

多层感知器(MLP)详解【基于印第安人糖尿病数据】
文章目录:
1 概述
2 Pima印第安人数据集
3 导入数据和keras
4 定义模型
5 编译模型
6 训练
7 评估和预测
8 完整代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1 概述
多层感知器是最简单的神经网络模型,用于处理机器学习中的分在介绍单层感知器的时候,我们提到对于非线性可分问题,单层感知器是很难解决的,比如下面这个例子:
类与回归问题。
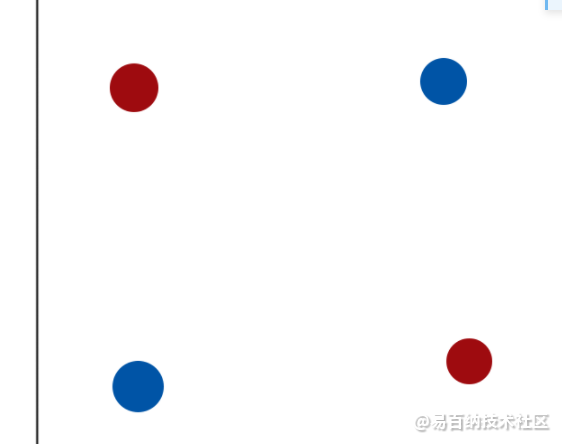
很简单的一个分布,但事实上就是无法用直线进行分类,后来就出现了多层感知器,主要改变的地方是把第一层的感知器的输出作为第二层感知器的输入,即使只是简单添加一层感知器,也足以解决xor问题,关键的原因是,多了一层感知器,就像对原来的输入做了一个映射,第一层感知器的目的是对输入进行映射使得数据在新的空间能够线性可分,然后我们再利用第二层感知器对数据进行分类,我们通过训练模型,使得第一层感知器能更好地重新映射原输入,第二层感知器能更好地分类。
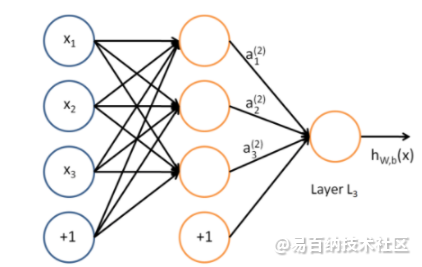
从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是 f (W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数:
注:神经网络中的Sigmoid型激活函数:
1. 为嘛使用激活函数?
a. 不使用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
b. 使用激活函数,能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。
激活函数需要具备以下几点性质:
1. 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参 数。
2. 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
3. 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
多层感知器,又叫深度前馈网络、前馈神经网络。最左边的是输入层,就是我们的输入数据,最右边的是输出层,中间的就是隐藏层(因为训练数据并没有直接表明隐藏层的每一层的所需输出),实际上就是由感知器构成。从现在开始,感知器就开始称为神经元,而这整个包含了输入层、隐藏层和输出层的结构就是大名鼎鼎的神经网络。可以看到相邻层之间的神经元是全连接的。
这个例子没有很多代码,本章将会一步一步地实现这个例子,以便清晰地展示如何
创建一个模型 将按照以下步骤创建第一个神经网络模型
导入数据
定义模型
编译模型
训练
评估
汇总代码- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2 Pima印第安人数据集
该数据集最初来自国家糖尿病/消化/肾脏疾病研究所。数据集的目标是基于数据集中包含的某些诊断测量来诊断性的预测患者是否患有糖尿病。
从较大的数据库中选择这些实例有几个约束条件。尤其是,这里的所有患者都是Pima印第安至少21岁的女性。
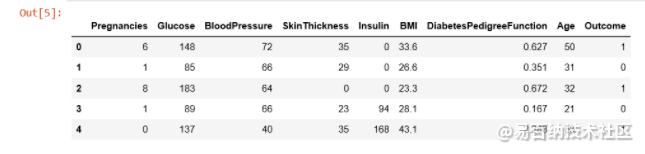
数据集由多个医学预测变量和一个目标变量组成Outcome。预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。

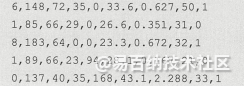
数据前五行:
3 导入数据和keras
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 设定随机数种子
np.random.seed(7)
# 导入数据
dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

分割数据集 前8列为输入。
# 分割输入x和输出Y
x = dataset[:, 0 : 8]
Y = dataset[:, 8]
- 1
- 2
- 3
我们先使用了初始化随机数种子,确保输出结果的可重复,然后完成了导入数据的操作。接下来就开始构建第一个神经网络模型。
4 定义模型

# 创建模型
model = Sequential()
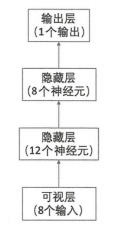
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))- 1
- 2
- 3
- 4
- 5
5 编译模型
也就是指定优化器和学习率,loss等。
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']- 1
- 2
BCE二进制交叉熵作为损失函数。
公式分析
binary_crossentropy损失函数的公式如下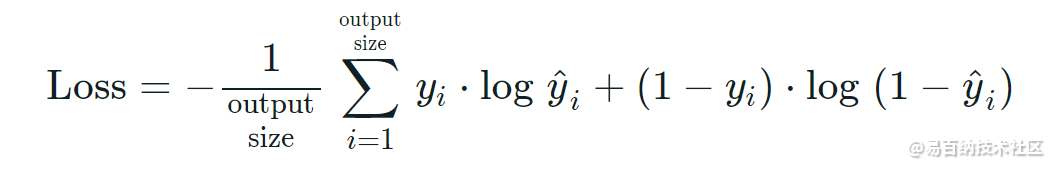
根据公式我们可以发现,i∈[1,output_size] 中每个i是相互独立的,互不干扰,因此它一般用于多标签分类(yolov3的分类损失函数就是用这个),比如说我们有标签 ‘人’,‘男人’, ‘女人’ ,如果使用categorical_crossentropy,由于它的数学公式含义,标签只能是其中一个,而binary_crossentropy各个i是相互独立的,意味着是有可能出现一下这种情况:(举例)
‘人’ 标签的概率是0.9, ‘男人’ 标签概率是0.6,‘女人’ 标签概率是0.3。
那么我们有足够的说服力断定他是 ‘人’,并且很可能是 ‘男人’。
(一般搭配sigmoid激活函数使用):
其他的损失函数这里不做过多介绍。
6 训练

# 训练模型
model.fit(x=x, y=Y, epochs=150, batch_size=10)- 1
- 2
7 评估和预测
# 评估模型
scores = model.evaluate(x=x, y=Y)
print('\n%s : %.2f%%' % (model.metrics_names[1], scores[1]*100))
- 1
- 2
- 3
8 完整代码
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 设定随机数种子
np.random.seed(7)
# 导入数据
dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',')
# 分割输入x和输出Y
x = dataset[:, 0 : 8]
Y = dataset[:, 8]
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(x=x, y=Y, epochs=150, batch_size=10)
# 评估模型
scores = model.evaluate(x=x, y=Y)
print('\n%s : %.2f%%' % (model.metrics_names[1], scores[1]*100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
metrics_names[1]是ACC,scores[1]*100是ACC得分。
就到这啦,关于数据集网上随便一搜下载即可。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4382次2021-04-14 16:23:03
-
浏览量:3108次2020-09-30 10:45:58
-
浏览量:6872次2020-12-20 19:38:14
-
浏览量:1989次2018-04-19 15:50:17
-
浏览量:5330次2021-08-09 16:10:57
-
浏览量:4871次2021-08-09 16:10:30
-
浏览量:6695次2021-08-09 16:09:53
-
浏览量:2762次2017-11-01 14:21:07
-
浏览量:1466次2019-05-25 09:45:04
-
浏览量:1701次2019-12-04 10:12:05
-
浏览量:5335次2021-08-13 15:39:02
-
浏览量:6773次2021-05-04 20:17:10
-
浏览量:1721次2019-12-10 09:28:12
-
浏览量:5427次2021-06-23 15:25:25
-
浏览量:2640次2020-08-25 18:07:51
-
浏览量:6630次2021-04-19 14:56:57
-
浏览量:3166次2020-07-22 14:52:19
-
浏览量:4472次2017-08-24 11:16:41
-
浏览量:2849次2019-10-22 15:56:06

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
