

深入浅出机器学习的概念特征及算法(进阶篇)
深入浅出机器学习的概念特征及算法(进阶篇)
前言 紧接上篇《深入浅出机器学习的概念特征及算法》,这一篇将深入展开机器学习的五大特征和十大算法,机器学习是一个数据驱动的过程,数据科学也是一个广泛而令人兴奋的领域,从聚类、关联、到探索标准化,大数据的感性与互联网变革的风暴正在完美的诠释着科学精准与预知预判的洞察意义,希望接下来的内容对你有所帮助。
一、机器学习的5大基本特征
从现实意义上来说,机器学习 (machine learning)是一种程序或系统,用于根据输入数据构建(训练)预测模型。这种系统会利用学到的模型根据从分布(训练该模型时使用的同一分布)中提取的新数据(以前从未见过的数据)进行实用的预测。机器学习还指与这些程序或系统相关的研究领域。
机器学习是人工智能的核心,包含传统机器学习的研究和大数据环境下的机器学习研究,以及未来更多领域的定向化的分析和探索,同时机器学习涉及领域极广,涵盖科学门类极多,概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
特征是相关性和波动性的主要阀值,特征选择是从原始特征中选择出一些最有效特征以降低数据集维度、提高法性能的方法。
我们知道模型的性能会随着使用特征数量的增加而增加。但是,当超过峰值时,模型性能将会下降。这就是为什么我们只需要选择能够有效预测的特征的原因。
特征选择页称为特征子集选择,类似于降维技术,其目的是减少特征的数量,但是从根本上说,它们是不同的。区别在于要素选择会选择要保留或从数据集中删除的要素,而降维会创建数据的投影,从而产生全新的输入要素。
特征选择有很多方法,在本文中我将介绍 Scikit-Learn 中 5 个方法,因为它们是最简单但却非常有用的,让我们开始吧。
1、方差阈值特征选择
具有较高方差的特征表示该特征内的值变化大,较低的方差意味着要素内的值相似,而零方差意味着您具有相同值的要素。
方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征,使用方法我们举例说明:
import pandas as pd
import seaborn as sns
mpg = sns.load_dataset('mpg').select_dtypes('number')
mpg.head()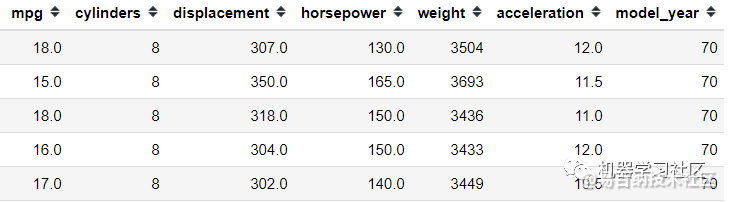
 对于此示例,我仅出于简化目的使用数字特征。在使用方差阈值特征选择之前,我们需要对所有这些数字特征进行转换,因为方差受数字刻度的影响。
对于此示例,我仅出于简化目的使用数字特征。在使用方差阈值特征选择之前,我们需要对所有这些数字特征进行转换,因为方差受数字刻度的影响。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
mpg = pd.DataFrame(scaler.fit_transform(mpg), columns = mpg.columns)
mpg.head()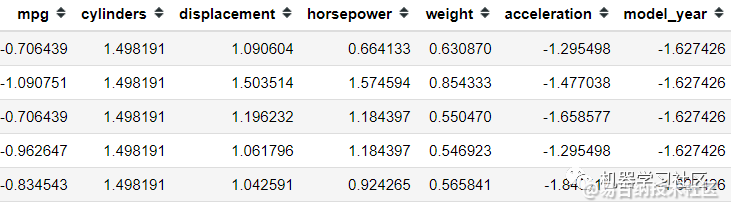
所有特征都在同一比例上,让我们尝试仅使用方差阈值方法选择我们想要的特征。假设我的方差限制为一个方差。
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(1)
selector.fit(mpg)
mpg.columns[selector.get_support()]方差阈值是一种无监督学习的特征选择方法。如果我们希望出于监督学习的目的而选择功能怎么办?那就是我们接下来要讨论的。
2、SelectKBest特征特征
单变量特征选择是一种基于单变量统计检验的方法,例如:chi2,Pearson等等。
SelectKBest 的前提是将未经验证的统计测试与基于 X 和 y 之间的统计结果选择 K 数的特征相结合。
mpg = sns.load_dataset('mpg')
mpg = mpg.select_dtypes('number').dropna()
#Divide the features into Independent and Dependent Variable
X = mpg.drop('mpg' , axis =1)
y = mpg['mpg']由于单变量特征选择方法旨在进行监督学习,因此我们将特征分为独立变量和因变量。接下来,我们将使用SelectKBest,假设我只想要最重要的两个特征。
from sklearn.feature_selection import SelectKBest, mutual_info_regression
#Select top 2 features based on mutual info regression
selector = SelectKBest(mutual_info_regression, k =2)
selector.fit(X, y)
X.columns[selector.get_support()]3、递归特征消除(RFE)
递归特征消除或RFE是一种特征选择方法,利用机器学习模型通过在递归训练后消除最不重要的特征来选择特征。
根据Scikit-Learn,RFE是一种通过递归考虑越来越少的特征集来选择特征的方法。
- 首先对估计器进行初始特征集训练,然后通过coef_attribute或feature_importances_attribute获得每个特征的重要性。
- 然后从当前特征中删除最不重要的特征。在修剪后的数据集上递归地重复该过程,直到最终达到所需的要选择的特征数量。
在此示例中,我想使用泰坦尼克号数据集进行分类问题,在那里我想预测谁将生存下来。
#Load the dataset and only selecting the numerical features for example purposes
titanic = sns.load_dataset('titanic')[['survived', 'pclass', 'age', 'parch', 'sibsp', 'fare']].dropna()
X = titanic.drop('survived', axis = 1)
y = titanic['survived']我想看看哪些特征最能帮助我预测谁可以幸免于泰坦尼克号事件。让我们使用LogisticRegression模型获得最佳特征。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# #Selecting the Best important features according to Logistic Regression
rfe_selector = RFE(estimator=LogisticRegression(),n_features_to_select = 2, step = 1)
rfe_selector.fit(X, y)
X.columns[rfe_selector.get_support()]默认情况下,为RFE选择的特征数是全部特征的中位数,步长是1.当然,你可以根据自己的经验进行更改。
4、SelectFromModel 特征选择
Scikit-Learn 的 SelectFromModel 用于选择特征的机器学习模型估计,它基于重要性属性阈值。默认情况下,阈值是平均值。
让我们使用一个数据集示例来更好地理解这一概念。我将使用之前的数据。
from sklearn.feature_selection import SelectFromModel
sfm_selector = SelectFromModel(estimator=LogisticRegression())
sfm_selector.fit(X, y)
X.columns[sfm_selector.get_support()]与RFE一样,你可以使用任何机器学习模型来选择功能,只要可以调用它来估计特征重要性即可。你可以使用随机森林模或XGBoost进行尝试。
5、顺序特征选择(SFS)
顺序特征选择是一种贪婪算法,用于根据交叉验证得分和估计量来向前或向后查找最佳特征,它是 Scikit-Learn 版本0.24中的新增功能。方法如下:
- SFS-Forward 通过从零个特征开始进行功能选择,并找到了一个针对单个特征训练机器学习模型时可以最大化交叉验证得分的特征。
- 一旦选择了第一个功能,便会通过向所选功能添加新功能来重复该过程。当我们发现达到所需数量的功能时,该过程将停止。
让我们举一个例子说明。
from sklearn.feature_selection import SequentialFeatureSelector
sfs_selector = SequentialFeatureSelector(estimator=LogisticRegression(), n_features_to_select = 3, cv =10, direction ='backward')
sfs_selector.fit(X, y)
X.columns[sfs_selector.get_support()]特征选择是机器学习模型中的一个重要方面,对于模型无用的特征,不仅影响模型的训练速度,同时也会影响模型的效果。
二、机器学习的10大经典算法
机器学习是一个复杂而系统的尝试和模拟过程,算法是机器学习的核心和灵魂所在,下面我们就从最经典的10个机器学习算法系统的了解本质:
1、线性回归
线性回归可能是统计学和机器学习中最知名和最易理解的算法之一。
由于预测建模主要关注最小化模型的误差,或者以可解释性为代价来做出最准确的预测。 我们会从许多不同领域借用、重用和盗用算法,其中涉及一些统计学知识。
线性回归用一个等式表示,通过找到输入变量的特定权重(B),来描述输入变量(x)与输出变量(y)之间的线性关系。
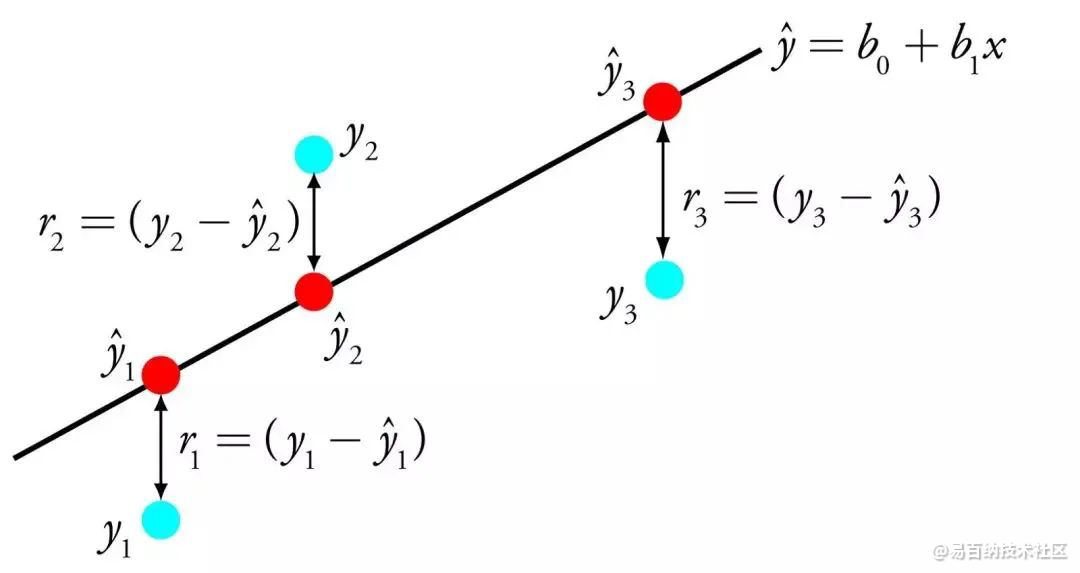
Linear Regression
举例:y = B0 + B1 * x
给定输入x,我们将预测y,线性回归学习算法的目标是找到系数B0和B1的值。
可以使用不同的技术从数据中学习线性回归模型,例如用于普通最小二乘和梯度下降优化的线性代数解。
线性回归已经存在了200多年,并且已经进行了广泛的研究。 如果可能的话,使用这种技术时的一些经验法则是去除非常相似(相关)的变量并从数据中移除噪声。 这是一种快速简单的技术和良好的第一种算法。
2、逻辑回归
逻辑回归是机器学习从统计领域借鉴的另一种技术。 这是二分类问题的专用方法(两个类值的问题)。
逻辑回归与线性回归类似,这是因为两者的目标都是找出每个输入变量的权重值。 与线性回归不同的是,输出的预测值得使用称为逻辑函数的非线性函数进行变换。
逻辑函数看起来像一个大S,并能将任何值转换为0到1的范围内。这很有用,因为我们可以将相应规则应用于逻辑函数的输出上,把值分类为0和1(例如,如果IF小于0.5,那么 输出1)并预测类别值。

Logistic Regression
由于模型的特有学习方式,通过逻辑回归所做的预测也可以用于计算属于类0或类1的概率。这对于需要给出许多基本原理的问题十分有用。
与线性回归一样,当你移除与输出变量无关的属性以及彼此非常相似(相关)的属性时,逻辑回归确实会更好。 这是一个快速学习和有效处理二元分类问题的模型。
3、线性判别分析
传统的逻辑回归仅限于二分类问题。 如果你有两个以上的类,那么线性判别分析算法(Linear Discriminant Analysis,简称LDA)是首选的线性分类技术。
LDA的表示非常简单。 它由你的数据的统计属性组成,根据每个类别进行计算。 对于单个输入变量,这包括:
- 每类的平均值。
- 跨所有类别计算的方差。
Linear Discriminant Analysis
LDA通过计算每个类的判别值并对具有最大值的类进行预测来进行。该技术假定数据具有高斯分布(钟形曲线),因此最好先手动从数据中移除异常值。这是分类预测建模问题中的一种简单而强大的方法。
4、分类和回归树
决策树是机器学习的一种重要算法。
决策树模型可用二叉树表示。对,就是来自算法和数据结构的二叉树,没什么特别。 每个节点代表单个输入变量(x)和该变量上的左右孩子(假定变量是数字)。
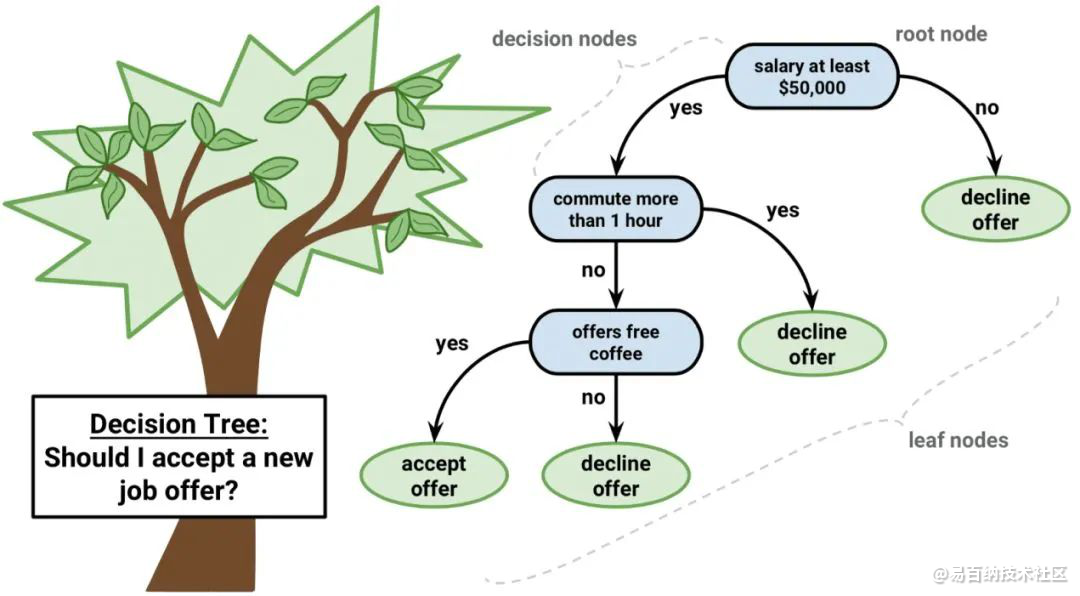
Decision Tree
树的叶节点包含用于进行预测的输出变量(y)。 预测是通过遍历树进行的,当达到某一叶节点时停止,并输出该叶节点的类值。
决策树学习速度快,预测速度快。 对于许多问题也经常预测准确,并且你不需要为数据做任何特殊准备。
5、朴素贝叶斯
朴素贝叶斯是一种简单但极为强大的预测建模算法。
该模型由两种类型的概率组成,可以直接从你的训练数据中计算出来:1)每个类别的概率; 2)给定的每个x值的类别的条件概率。 一旦计算出来,概率模型就可以用于使用贝叶斯定理对新数据进行预测。 当你的数据是数值时,通常假设高斯分布(钟形曲线),以便可以轻松估计这些概率。
Bayes Theorem
朴素贝叶斯被称为朴素的原因,在于它假设每个输入变量是独立的。 这是一个强硬的假设,对于真实数据来说是不切实际的,但该技术对于大范围内的复杂问题仍非常有效。
6、K近邻
KNN算法非常简单而且非常有效。KNN的模型用整个训练数据集表示。 是不是特简单?
通过搜索整个训练集内K个最相似的实例(邻居),并对这些K个实例的输出变量进行汇总,来预测新的数据点。 对于回归问题,新的点可能是平均输出变量,对于分类问题,新的点可能是众数类别值。
成功的诀窍在于如何确定数据实例之间的相似性。如果你的属性都是相同的比例,最简单的方法就是使用欧几里德距离,它可以根据每个输入变量之间的差直接计算。

K-Nearest Neighbors
KNN可能需要大量的内存或空间来存储所有的数据,但只有在需要预测时才会执行计算(或学习)。 你还可以随时更新和管理你的训练集,以保持预测的准确性。
距离或紧密度的概念可能会在高维环境(大量输入变量)下崩溃,这会对算法造成负面影响。这类事件被称为维度诅咒。它也暗示了你应该只使用那些与预测输出变量最相关的输入变量。
7、学习矢量量化
K-近邻的缺点是你需要维持整个训练数据集。 学习矢量量化算法(或简称LVQ)是一种人工神经网络算法,允许你挂起任意个训练实例并准确学习他们。
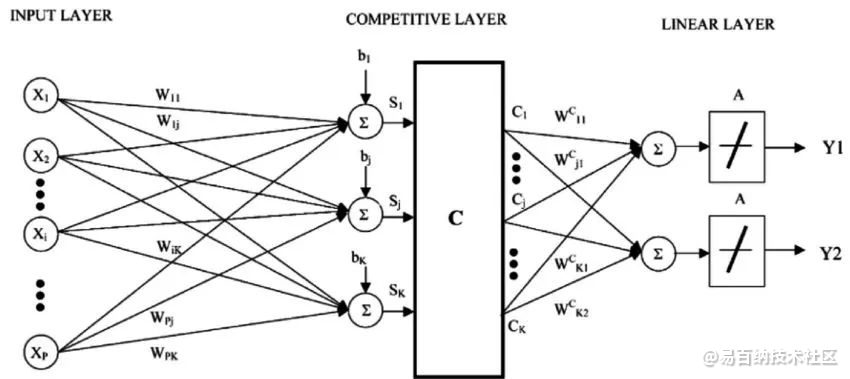
Learning Vector Quantization
LVQ用codebook向量的集合表示。开始时随机选择向量,然后多次迭代,适应训练数据集。 在学习之后,codebook向量可以像K-近邻那样用来预测。 通过计算每个codebook向量与新数据实例之间的距离来找到最相似的邻居(最佳匹配),然后返回最佳匹配单元的类别值或在回归情况下的实际值作为预测。 如果你把数据限制在相同范围(如0到1之间),则可以获得最佳结果。
如果你发现KNN在您的数据集上给出了很好的结果,请尝试使用LVQ来减少存储整个训练数据集的内存要求。
8、支持向量机
支持向量机也许是最受欢迎和讨论的机器学习算法之一。
超平面是分割输入变量空间的线。 在SVM中,会选出一个超平面以将输入变量空间中的点按其类别(0类或1类)进行分离。在二维空间中可以将其视为一条线,所有的输入点都可以被这条线完全分开。SVM学习算法就是要找到能让超平面对类别有最佳分离的系数。
Support Vector Machine
超平面和最近的数据点之间的距离被称为边界,有最大边界的超平面是最佳之选。同时,只有这些离得近的数据点才和超平面的定义和分类器的构造有关,这些点被称为支持向量,他们支持或定义超平面。在具体实践中,我们会用到优化算法来找到能最大化边界的系数值。
SVM可能是最强大的即用分类器之一,在你的数据集上值得一试。
9、bagging和随机森林
随机森林是最流行和最强大的机器学习算法之一。 它是一种被称为Bootstrap Aggregation或Bagging的集成机器学习算法。
bootstrap是一种强大的统计方法,用于从数据样本中估计某一数量,例如平均值。 它会抽取大量样本数据,计算平均值,然后平均所有平均值,以便更准确地估算真实平均值。
在bagging中用到了相同的方法,但最常用到的是决策树,而不是估计整个统计模型。它会训练数据进行多重抽样,然后为每个数据样本构建模型。当你需要对新数据进行预测时,每个模型都会进行预测,并对预测结果进行平均,以更好地估计真实的输出值。
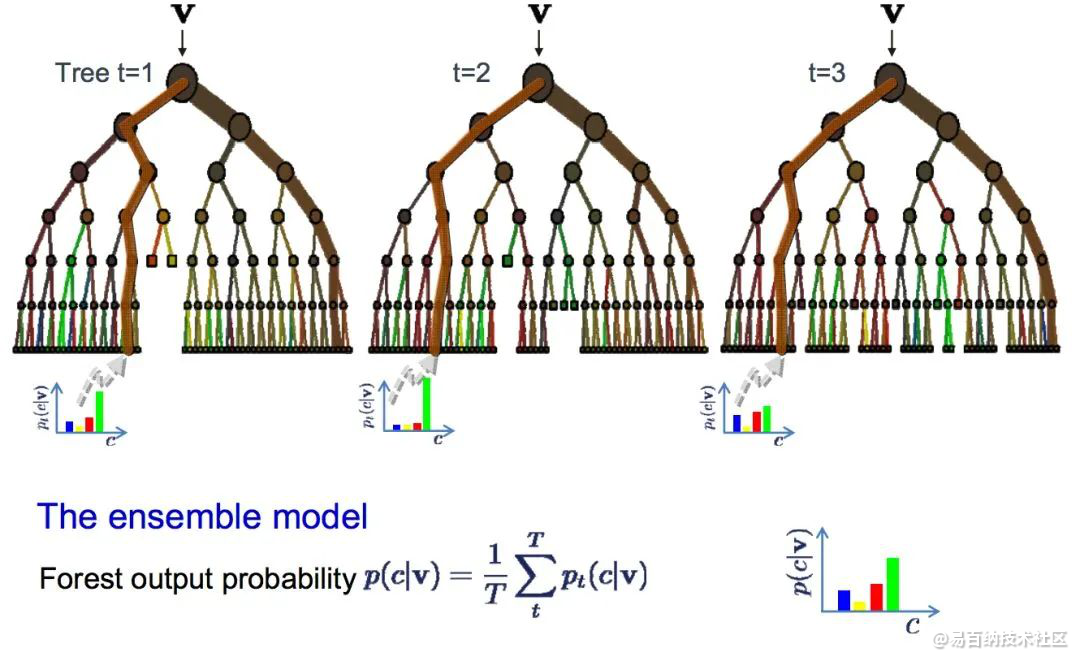
Random Forest
随机森林是对决策树的一种调整,相对于选择最佳分割点,随机森林通过引入随机性来实现次优分割。
因此,为每个数据样本创建的模型之间的差异性会更大,但就自身意义来说依然准确无误。结合预测结果可以更好地估计正确的潜在输出值。
如果你使用高方差算法(如决策树)获得良好结果,那么加上这个算法后效果会更好。
10、Boosting和AdaBoost
Boosting是一种从一些弱分类器中创建一个强分类器的集成技术。 它先由训练数据构建一个模型,然后创建第二个模型来尝试纠正第一个模型的错误。 不断添加模型,直到训练集完美预测或已经添加到数量上限。
AdaBoost是为二分类开发的第一个真正成功的Boosting算法,同时也是理解Boosting的最佳起点。 目前基于AdaBoost而构建的算法中最著名的就是随机梯度boosting。
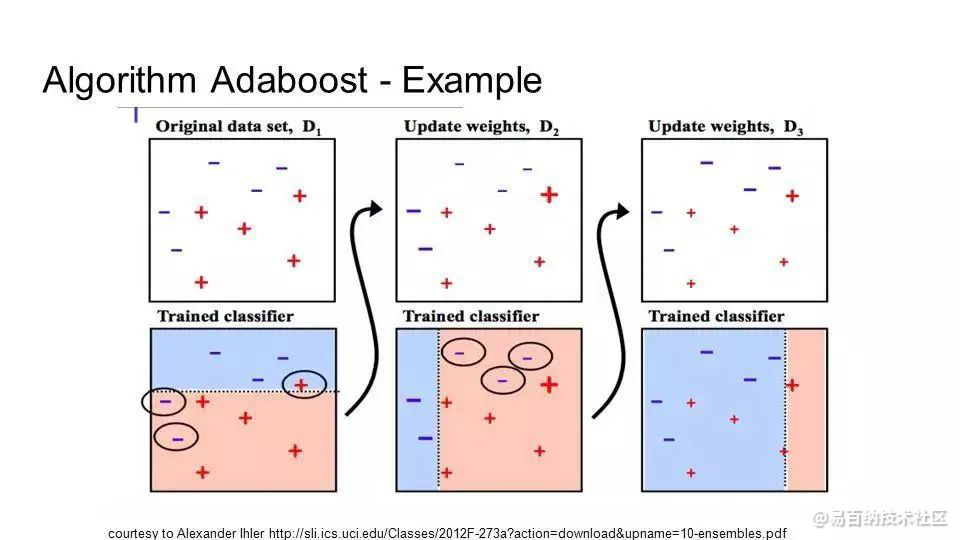
AdaBoost
AdaBoost常与短决策树一起使用。 在创建第一棵树之后,每个训练实例在树上的性能都决定了下一棵树需要在这个训练实例上投入多少关注。难以预测的训练数据会被赋予更多的权重,而易于预测的实例被赋予更少的权重。 模型按顺序依次创建,每个模型的更新都会影响序列中下一棵树的学习效果。在建完所有树之后,算法对新数据进行预测,并且通过训练数据的准确程度来加权每棵树的性能。
因为算法极为注重错误纠正,所以一个没有异常值的整洁数据十分重要。
初学者在面对各种各样的机器学习算法时提出的一个典型问题是“我应该使用哪种算法?”问题的答案取决于许多因素,其中包括:
- 数据的大小,质量和性质;
- 可用的计算时间;
- 任务的紧迫性;
- 你想要对数据做什么。
机器学习是一门宏大而精彩的学科,它对未来的种种不可能提供了可能性,只有真正了解本质才能对这个无限的世界展开更深的探索,即使是一位经验丰富的数据科学家,在尝试不同的算法之前,也无法知道哪种算法会表现最好。 虽然还有很多其他的机器学习算法,但这些算法是最受欢迎的算法。 如果你是机器学习的新手,这是一个很好的学习起点。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:10213次2021-04-20 15:42:26
-
浏览量:7151次2021-05-24 15:13:24
-
浏览量:5874次2021-06-23 15:25:25
-
浏览量:17484次2021-05-31 17:01:39
-
浏览量:5993次2021-08-09 16:11:19
-
浏览量:5853次2021-06-22 16:53:40
-
浏览量:6248次2021-06-16 11:22:18
-
浏览量:5426次2021-04-27 16:30:07
-
浏览量:10615次2021-06-09 12:09:57
-
浏览量:5143次2021-04-21 17:05:28
-
浏览量:5128次2021-04-21 17:05:56
-
浏览量:969次2023-06-02 17:42:13
-
浏览量:841次2024-02-28 15:03:08
-
浏览量:3716次2019-09-18 22:22:32
-
浏览量:4793次2021-06-28 14:10:22
-
浏览量:1398次2023-10-13 17:19:32
-
浏览量:981次2023-09-27 18:35:10
-
浏览量:1024次2023-03-14 13:50:59
-
浏览量:1071次2023-06-03 16:03:47

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
