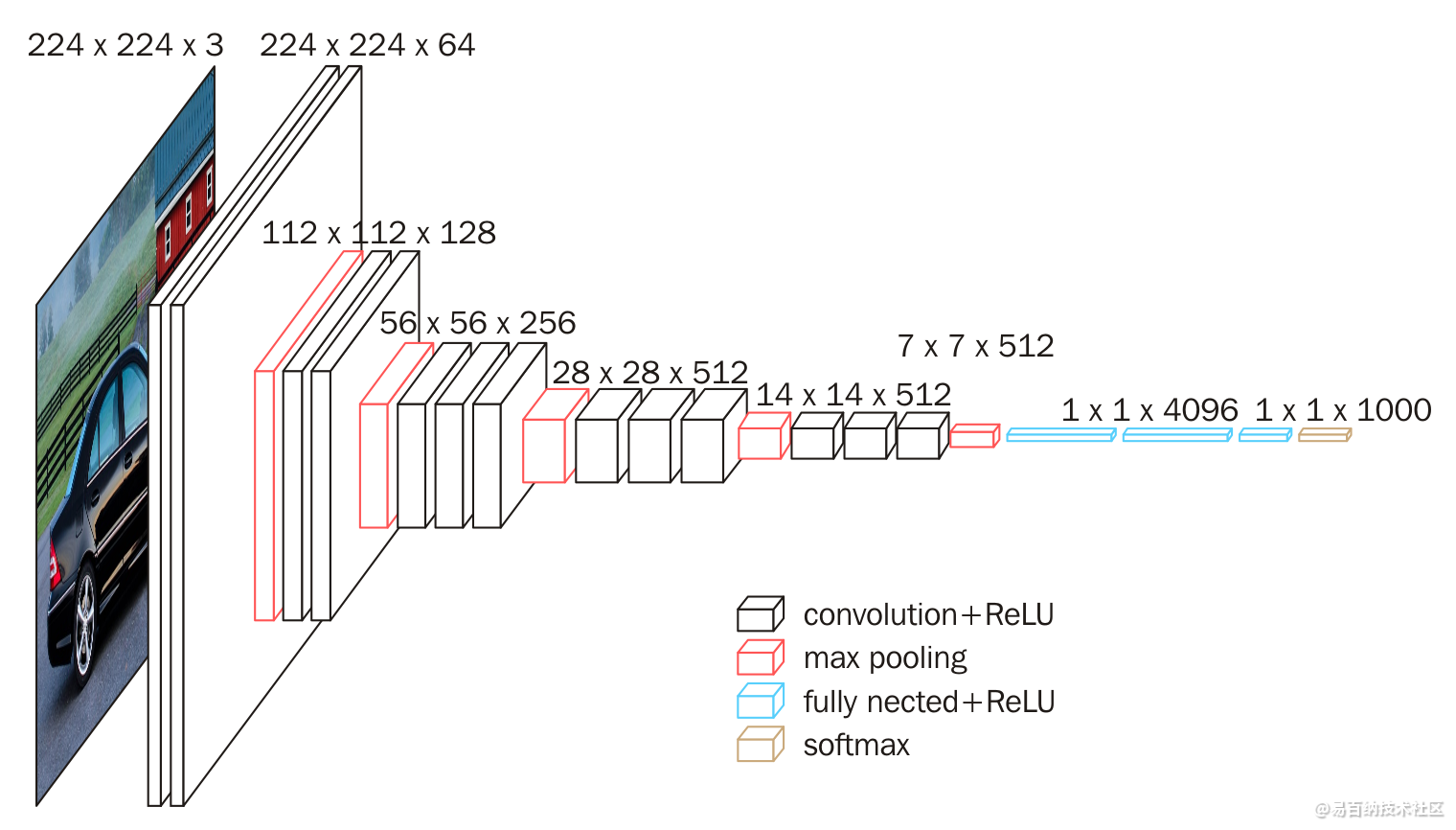
VGG16 是一个很经典的模型,它的特征提取部分只使用了 3×3 的卷积核,以及 2×2 的池化层。在它之前很多人都认为巻积核要比较大才能识别更大的区域,不过根据计算可以知道,两个卷积核大小为 3×3 的卷积层可以有效覆盖 5×5 的区域,同时还可以减少计算量,以及增加非线性能力,这也是 VGG 系列模型的核心思想,就是减小卷积核,加深网络,如图 9-3 所示。
VGG 的名字来自于 Visual Geometry Group,这是牛津大学的一个实验室。他们发的论文标题也很直接:Very Deep Convolutional Networks for Large- Scale Visual Recognition,意思是用于大规模视觉识别的非常深的卷积神经网络。
2.1 搭建模型
cnn_model = VGG16(include_top=False, input_shape=(width, width, 3), weights='imagenet')
for layer in cnn_model.layers:
layer.trainable = False
inputs = Input((width, width, 3))
x = inputs
x = Lambda(preprocess_input, name='preprocessing')(x)
x = cnn_model(x)
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs, x)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])2.2 训练后结果
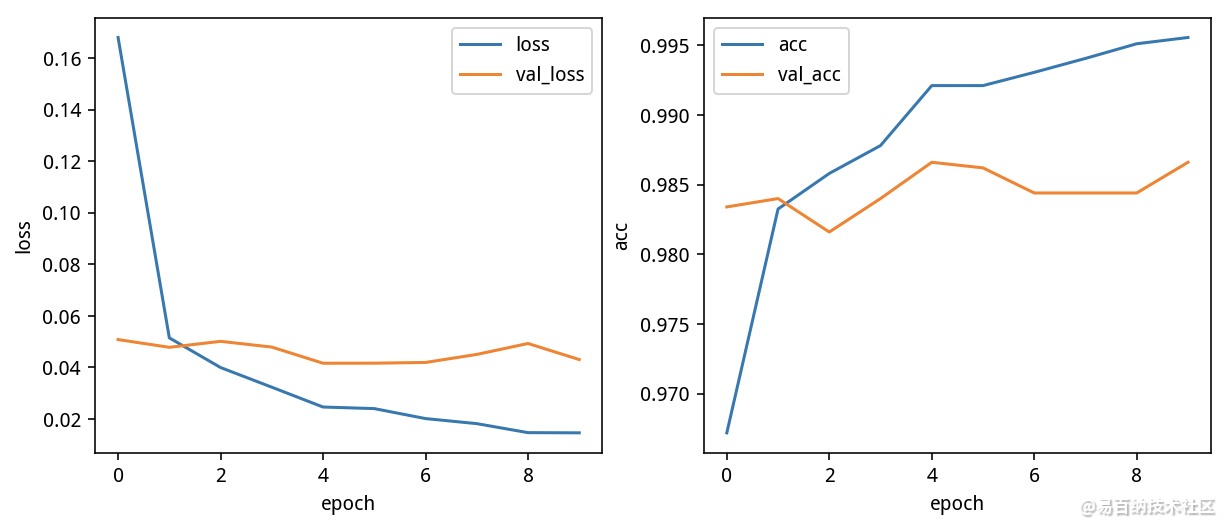
3 快速迁移学习
我们知道,迁移学习是不需要修改前面几十层卷积层的,
但是在训练的时候依然会浪费很多时间在 cnn model 上,这是不必要的。
为了节省时间,可以先用 cnn model 预测得到特征,再合并特征,训练分类器进行分类即可。
这种基于原模型直接得到预测的特征,并基于原模型预测特征做进一步分析的方法称为快速迁移学习。
快速迁移学习的步骤如下:
载入数据集
搭建预训练模型(cnn model
导出数据集的特征
搭建简单全连接分类器模型(model
训练模型3.1 搭建特征提取模型并导出特征
def get_features(MODEL, data=X):
cnn_model = MODEL(include_top=False, input_shape=(width, width, 3), weights='imagenet')
inputs = Input((width, width, 3))
x = inputs
x = Lambda(preprocess_input, name='preprocessing')(x)
x = cnn_model(x)
x = GlobalAveragePooling2D()(x)
cnn_model = Model(inputs, x)
features = cnn_model.predict(data, batch_size=64, verbose=1)
return features3.2 训练全联接分类器
正常训练流程即可。
4 模型融合
融合模型的方法很简单,首先将特征提取出来,然后拼接在一起,构建一个全连接分类器训练就可以了
模型融合能够提高成绩的理论依据是,有些模型辨认猫准确率高,有些模型辨认狗准确率高,给这些模型不同的权重,让它们能够取长补短,综合各自的优势。为了能够更好地融合模型可以提取特征进行融合,这样会有更好的效果,弱特征的权重会越学越小,强特征会越学越大,最后得到效果非常好的模型。
inputs = Input(features.shape[1:])
x = inputs
x = Dropout(0.5)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs, x)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
h = model.fit(features, y, batch_size=128, epochs=10, validation_split=0.2)
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:948次2023-08-03 10:52:42
-
浏览量:8314次2020-12-08 14:09:20
-
浏览量:1330次2023-03-13 10:01:59
-
浏览量:2133次2019-01-22 19:37:49
-
浏览量:7817次2021-06-15 10:28:29
-
浏览量:1061次2023-07-05 10:15:58
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:254次2023-07-25 11:30:01
-
浏览量:1134次2023-12-14 16:38:19
-
浏览量:758次2023-06-21 14:07:39
-
浏览量:1170次2023-02-16 10:41:40
-
浏览量:2464次2018-11-17 15:56:06
-
浏览量:7955次2021-07-19 17:10:27
-
浏览量:16734次2021-07-16 12:56:10
-
浏览量:2570次2019-01-31 11:00:16
-
浏览量:1358次2023-03-02 13:55:57
-
浏览量:171次2023-08-23 09:24:30
-
浏览量:2970次2018-01-27 13:19:46
-
浏览量:10767次2021-06-15 10:30:15

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
