

【深度学习】利用神网框架分割病理切片中的癌组织(胃)
文章目录
1 数据描述
2 思路
3 准备数据
4 构建模型
5 模型优化
6 程序执行
7 观察结果1 数据描述
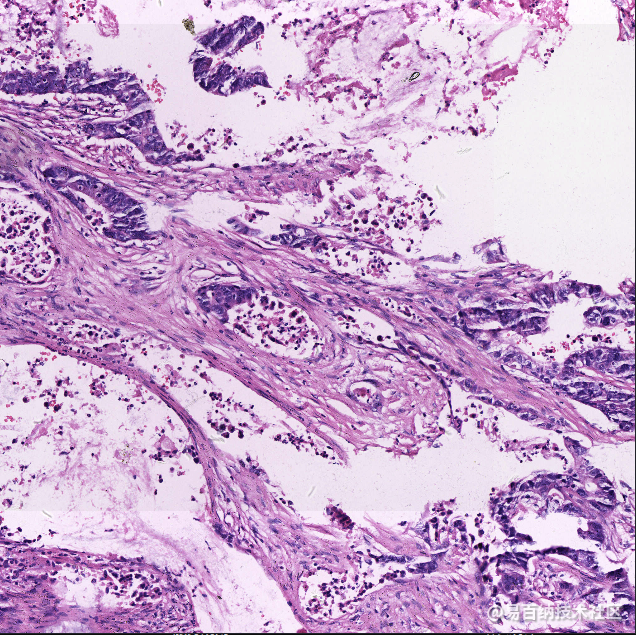
初赛选取癌病理切片,为常规 HE 染色,放大倍数 20, 图片大小为 2048×2048 像素,比赛数据为整体切片的部分区域,tif 格式。比赛不允许使用外部数据。初赛选取 100 个病人案例(部分为癌症、部分为非癌症),共计 1000 张病理切片图片,训练集数量 700 张,测试集数量 300 张。
病理专家将数据标记(双盲评估+验证)为有无癌症,并用线条画出肿瘤区域轮廓。原始数据以及标注数据内容如下:

2 思路
需要实现像素级别的图像分割,所以我们考虑使用全卷积神经网络(FCN),用这种架构:
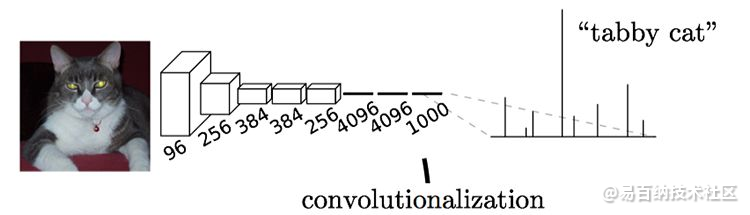
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
栗子:下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。
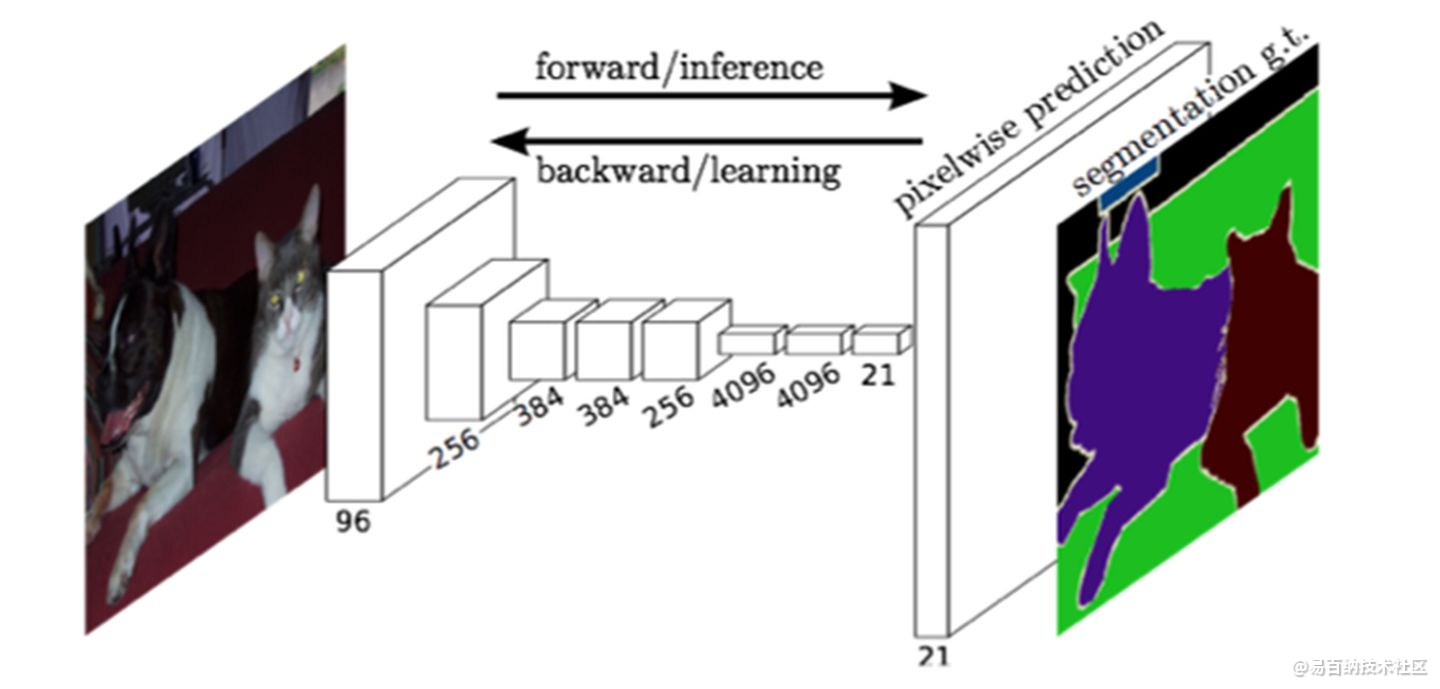
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图:
简单的来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。
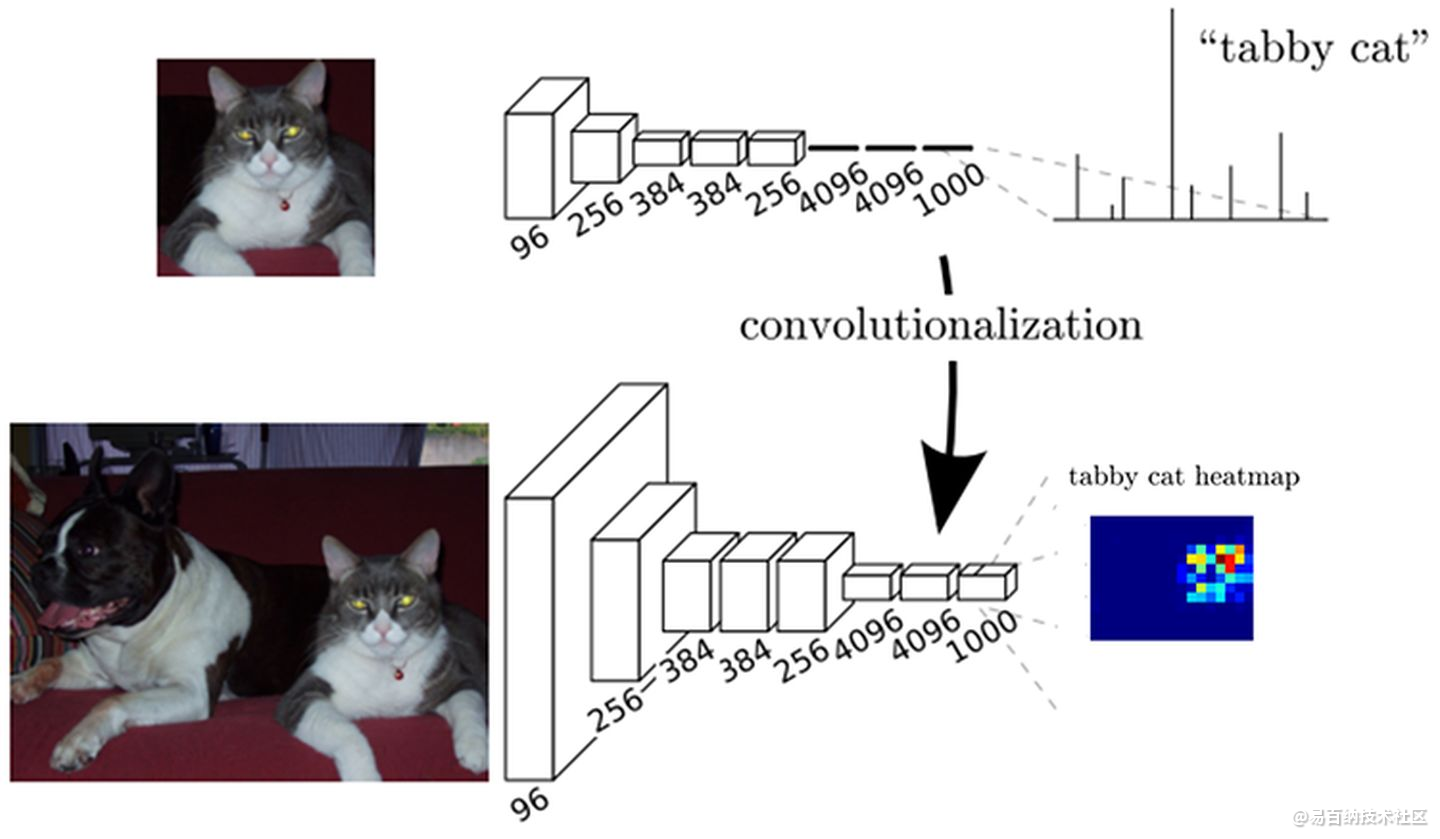
其实,CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。下图CNN分类网络的示意图:
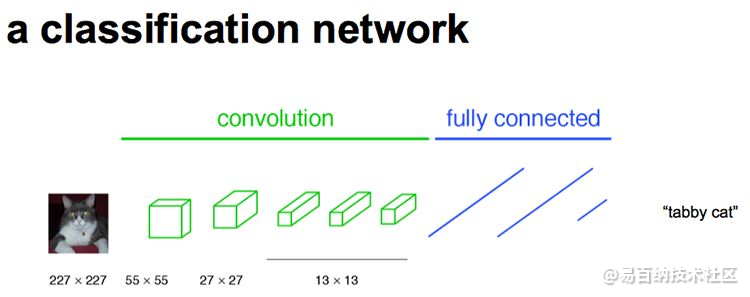
这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
而全卷积网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
如下图所示,FCN将传统CNN中的全连接层转化成卷积层,对应CNN网络FCN把最后三层全连接层转换成为三层卷积层。在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。FCN将这3层表示为卷积层,卷积核的大小 (通道数,宽,高) 分别为 (4096,1,1)、(4096,1,1)、(1000,1,1)。看上去数字上并没有什么差别,但是卷积跟全连接是不一样的概念和计算过程,使用的是之前CNN已经训练好的权值和偏置,但是不一样的在于权值和偏置是有自己的范围,属于自己的一个卷积核。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
upsampling
相较于使用被转化前的原始卷积神经网络对所有36个位置进行迭代计算,使用转化后的卷积神经网络进行一次前向传播计算要高效得多,因为36次计算都在共享计算资源。这一技巧在实践中经常使用,一次来获得更好的结果。比如,通常将一张图像尺寸变得更大,然后使用变换后的卷积神经网络来对空间上很多不同位置进行评价得到分类评分,然后在求这些分值的平均值。
最后,如果我们想用步长小于32的浮窗怎么办?用多次的向前传播就可以解决。比如我们想用步长为16的浮窗。那么先使用原图在转化后的卷积网络执行向前传播,然后分别沿宽度,沿高度,最后同时沿宽度和高度,把原始图片分别平移16个像素,然后把这些平移之后的图分别带入卷积网络。
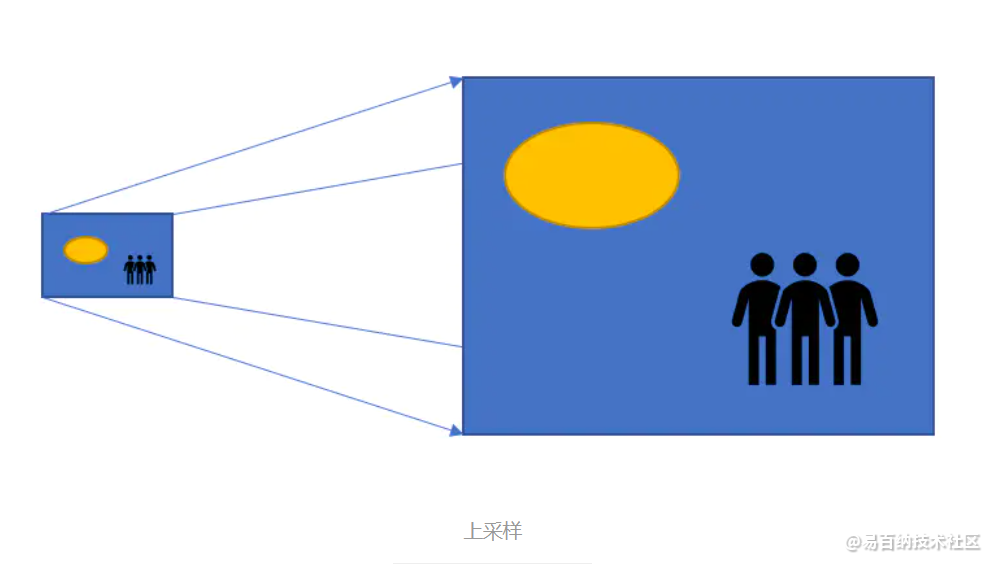
而上采样达到的效果,则和下采样相反。上采样可以扩大输入图像的尺寸,将一个小分辨率的图像扩展成一个高分辨率的图像。在YOLOv4模型中,上采样被加入卷积网络中,作为中间层使用,扩展特征图尺寸,便于张量拼接。
反卷积是一种特殊的正向卷积**,先按照一定的比例通过补0来扩大输入图像的尺寸(padding),接着转置过滤器,再进行正向卷积。**
Deconvolution(反卷积)在CNN中常用于表示一种反向卷积 ,但它并不是一个符合严格数学定义的反卷积操作。与UPspooling不同,使用反卷积来对图像进行上采样是可以习得的。通常用来对卷积层的结果进行上采样,使其回到原始图片的分辨率。
根据我查到的资料来看,deconv是up sampling的一种,除此之外还有双线性插值法、up pooling法,但是双线性插值因其简单有效占用资源有少,而且不需要学习参数,一直是图像分割领域使用比较多的上采样方法,FCN这篇图像分割的开山之作就是使用双线性插值法去进行up sampling。

在这种架构基础之上,我们有以下想法:
图形分辨率很高,我们可以考虑将一张图片拆分为多张小图片,进行模型训练。
由于只有700张图片,并且是 RGB 图片,根据我们在第八章猫狗大战中的经验,以及最后提到的皮肤癌判断项目的分析架构,这里考虑引入迁移学习。
样本数量有限,可能会有过拟合现象发生。考虑在反卷积层中,引入 l2 正则化。
样本数量有限,考虑进行数据增强。
3 准备数据
准备数据中,我们遇到的第一个问题,就是如何处理 svg 格式的标注数据。首先,svg 的标注,看起来是一个空心的区域,实际模型训练过程中,需要将其转换成实心区域。其次,svg 是一种矢量图,并不是以矩阵的形式存储的,需要将其转换为矩阵。
4 构建模型
模型的构建阶段,主要分为两个部分。一是首先导入用 ImageNet 预训练的 vgg16 模型。这里如果直接使用官方地址的ckpt格式的模型的话,需要首先将其转换成 .pb 格式的模型,并将 ckpt 中的参数值写入 .pb 文件。
这样做是因为直接加载.pb 格式的模型加载起来相对容易,ckpt格式只有参数,没有图的定义,需要在代码中定义模型结构,或者导入其他 .pb 文件。而 .pb 格式可以只存储图的模型,也可以进一步通过 tensorflow的 freeze_graph 功能,将参数写入 .pb 文件。我们这里为了省事,直接下载转换完成后的 vgg16 .pb 文件。
def load_vgg(sess, vgg_path):
"""
载入 VGG16 预训练模型,返回我们基于 VGG16 训练全卷积神经网络(FCN)所必须的中间变量。
:param sess: TensorFlow Session
:param vgg_path: vgg16 模型文件的下载路径。模型使用pb格式存储,
下载地址:https://s3-us-west-1.amazonaws.com/udacity-selfdrivingcar/vgg.zip
:return image_input, keep_prob, layer3_out, layer4_out, layer7_out
返回我们基于 VGG16 训练 全卷积神经网络(FCN) 所必须的中间变量
"""
vgg_tag = 'vgg16'
vgg_input_tensor_name = 'image_input:0'
vgg_keep_prob_tensor_name = 'keep_prob:0'
vgg_layer3_out_tensor_name = 'layer3_out:0'
vgg_layer4_out_tensor_name = 'layer4_out:0'
vgg_layer7_out_tensor_name = 'layer7_out:0'
tf.saved_model.loader.load(sess, [vgg_tag], vgg_path)
graph = tf.get_default_graph()
input_image = graph.get_tensor_by_name(vgg_input_tensor_name)
keep_prob = graph.get_tensor_by_name(vgg_keep_prob_tensor_name)
vgg_layer3_out = graph.get_tensor_by_name(vgg_layer3_out_tensor_name)
vgg_layer4_out = graph.get_tensor_by_name(vgg_layer4_out_tensor_name)
vgg_layer7_out = graph.get_tensor_by_name(vgg_layer7_out_tensor_name)
return input_image, keep_prob, vgg_layer3_out, vgg_layer4_out, vgg_layer7_out第二部分是在 vgg16 模型的基础上,构建全卷积神经网络。这里我们根据 [fully convolutional networks for semantic segmentation]这篇文章给定的网络结构,直接构建模型。这里面需要注意的是,首先参数需要合理的初始化,我们在第四章内容介绍卷积层时,提到卷积层的初始化过程中,要注意随着层数的增多,随机初始化引入的方差,会随着连续的乘法运算,累计增加或者减少,进而影响整个梯度的计算。因此我们这里同样需要注意参数的合理初始化,这里引入了 xavier_initializer()。其次我们可以将卷积核通过tf.slice 抽出来作为灰度图像,通过 tf.summary.image() 留下记录,这样我们就可以在 tensorboard 中看见卷积核的结果。深度学习虽然由于不容易解释,被人当作“玄学”,但实际上并非无法解释,通过对卷积核进行可视化分析,会给我们提供很多有用信息。
with tf.name_scope("32xUpsampled") as scope:
conv7_1x1 = tf.layers.conv2d(vgg_layer7_out, num_classes, 1,
padding='same', name="32x_1x1_conv",
kernel_regularizer=tf.contrib.layers.l2_regularizer(g_l2),
kernel_initializer=tf.contrib.layers.xavier_initializer())
conv7_2x = tf.layers.conv2d_transpose(conv7_1x1, num_classes, 4,
strides=2, padding='same', name="32x_conv_trans_upsample",
kernel_regularizer=tf.contrib.layers.l2_regularizer(g_l2),
kernel_initializer=tf.contrib.layers.xavier_initializer())
with tf.name_scope("16xUpsampled") as scope:
conv4_1x1 = tf.layers.conv2d(vgg_layer4_out, num_classes, 1,
padding='same', name="16x_1x1_conv",
kernel_regularizer=tf.contrib.layers.l2_regularizer(g_l2),
kernel_initializer=tf.contrib.layers.xavier_initializer())
conv_merge1 = tf.add(conv4_1x1, conv7_2x, name="16x_combined_with_skip")
conv4_2x = tf.layers.conv2d_transpose(conv_merge1, num_classes, 4,
strides=2, padding='same', name="16x_conv_trans_upsample",
kernel_regularizer=tf.contrib.layers.l2_regularizer(g_l2),
kernel_initializer=tf.contrib.layers.xavier_initializer())
with tf.name_scope("8xUpsampled") as scope:
conv3_1x1 = tf.layers.conv2d(vgg_layer3_out, num_classes, 1,
padding='same', name="8x_1x1_conv",
kernel_regularizer=tf.contrib.layers.l2_regularizer(g_l2),
kernel_initializer=tf.contrib.layers.xavier_initializer())
conv_merge2 = tf.add(conv3_1x1, conv4_2x, name="8x_combined_with_skip")
conv3_8x = tf.layers.conv2d_transpose(conv_merge2, num_classes, 16,
strides=8, padding='same', name="8x_conv_trans_upsample",
kernel_regularizer=tf.contrib.layers.l2_regularizer(g_l2),
kernel_initializer=tf.contrib.layers.xavier_initializer())
conv_image_0 = tf.slice(conv3_8x, [0,0,0,0], [-1,-1,-1,1])
tf.summary.image("conv3_8x_results_0", conv_image_0)
return conv3_8x5 模型优化
def optimize(nn_last_layer, correct_label, learning_rate, num_classes, batch_size, split_idx):
"""
定义模型的优化目标(损失函数),设置优化器
:param nn_last_layer: 全卷积神经网络模型(FCN)的输出结果
:param correct_label: 病理切片对应的、准确的癌症区域标注
:param learning_rate: 初始学习率大小
:param num_classes: 需要分类的种类数目。这里是癌症区域/非癌症区域的二分类
:return pred_label: 病理切片对应的、模型预测的癌症区域标注
:return training_op: 优化器
:return cross_entropy_loss 交叉熵损失函数
:return f1 比赛规定的评价指标 f1 值
:return learning_rate2 随训练次数逐步衰减后的学习率的大小
"""
pred_label = tf.reshape(nn_last_layer, [-1, num_classes], name="predicted_label")
true_label = tf.reshape(correct_label, [-1, num_classes], name="true_label")
with tf.name_scope("f1_score"):
argmax_p = tf.argmax(pred_label, 1)
argmax_y = tf.argmax(true_label, 1)
TP = tf.count_nonzero( argmax_p * argmax_y, dtype=tf.float32)
TN = tf.count_nonzero((argmax_p-1)*(argmax_y-1), dtype=tf.float32)
FP = tf.count_nonzero( argmax_p *(argmax_y-1), dtype=tf.float32)
FN = tf.count_nonzero((argmax_p-1)* argmax_y, dtype=tf.float32)
precision = TP / (TP+FP)
recall = TP / (TP+FN)
f1 = 2 * precision * recall / (precision + recall)
with tf.name_scope("cross_entropy_loss"):
entropy_val = tf.nn.softmax_cross_entropy_with_logits(labels=true_label, logits=pred_label)
cross_entropy_loss = tf.reduce_sum(entropy_val)
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = cross_entropy_loss + sum(reg_losses)
with tf.name_scope("train"):
batch = tf.Variable(0, tf.float32)
learning_rate2 = tf.train.exponential_decay(
learning_rate, # Base learning rate.
batch * batch_size, # Current index into the dataset.
split_idx, # Decay step.
0.95, # Decay rate.
staircase=True)
# 不使用 learning_rate decay 策略的话,直接用 learning_rate
#optimizer = tf.train.AdamOptimizer(learning_rate)
optimizer = tf.train.AdamOptimizer(learning_rate2)
training_op = optimizer.minimize(loss, global_step=batch)
return pred_label, training_op, cross_entropy_loss, f1, learning_rate26 程序执行
将学习率、正则化参数以及批次数据大小,作为argv环境参数,这样我们就可以通过linux脚本,来自动寻找最优参数组合:
展示脚本的内容:
head runfcn.sh
结果
python runfcn.py 1e-3 1e-2 2
python runfcn.py 1e-4 1e-2 2
python runfcn.py 1e-5 1e-2 2
python runfcn.py 1e-3 1e-2 4
python runfcn.py 1e-4 1e-2 4
python runfcn.py 1e-5 1e-2 4
python runfcn.py 1e-3 1e-2 8
python runfcn.py 1e-4 1e-2 8
python runfcn.py 1e-5 1e-2 8
python runfcn.py 1e-3 1e-6 2
里面有我们希望的各种参数组合。我们可以通过直接执行脚本,训练模型,继而将不同参数训练的模型分别保存下来:
7 观察结果

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1584次2023-09-27 09:50:04
-
浏览量:5251次2021-04-23 14:09:37
-
浏览量:7654次2021-04-29 12:46:50
-
浏览量:8008次2021-07-19 17:08:40
-
浏览量:4941次2021-04-20 15:50:27
-
浏览量:9520次2021-07-19 17:09:44
-
浏览量:11694次2021-06-25 15:00:55
-
浏览量:14733次2021-07-05 09:47:30
-
浏览量:7037次2021-06-07 09:26:53
-
浏览量:7955次2021-07-19 17:10:27
-
浏览量:1922次2023-02-14 14:48:11
-
浏览量:15051次2021-05-04 20:16:03
-
浏览量:7322次2021-05-04 20:17:10
-
浏览量:6245次2021-05-17 16:52:58
-
浏览量:5535次2021-07-12 11:02:32
-
浏览量:4769次2021-04-23 14:09:15
-
浏览量:157次2023-08-30 15:28:02
-
2023-01-12 11:47:40
-
浏览量:1035次2023-07-20 17:45:54

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
