

【深度学习】如何更好的Fit一个深度神经网络框架下的模型
文章目录
1 随机梯度下降
1.1 什么是梯度下降
1.2 随机梯度算法
2 Momentum
3 自适应学习率算法
3.1 AdaGrad
3.2 Adam
3.3 Adam配置参数1 随机梯度下降
1.1 什么是梯度下降
我们先从一张图来直观解释这个过程。
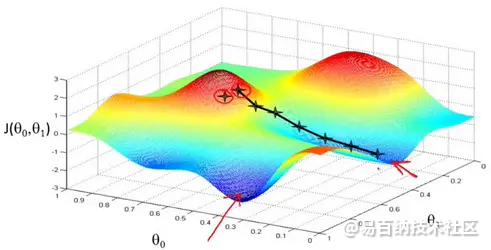
如上图假设这样一个场景:一个人被困在山上,需要从山上下来,但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找方向,然后朝着山的高度下降的地方走。
但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点。如图所示,黑线标注的路线所指的方向并不是真正的地方。
那么问题来了?
既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走?
先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因。如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点。
总结起来就一句话:随机选择一个方向,然后每次迈步都选择最陡的方向,直到这个方向上能达到的最低点。
其实梯度下降的过程即可类比与上述描述的下山的过程。
我们可以这样理解:首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向。
所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。
2.那什么是梯度?求取梯度有什么用?
还是从例子入手:
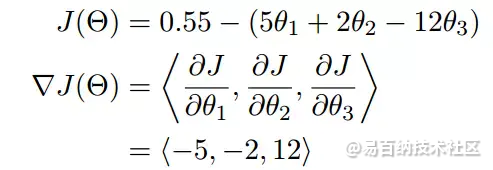
上图就是一个求梯度的实例,由这个实例我们可以看到,梯度就是分别对每个变量进行微分,然后用逗号分割开,梯度是用<>包括起来,说明梯度其实一个向量。
在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率;在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向。
这也就告诉我们为什么需要求梯度。我们需要到达山底,就需要在每一步观测到此时最陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向。所以我们只要沿着梯度的方向一直走,就能走到局部上的一个最低点。
3.我们使用梯度下降来做什么?有什么优缺点?
a. 在机器学习算法中,有时候需要对原始的模型构建损失函数,然后通过优化算法对损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。而在求解机器学习参数的优化算法中,使用较多的就是基于梯度下降的优化算法(Gradient Descent, GD)。
b.优缺点
优点:效率。在梯度下降法的求解过程中,只需求解损失函数的一阶导数,计算的代价比较小,可以在很多大规模数据集上应用。
缺点:求解的是局部最优值,即由于方向选择的问题,得到的结果不一定是全局最优步长选择,过小使得函数收敛速度慢,过大又容易找不到最优解。
1.2 随机梯度算法
概念
随机梯度下降(SGD)是一种简单但非常有效的方法,多用用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习。并且SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题。
SGD既可以用于分类计算,也可以用于回归计算。
分类和回归的实现可参考:
(https://blog.csdn.net/qq_38150441/article/details/80533891)
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(划个重点:每次迭代使用一组样本。)
为什么叫随机梯度下降算法呢?这里的随机是指每次迭代过程中,样本都要被随机打乱,这个也很容易理解,打乱是有效减小样本之间造成的参数更新抵消问题。
分类
随机梯度下降算法通常还有三种不同的应用方式,它们分别是SGD、Batch-SGD、Mini-Batch SGD
a.SGD是最基本的随机梯度下降,它是指每次参数更新只使用一个样本,这样可能导致更新较慢;
b.Batch-SGD是批随机梯度下降,它是指每次参数更新使用所有样本,即把所有样本都代入计算一遍,然后取它们的参数更新均值,来对参数进行一次性更新,这种更新方式较为粗糙;
c.Mini-Batch-SGD是小批量随机梯度下降,它是指每次参数更新使用一小批样本,这批样本的数量通常可以采取trial-and-error的方法来确定,这种方法被证明可以有效加快训练速度
运用
训练模型的目的是使得目标函数达到极小值。对于一个深度神经网络,它的参数数目比较庞大,因此目标函数通常是一个包含很多参量的非线性函数。对于这个非线性函数,我们采用的是随机梯度下降算法来对参数进行更新。具体步骤如下:
(1)对网络参数进行初始化,一般情况下,权重初始化为均值是0,方差为0.01的高斯分布随机值,而偏置统一初始化为0;
(2)将参数代入网络计算前馈输出值,从而可以根据已有的目标标签得出目标函数值;
(3)根据目标函数值以及各参数与目标函数所构成的树结构,运用后向传播算法计算出每个参数的梯度;
(4)设置学习率大小(随着迭代的步骤增多,学习率通常要逐渐减小,这样可以有效避免训练中出现误差震荡情况),进行参数更新,最一般的更新方式是 新参数=旧参数-学习率×梯度;
(5)重复进行第2~4步,直到网络收敛为止。
2 Momentum
使用梯度下降法,每次都会朝着目标函数下降最快的方向,这也称为最速下降法。这种更新方法看似非常快,实际上存在一些问题。
梯度下降法的问题
考虑一个二维输入,$[x_1, x_2]$,输出的损失函数 $L: R^2 \rightarrow R$,下面是这个函数的等高线

可以想象成一个很扁的漏斗,这样在竖直方向上,梯度就非常大,在水平方向上,梯度就相对较小,所以我们在设置学习率的时候就不能设置太大,为了防止竖直方向上参数更新太过了,这样一个较小的学习率又导致了水平方向上参数在更新的时候太过于缓慢,所以就导致最终收敛起来非常慢。
动量法
相当于每次在进行参数更新的时候,都会将之前的速度考虑进来,每个参数在各方向上的移动幅度不仅取决于当前的梯度,还取决于过去各个梯度在各个方向上是否一致,如果一个梯度一直沿着当前方向进行更新,那么每次更新的幅度就越来越大,如果一个梯度在一个方向上不断变化,那么其更新幅度就会被衰减,这样我们就可以使用一个较大的学习率,使得收敛更快,同时梯度比较大的方向就会因为动量的关系每次更新的幅度减少,如下图

如果我们把 $\gamma$ 定为 0.9,那么更新幅度的峰值就是原本梯度乘学习率的 10 倍。
本质上说,动量法就仿佛我们从高坡上推一个球,小球在向下滚动的过程中积累了动量,在途中也会变得越来越快,最后会达到一个峰值,对应于我们的算法中就是,动量项会沿着梯度指向方向相同的方向不断增大,对于梯度方向改变的方向逐渐减小,得到了更快的收敛速度以及更小的震荡。
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) # 加动量
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
if idx % 30 == 0: # 30 步记录一次
losses.append(loss.data[0])
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
epoch: 0, Train Loss: 0.369134
epoch: 1, Train Loss: 0.176699
epoch: 2, Train Loss: 0.125531
epoch: 3, Train Loss: 0.100507
epoch: 4, Train Loss: 0.083820
使用时间: 63.79601 s
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='momentum: 0.9')
plt.legend(loc='best')
<matplotlib.legend.Legend at 0x112d3e978>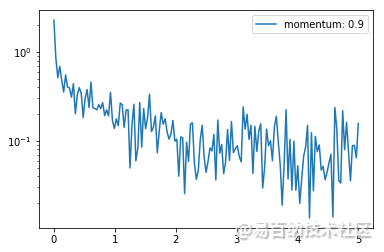
我们可以对比一下不加动量的随机梯度下降法
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2) # 不加动量
# 开始训练
losses1 = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data[0]
if idx % 30 == 0: # 30 步记录一次
losses1.append(loss.data[0])
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
epoch: 0, Train Loss: 0.735494
epoch: 1, Train Loss: 0.364616
epoch: 2, Train Loss: 0.318786
epoch: 3, Train Loss: 0.290835
epoch: 4, Train Loss: 0.268683
使用时间: 50.32162 s
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='momentum: 0.9')
plt.semilogy(x_axis, losses1, label='no momentum')
plt.legend(loc='best')
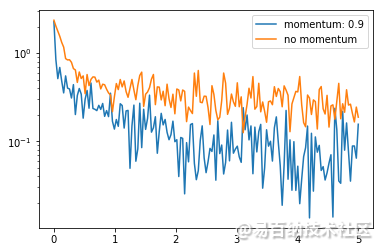
可以看到加完动量之后的 loss 下降的程度更低了,可以将动量理解为一种惯性作用,所以每次更新的幅度都会比不加动量的情况更多

这里的总体趋势是从后往前,但实际上左右之间的梯度是远高于前后之间的,所以随机梯度下降过程中,模型会过多地被左右方向的局部梯度带着走
3 自适应学习率算法
使用统一的全局学习率
可能出现的问题:对于某些参数,通过算法已经优化到了极小值附近,但是有的参数仍然有着很大的梯度。如果学习率太小,则梯度很大的参数会有一个很慢的收敛速度;如果学习率太大,则已经优化得差不多的参数可能会出现不稳定的情况。
方案:
1.对每个参与训练的参数设置不同的学习率,在整个学习过程中通过一些算法自动适应这些参数的学习率。
Delta-ba-delta:如果损失与某一指定参数的偏导的符号相同,那么学习率应该增加;如果损失与该参数的偏导的符号不同,那么学习率应该减小。该算法只能用于全批量训练数据的优化。
基于小批量的训练数据的性能更好的自适应学习率算法:
3.1 AdaGrad
能独立地适应所有模型参数的学习率,当参数损失偏导值比较大时,有一个较大的学习率;当参数的损失偏导值较小时,有一个较小的学习率。

表现:在某些深度学习模型上能获得很不错的效果,但并不能适用于所有模型。因为算法在训练开始时就对梯度平方进行累积,在一些实验中,容易导致学习率过早和过量地减小。
3.2 Adam
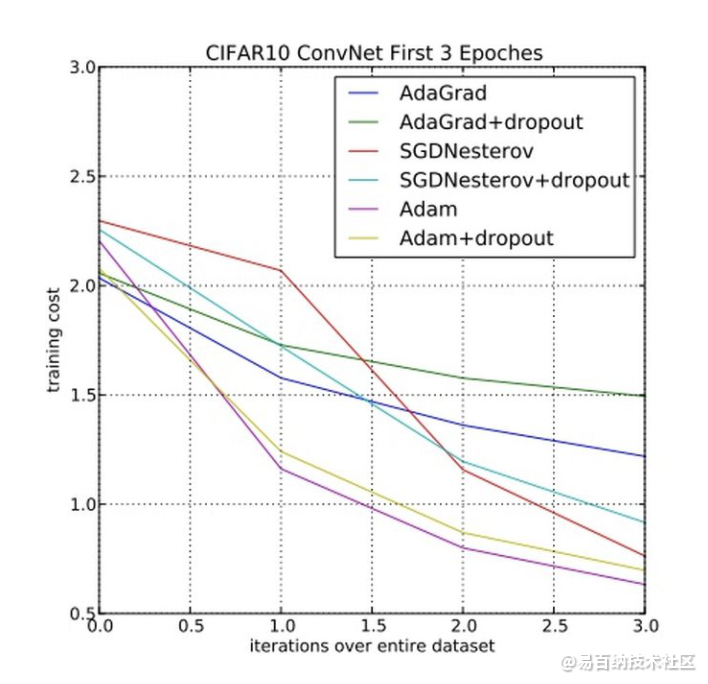
在深度学习模型中用来代替随机梯度下降的优化算法
结合了AdaGrad和RMSProp算法最优性能 调参相对简单 默认参数就可处理大部分的问题。
3.3 Adam配置参数
alpha也被称为学习速率或步长。权重比例被校正(例如001)。更大的值(例如0.3)在速率校正之前会加快初始学习速度。较小的值(例如1.0e-5)在培训期间降低学习速度
beta1。第一次估计的指数衰减率(如9)。
beta2。第二次估计的指数衰次减率(例如999)。在稀疏梯度问题(例如NLP和计算机视觉问题)上,这个值应该接近1.0。
epsilon是一个非常小的数字,可以防止任何在实施中被0划分(例如,10e-8)。
最后,这里推荐一些比较受欢迎的使用默认参数的深度学习库:
TensorFlow: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08.
Keras: lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0.
Blocks: learning_rate=0.002, beta1=0.9, beta2=0.999, epsilon=1e-08, decay_factor=1.
Lasagne: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
Caffe: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
MxNet: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
Torch: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:9598次2021-05-13 12:53:50
-
浏览量:4390次2021-05-14 09:47:57
-
浏览量:5251次2021-04-23 14:09:37
-
浏览量:4941次2021-04-20 15:50:27
-
浏览量:7043次2021-05-31 17:02:05
-
浏览量:9030次2021-05-28 16:59:43
-
浏览量:5595次2021-08-13 15:39:02
-
浏览量:4333次2018-02-14 10:30:11
-
浏览量:5143次2021-04-21 17:05:28
-
浏览量:5985次2021-05-28 16:59:25
-
2023-01-12 11:47:40
-
浏览量:10767次2021-06-15 10:30:15
-
浏览量:5128次2021-04-21 17:05:56
-
浏览量:881次2023-08-28 09:56:42
-
浏览量:4581次2021-04-19 14:54:23
-
浏览量:5466次2021-04-12 16:28:50
-
浏览量:18030次2021-06-07 17:47:54
-
浏览量:1143次2024-02-01 14:20:47
-
浏览量:7701次2021-07-26 11:30:25

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
