

【深度学习模型的训练与评估】一个实例:Iris多分类
文章目录:
1 评估深度学习模型
1.1 自动评估
1.2 手动评估
1.3 k折交叉验证
2 在Keras中使用Sklearn
3 深度学习模型调参数
4 Iris多分类
4.1 数据集分析
4.2 代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1 评估深度学习模型
1.1 自动评估
在Keras中设置验证集大小实现。
#训练模型并自动评估模型
model . fit(x=x , y=Y , epochs=l50 , batch_ size=lO , validation_split=0.2)- 1
- 2
1.2 手动评估
x train, x validation, Y train, Y validation =train_test_split(x,Y,test_size=0.2 , random_state=seed)
- 1
1.3 k折交叉验证
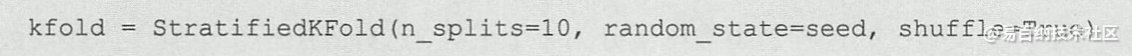

代码中的循环会增加计算复杂程度,但是可以找到一个更优秀的模型。
2 在Keras中使用Sklearn
代码使用KerasClassifier为例子:
目的是为了更好使用机器学习库中的一些方法。
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from keras.wrappers.scikit_learn import KerasClassifier
# 构建模型
def create_model():
# 构建模型
model = Sequential()
model.add(Dense(units=12, input_dim=8, activation='relu'))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
seed = 7
# 设定随机数种子
np.random.seed(seed)
# 导入数据
dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',')
# 分割输入x和输出Y
x = dataset[:, 0 : 8]
Y = dataset[:, 8]
#创建模型 for scikit-learn
model = KerasClassifier(build_fn=create_model, epochs=150, batch_size=10, verbose=0)
# 10折交叉验证
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(model, x, Y, cv=kfold)
print(results.mean())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3 深度学习模型调参数
这种自动化选择超参数的手段只适用于小型数据集哈。
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
from sklearn.model_selection import GridSearchCV
from keras.wrappers.scikit_learn import KerasClassifier
# 构建模型
def create_model(optimizer='adam', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=12, kernel_initializer=init, input_dim=8, activation='relu'))
model.add(Dense(units=8, kernel_initializer=init, activation='relu'))
model.add(Dense(units=1, kernel_initializer=init, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
seed = 7
# 设定随机数种子
np.random.seed(seed)
# 导入数据
dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',')
# 分割输入x和输出Y
x = dataset[:, 0 : 8]
Y = dataset[:, 8]
#创建模型 for scikit-learn
model = KerasClassifier(build_fn=create_model, verbose=0)
# 构建需要调参的参数
param_grid = {}
param_grid['optimizer'] = ['rmsprop', 'adam']
param_grid['init'] = ['glorot_uniform', 'normal', 'uniform']
param_grid['epochs'] = [50, 100, 150, 200]
param_grid['batch_size'] = [5, 10, 20]
# 调参
grid = GridSearchCV(estimator=model, param_grid=param_grid)
results = grid.fit(x, Y)
# 输出结果
print('Best: %f using %s' % (results.best_score_, results.best_params_))
means = results.cv_results_['mean_test_score']
stds = results.cv_results_['std_test_score']
params = results.cv_results_['params']
for mean, std, param in zip(means, stds, params):
print('%f (%f) with: %r' % (mean, std, param))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
4 Iris多分类
4.1 数据集分析
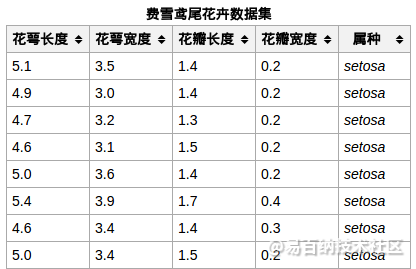
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。
样本局部截图:
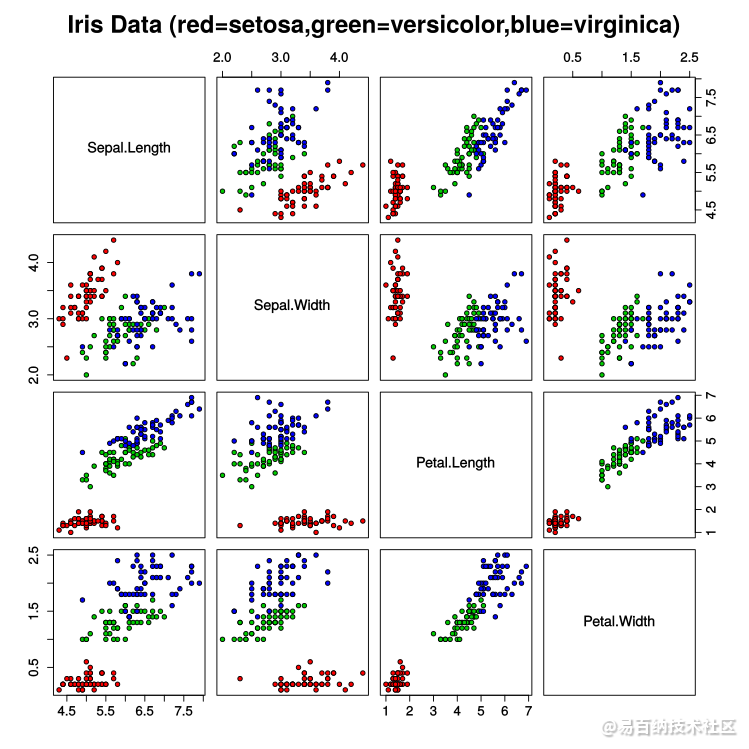
将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不同品种的花),可以构建12种组合(其实只有6种,另外6种与之对称),如图所示:
4.2 代码
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(optimizer='adam', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
model = KerasClassifier(build_fn=create_model, epochs=200, batch_size=5, verbose=0)
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(model, x, Y, cv=kfold)
print('Accuracy: %.2f%% (%.2f)' % (results.mean()*100, results.std()))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
解释:
不同的层可能使用不同的关键字来传递初始化方法,一般来说指定初始化方法的关键字是kernel_initializer 和 bias_initializer,例如:
model.add(Dense(64,
kernel_initializer='random_uniform',
bias_initializer='zeros'))- 1
- 2
- 3
随机初始化+Batch Normalization
np.random.randn()的结果是以0为均值、以1为标准差的正态分布,其值可正可负。
for l in range(1,L):
W = np.random.randn(num_of_dim[l-1],num_of_dim[l])
b = np.zeros((num_of_dim[l],1)) # b的维度是(当前层单元数,1)- 1
- 2
- 3
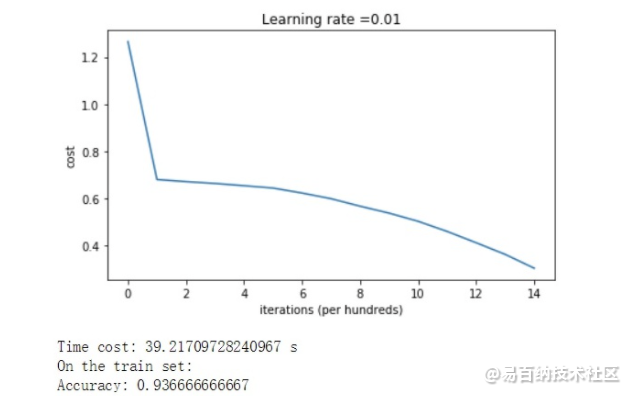
如图2所示,cost最后降到比较低,分类准确率为92%。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:16132次2021-04-28 16:21:52
-
浏览量:4480次2021-04-23 14:09:15
-
浏览量:4337次2021-04-19 14:54:23
-
浏览量:12992次2021-05-11 15:08:10
-
浏览量:11973次2021-05-04 20:20:07
-
浏览量:7415次2021-06-15 10:28:29
-
浏览量:141次2023-08-31 08:46:00
-
浏览量:908次2023-10-25 18:39:50
-
浏览量:1658次2023-04-13 10:45:45
-
浏览量:758次2023-06-21 14:07:39
-
浏览量:5084次2021-04-21 17:06:33
-
浏览量:4741次2021-04-08 11:23:42
-
浏览量:9020次2021-05-13 12:53:50
-
浏览量:775次2023-06-08 10:35:09
-
浏览量:6022次2021-07-30 10:33:41
-
浏览量:8140次2021-07-13 10:59:24
-
浏览量:780次2023-03-09 09:14:06
-
浏览量:4066次2021-05-14 09:47:57
-
浏览量:157次2023-08-30 15:28:02

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
