

【深度学习】详解CNN实现手写数字识别(keras)
文章目录
1 MNIST数据集
2 导入数据
3 MLP
4 简单CNN
5 改进CNN
6 训练API的介绍
7 通道和卷积核辨析1 MNIST数据集
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60,000个示例的训练集以及10,000个示例的测试集.

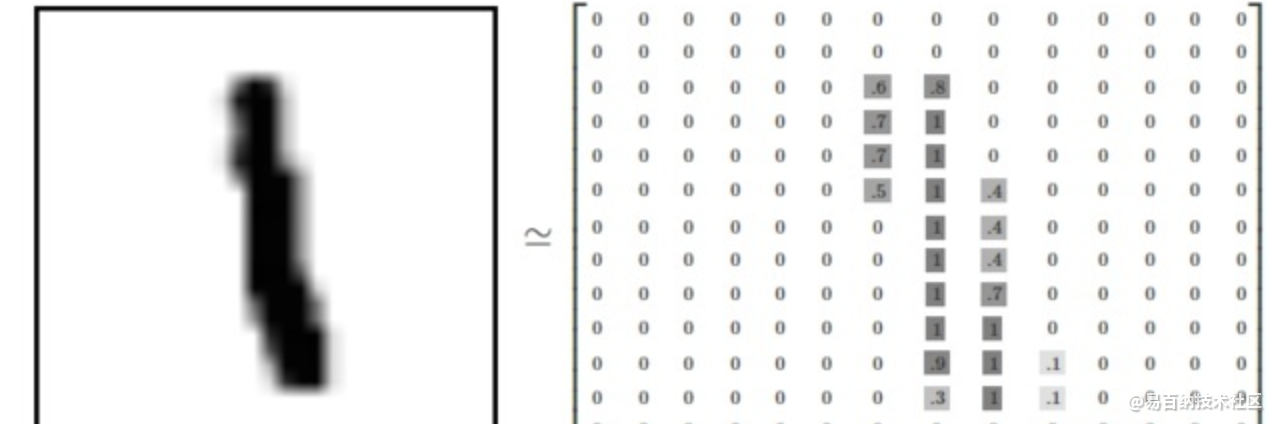
我们把这个数组展开成一个向量,长度是 28x28 = 784。如何展开这个数组(数字间的顺序)不重要,只要保持各个图片采用相同的方式展开。从这个角度来看,MNIST数据集的图片就是在784维向量空间里面的点, 并且拥有比较复杂的结构 (提醒: 此类数据的可视化是计算密集型的)。
展平图片的数字数组会丢失图片的二维结构信息。这显然是不理想的,最优秀的计算机视觉方法会挖掘并利用这些结构信息,我们会在后续教程中介绍。但是在这个教程中我们忽略这些结构,所介绍的简单数学模型,softmax回归(softmax regression),不会利用这些结构信息。
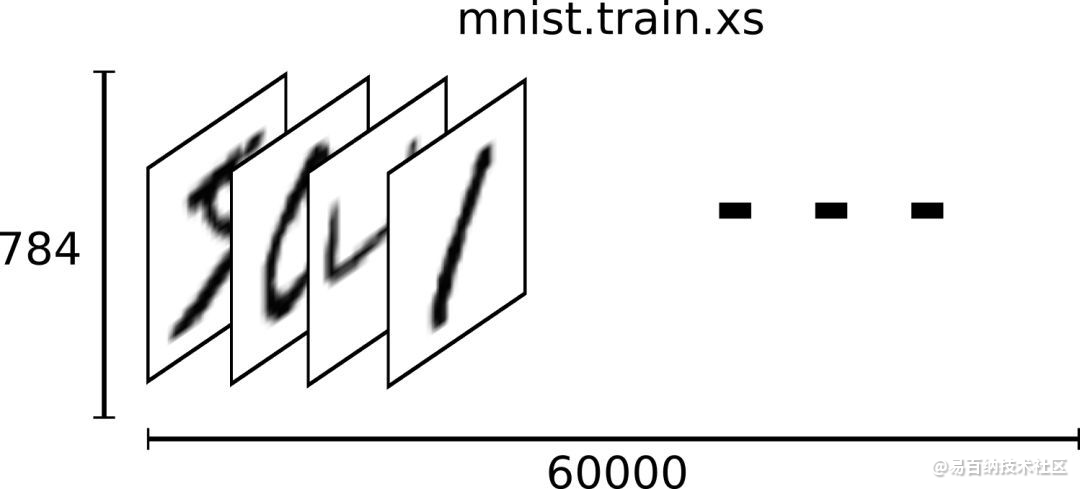
因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的向量,第一个维度数字就是训练集中包含的图片个数,用来索引图片,第二个维度的数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。
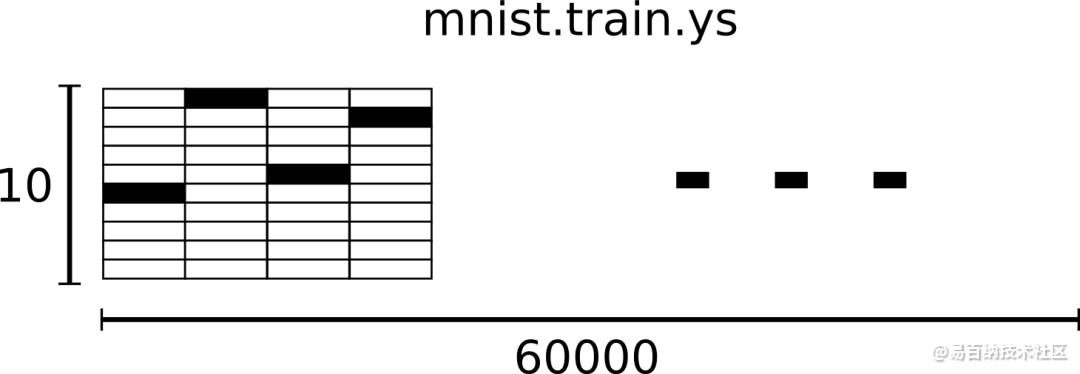
相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字。为了用于这个教程,我们使标签数据是"one-hot vectors"。 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。
2 导入数据
from keras.datasets import mnist
from matplotlib import pyplot as plt
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
# 从Keras导入Mnist数据集
(X_train, y_train), (X_validation, y_validation) = mnist.load_data()
# 显示4张手写数字的图片
plt.subplot(221)
plt.imshow(X_train[0], cmap=plt.get_cmap('gray'))
plt.subplot(222)
plt.imshow(X_train[1], cmap=plt.get_cmap('gray'))
plt.subplot(223)
plt.imshow(X_train[2], cmap=plt.get_cmap('gray'))
plt.subplot(224)
plt.imshow(X_train[3], cmap=plt.get_cmap('gray'))
plt.show()
# 设定随机种子
seed = 7
np.random.seed(seed)
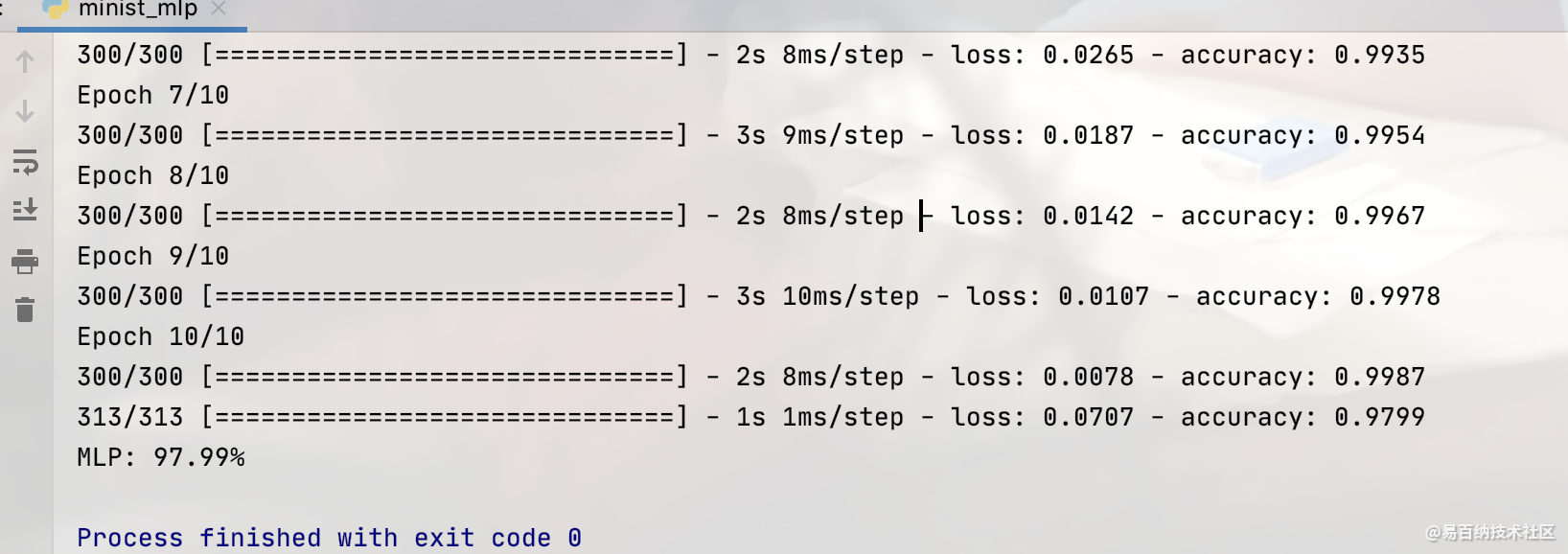
3 MLP
在采用卷积神经网络处理手写数字识别这个问题之前,先采用多层感知器来简单地实现一下这个问题,作为比较的基准,看一下卷积神经网络在图像识别这个问题.上具备的优势。在这个简单的手写数字识别问题中,也许卷积神经网络准确度的提升不会很大,但是这会加深我们对卷积神经网络的理解。
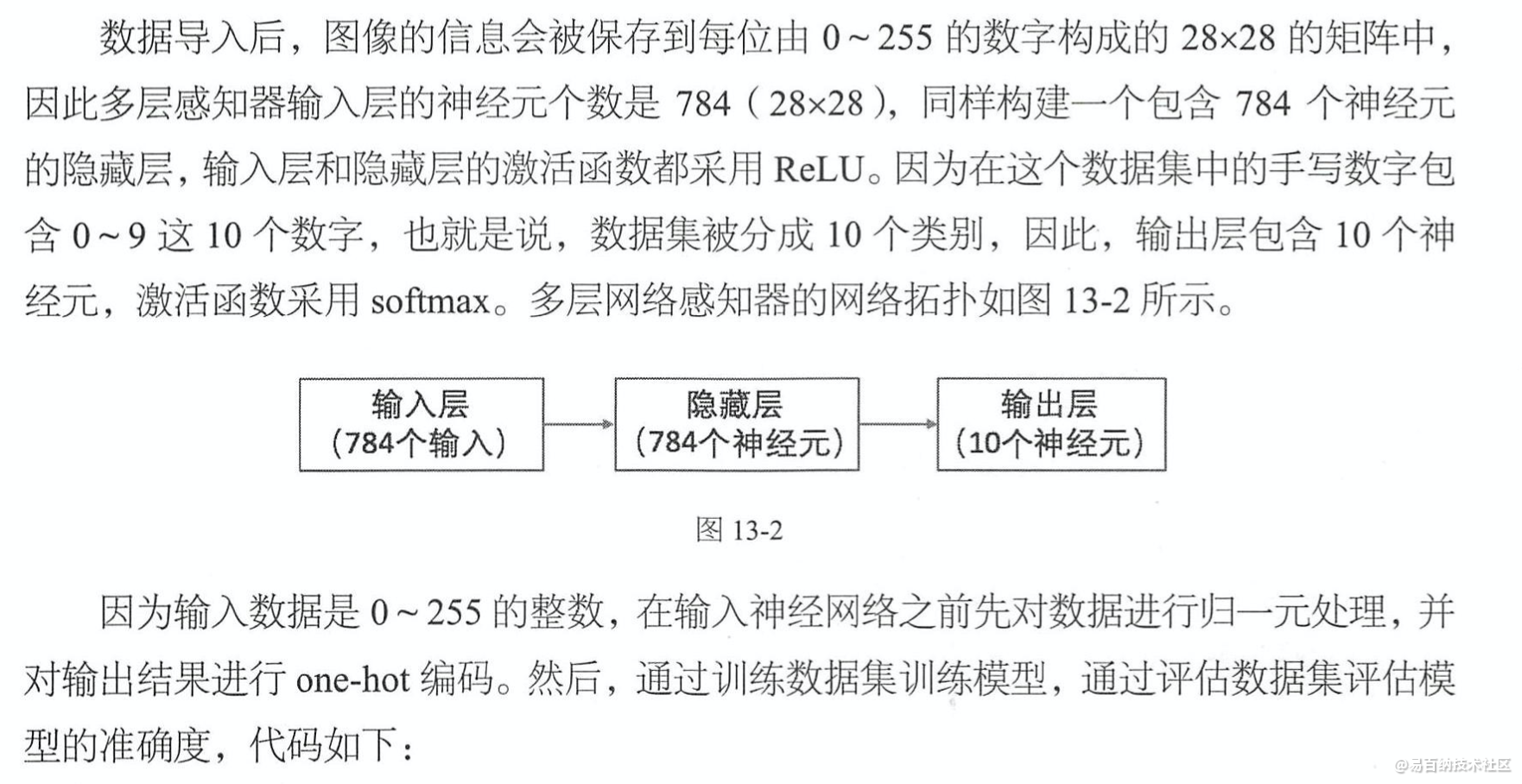
# 定义基准MLP模型
def create_model():
# 创建模型
model = Sequential()
model.add(Dense(units=num_pixels, input_dim=num_pixels, kernel_initializer='normal', activation='relu'))
model.add(Dense(units=num_classes, kernel_initializer='normal', activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
4 简单CNN

(6)输出层有10个神经元,在MNIST数据集的输出具有10个分类,因此采用softmax激活函数,输出每张图片在每个分类上的得分。
cov2d第一个参数可以理解为,卷积层提取特征,池化层提取更重要的特征。压缩是两个层都要进行的工作。
Feature Map(特征图)是输入图像经过神经网络卷积产生的结果,表征的是神经空间内一种特征;其分辨率大小取决于先前卷积核的步长 。
层与层之间会有若干个卷积核(kernel),上一层中的每个feature map跟每个卷积核做卷积,对应产生下一层的一个feature map。
feature map的含义在计算机视觉领域基本一致,可以简单译成特征图,例如RGB图像,所有像素点的R可以认为一个feature map(这个概念与在CNN里面概念是一致的)。
卷积核:二维的矩阵
滤波器:多个卷积核组成的三维矩阵,多出的一维是通道。
先介绍一些术语:layers(层)、channels(通道)、feature maps(特征图),filters(滤波器),kernels(卷积核)。
从层次结构的角度来看,层和滤波器的概念处于同一水平,而通道和卷积核在下一级结构中。通道和特征图是同一个事情。一层可以有多个通道(或者说特征图)。如果输入的是一个RGB图像,那么就会有3个通道。
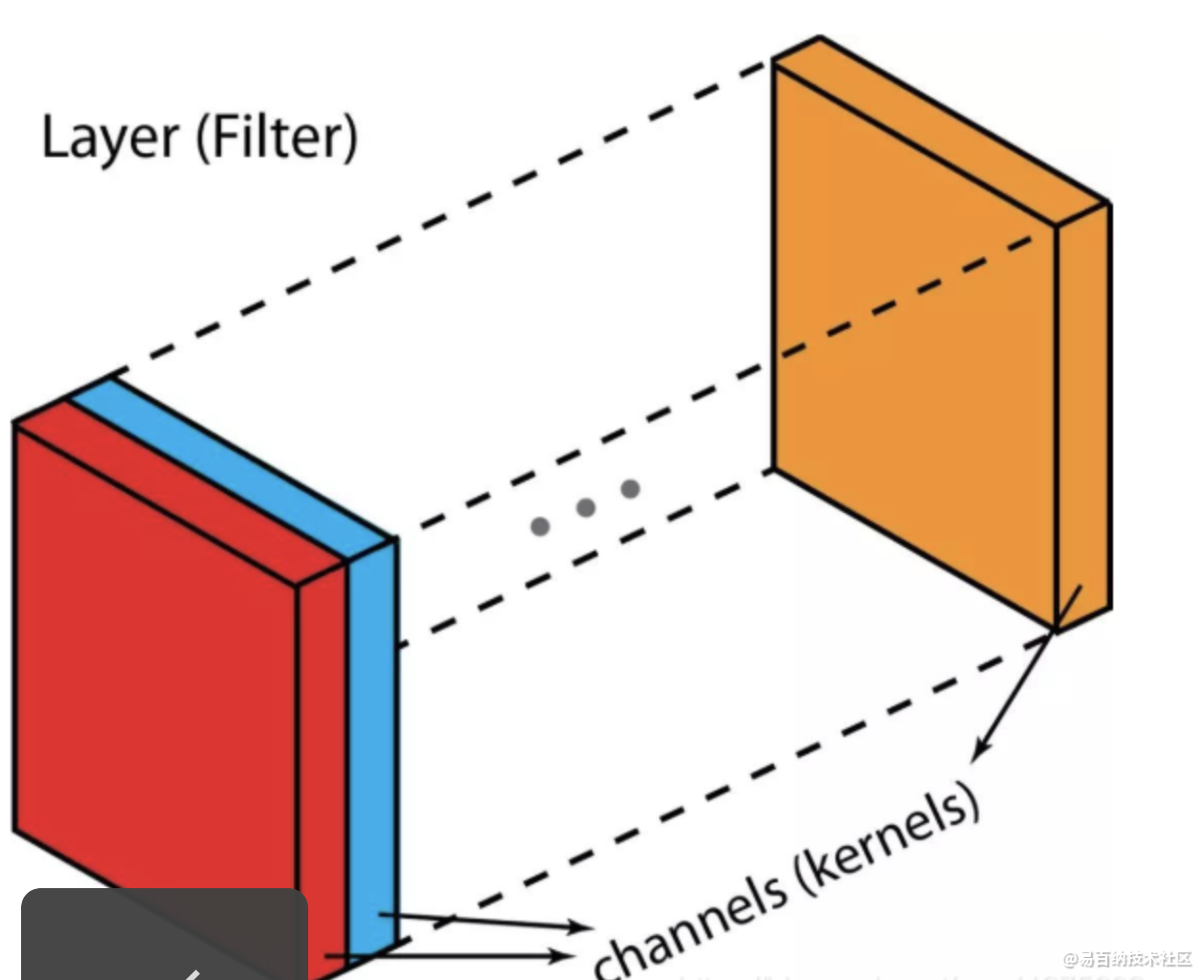
filter和kernel之间的不同很微妙。很多时候,它们可以互换,所以这可能造成我们的混淆。
那它们之间的不同在于哪里呢?
一个“Kernel”更倾向于是2D的权重矩阵。而“filter”则是指多个Kernel堆叠的3D结构。如果是一个2D的filter,那么两者就是一样的。但是一个3Dfilter,在大多数深度学习的卷积中,它是包含kernel的。每个卷积核都是独一无二的,主要在于强调输入通道的不同方面。
def create_model():
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(1, 28, 28), activation='relu',padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
5 改进CNN


# 设定随机种子
# 创建模型
def create_model():
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=50, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
=6 训练API的介绍
from keras.layers import Dense, Activation, Convolution2D, MaxPooling2D, Flatten
首先是数据预处理和model的设置。 然后添加第一个卷积层,滤波器数量为32,大小是5*5,Padding方法是same即不改变数据的长度和宽带。 因为是第一层所以需要说明输入数据的 shape ,激励选择 relu 函数。代码如下
model.add(Convolution2D(
batch_input_shape=(64, 1, 28, 28),
filters=32,
kernel_size=5,
strides=1,
padding='same', # Padding method
data_format='channels_first',
))
model.add(Activation('relu'))
第一层 pooling(池化,下采样),分辨率长宽各降低一半,输出数据shape为(32,14,14)
model.add(MaxPooling2D(
pool_size=2,
strides=2,
padding='same', # Padding method
data_format='channels_first',
))
再添加第二卷积层和池化层
model.add(Convolution2D(64, 5, strides=1, padding='same', data_format='channels_first'))
model.add(Activation('relu'))
model.add(MaxPooling2D(2, 2, 'same', data_format='channels_first'))
经过以上处理之后数据shape为(64,7,7),需要将数据抹平成一维,再添加全连接层1
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
添加全连接层2(即输出层)
model.add(Dense(10))
model.add(Activation('softmax'))
设置adam优化方法,loss函数, metrics方法来观察输出结果
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
7 通道和卷积核辨析
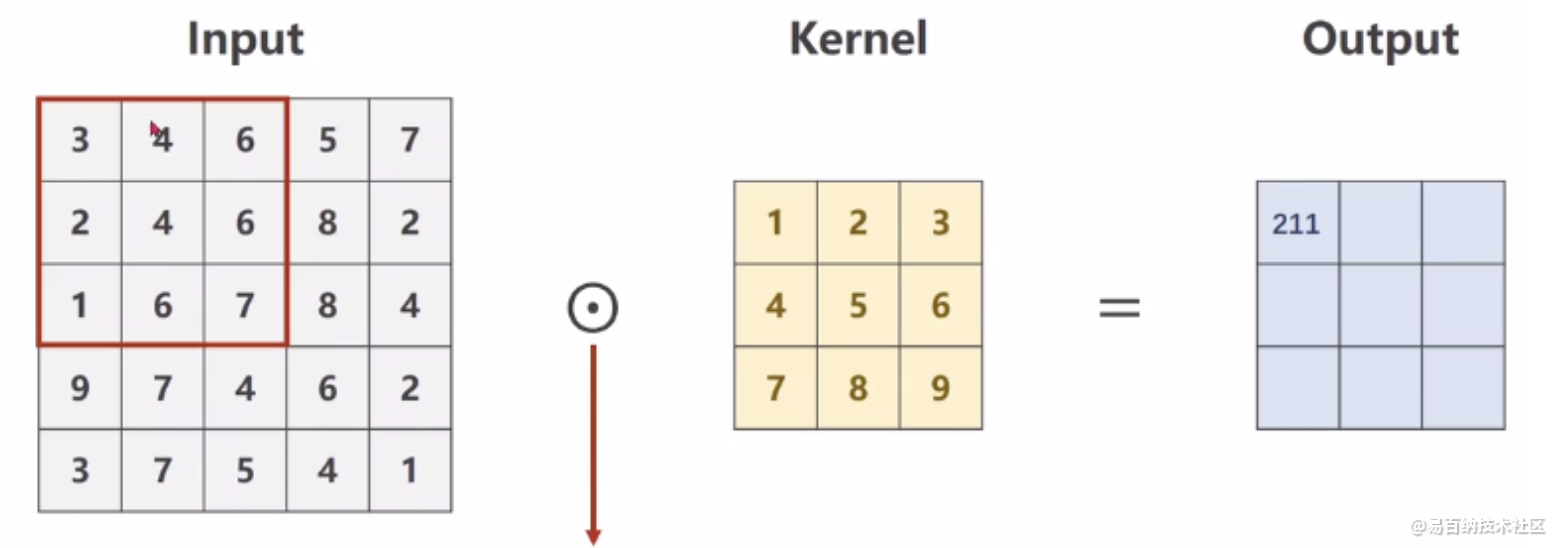
单通道卷积
以单通道卷积为例,输入为(1,5,5),分别表示1个通道,宽为5,高为5。假设卷积核大小为3x3,padding=0,stride=1。
多通道卷积
以彩色图像为例,包含三个通道,分别表示RGB三原色的像素值,输入为(3,5,5),分别表示3个通道,每个通道的宽为5,高为5。假设卷积核只有1个,卷积核通道为3,每个通道的卷积核大小仍为3x3,padding=0,stride=1。
卷积过程如下,每一个通道的像素值与对应的卷积核通道的数值进行卷积,因此每一个通道会对应一个输出卷积结果,三个卷积结果对应位置累加求和,得到最终的卷积结果(这里卷积输出结果通道只有1个,因为卷积核只有1个。卷积多输出通道下面会继续讲到)。
可以这么理解:最终得到的卷积结果是原始图像各个通道上的综合信息结果。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4838次2021-04-09 16:28:04
-
浏览量:171次2023-08-15 23:15:48
-
2023-01-12 11:47:40
-
浏览量:1669次2023-08-29 12:54:00
-
浏览量:1549次2024-02-06 11:56:53
-
浏览量:10392次2021-02-23 14:31:42
-
浏览量:1752次2023-09-25 10:59:14
-
浏览量:5853次2021-06-22 16:53:40
-
浏览量:6244次2021-05-17 16:52:58
-
浏览量:189次2023-07-30 17:57:28
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:1143次2024-02-01 14:20:47
-
浏览量:267次2023-07-25 11:57:50
-
浏览量:123次2023-08-23 08:46:26
-
浏览量:126次2023-09-14 22:04:44
-
浏览量:4333次2018-02-14 10:30:11
-
浏览量:8550次2021-07-13 10:59:24
-
浏览量:4529次2024-02-20 17:35:09
-
浏览量:192次2023-08-16 17:42:24

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
