

机器学习之交叉验证方法详解【基于Scikit-Learn】
目录:
1 为什么交叉验证
2 交叉验证方法
2.1 简单的交叉验证
2.2 k折交叉验证 k-fold cross validation
2.3 代码
3 留一法 leave-one-out cross validation
3.1 测试代码
3.2 输出结果1 为什么交叉验证
在机器学习与数据挖掘中进行模型验证的一个重要目的是要选出一个最合适的模型。对于有监督学习而言,我们希望模型对于未知数据具有很强的泛化能力,所以就需要模型验证这一过程来评估不同的模型对于未知数据的表现效果。
最先我们用训练准确度(用全部数据进行训练和测试)来衡量模型的效果,这种方法容易导致模型过拟合。最初,为了解决这个问题,我们将所有数据分成两部分:训练集 和 测试集。我们用训练集进行模型训练,得到的模型再用测试集来衡量模型的预测表现能力,这种度量方式叫测试准确度,这种方式可以有效避免过拟合。
测试准确度的一个缺点是其样本准确度是一个高方差估计(high variance estimate),所以该样本准确度会依赖不同的测试集,其表现效果不尽相同。
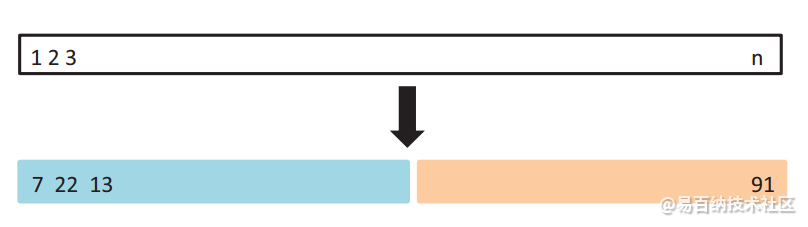
例如,如上图所示,我们可以将蓝色部分的数据作为训练集(包含7、22、13等数据),将右侧的数据作为测试集(包含91等),这样通过在蓝色的训练集上训练模型,在测试集上观察不同模型不同参数对应的MSE的大小,就可以合适选择模型和参数了。
最终模型与参数的选取将极大程度依赖于你对训练集和测试集的划分方法。
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# read in the iris data
iris = load_iris()
X = iris.data
y = iris.target
for i in range(1, 5):
print("Random times", i, ", accuracy score is:",end=' ')
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=i)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print(metrics.accuracy_score(y_test, y_pred),'\n')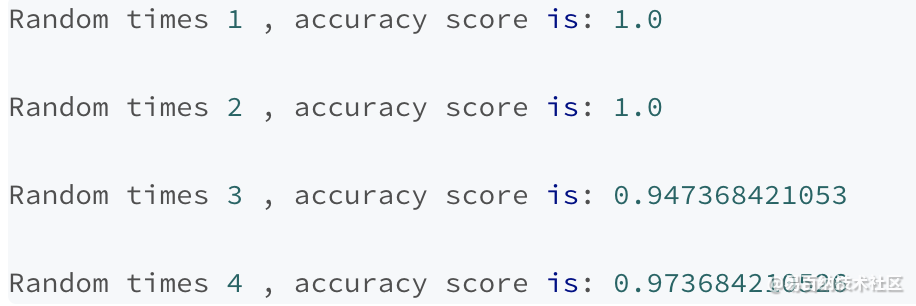
上面的测试准确率可以看出,不同的训练集、测试集分割的方法导致其准确率不同,而交叉验证的基本思想是:将数据集进行一系列分割,生成一组不同的训练测试集,然后分别训练模型并计算测试准确率,最后对结果进行平均处理。这样来有效降低测试准确率的差异。
2 交叉验证方法
2.1 简单的交叉验证
1、 从全部的训练数据 S中随机选择 中随机选择 s的样例作为训练集 train,剩余的 作为测试集 作为测试集 test。
2、 通过对测试集训练 ,得到假设函数或者模型 。
3、 在测试集对每一个样本根据假设函数或者模型,得到训练集的类标,求出分类正确率。
4,选择具有最大分类率的模型或者假设。
这种方法称为 hold -out cross validation 或者称为简单交叉验证。由于测试集和训练集是分开的,就避免了过拟合的现象
2.2 k折交叉验证 k-fold cross validation

1、 将全部训练集 S分成 k个不相交的子集,假设 S中的训练样例个数为 m,那么每一个子 集有 m/k 个训练样例,,相应的子集称作 {s1,s2,…,sk}。
2、每次从分好的子集中里面,拿出一个作为测试集,其它k-1个作为训练集
3、根据训练训练出模型或者假设函数。
4、 把这个模型放到测试集上,得到分类率。
5、计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率。
这个方法充分利用了所有样本。但计算比较繁琐,需要训练k次,测试k次。
2.3 代码
用sklearn中的数据集iris
导入需要的包
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (brier_score_loss, precision_score, recall_score,f1_score)
from sklearn.model_selection import learning_curve
import numpy as np
import matplotlib.pyplot as plt
#取出需要的数据,其中iris_X有4个属性,共有150个样本点,iris_y的取值有3个,分别是0,1,2
iris = load_iris()
iris_X = iris.data
iris_y = iris.target
print(iris_X.size)
print(iris_X)
print(iris_y)
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)
print(X_train.size)
clf = LogisticRegression(random_state=0, solver='newton-cg', multi_class='multinomial')
#训练模型,这里计算出参数w和b
clf.fit(X_train, y_train)
print(clf.coef_)
print(clf.intercept_)
y_pred = clf.predict(X_test)
print(clf.predict(X_test))
print(y_test)
print("\tPrecision: %1.3f" % precision_score(y_test, y_pred, average="micro"))
print("\tRecall: %1.3f" % recall_score(y_test, y_pred, average="micro"))
print("\tF1: %1.3f\n" % f1_score(y_test, y_pred, average="micro"))
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.0)
train_sizes, train_loss, test_loss = learning_curve( clf, X_train, y_train, cv=10,
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
train_loss_mean = 1-np.mean(train_loss, axis=1)
test_loss_mean = 1-np.mean(test_loss, axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
![k折交叉验证,模型可视化。这里train_sizes=\[0.1, 0.25, 0.5, 0.75, 1\]是指,按总体比例的\[0.1, 0.25, 0.5, 0.75, 1\]取数据,
用 于 训 练 和 验 证 的 样 本 个 数 = \[ 15 , 37.5 , 75 , 112.5 , 150 \] 用于训练和验证的样本个数=\[15,37.5,75,112.5,150\]用于训练和验证的样本个数=\[15,37.5,75,112.5,150\],
由于k = 10 k=10k=10,
用 于 验 证 的 样 本 个 数 = \[ 1.5 , 3.75 , 7.5 , 11.25 , 15 \] 用于验证的样本个数=\[1.5,3.75,7.5,11.25,15\]用于验证的样本个数=\[1.5,3.75,7.5,11.25,15\],
用 于 训 练 的 样 本 个 数 = \[ 15 , 37.5 , 75 , 112.5 , 150 \] − \[ 1.5 , 3.75 , 7.5 , 11.25 , 15 \] 用于训练的样本个数=\[15,37.5,75,112.5,150\]-\[1.5,3.75,7.5,11.25,15\]用于训练的样本个数=\[15,37.5,75,112.5,150\]−\[1.5,3.75,7.5,11.25,15\]
如图所示横坐标为用于训练的样本个数。](https://ebaina.oss-cn-hangzhou.aliyuncs.com/res/article/202304/26/644879596c05666472.png)

3 留一法 leave-one-out cross validation
留一法就是每次只留下一个样本做测试集,其它样本做训练集,如果有k个样本,则需要训练k次,测试k次。
留一发计算最繁琐,但样本利用率最高。适合于小样本的情况。
就是将样本集中的样本每次抽取一个不同的样本作为测试集,剩余的样本作为训练集。需要进行原样本个数次抽取,以进行后续的操作。假设一个.mat文件有310个样本,那么每次抽取一个不同的样本做测试,剩余的299个样本做训练。需要进行310次这样的过程,但是每次选取的做测试的样本是不同的,那么每次训练集的样本也是不同的。由于留一交叉验证的操作的次数十分多,这样选取出来的主成分更具普遍性,可以避免一些不必要的波动,避免一些数据分析时出现有时效果好,有时效果差,这样摇摆不定的情况。因此广受青睐,但是留一交叉验证也有其弊端,样本过多运算时间过长。
适用于小样本。
3.1 测试代码
from sklearn import model_selection
import numpy as np
X=np.array([[1,2],[3,4],[5,6],[7,8]])
labels=np.array([1,2,3,4])
lol=model_selection.LeaveOneOut()
print('*******************origin***********************')
for train_index,test_index in lol.split(X):
print('TRAIN_index',train_index,'Test_index',test_index)
X_train,X_test=X[train_index],X[test_index]
print('TRAIN data',X_train,'Test data',X_test,sep=' ')
print('*******************labels***********************')
for labels_train_index,labels_test_index in lol.split(labels):
print('TRAIN_index',labels_train_index,'Test_index',labels_test_index)
labels_X_train,labels_X_test=labels[labels_train_index],labels[labels_test_index]
print('TRAIN data',labels_X_train,'Test data',labels_X_test,sep=' ')
3.2 输出结果

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:558次2023-09-28 11:19:15
-
浏览量:4995次2021-04-12 16:28:50
-
浏览量:415次2023-09-11 11:42:09
-
浏览量:538次2023-09-04 14:17:53
-
浏览量:3454次2019-09-18 22:22:32
-
浏览量:2186次2024-02-05 15:51:53
-
浏览量:5616次2021-04-20 15:43:03
-
浏览量:1183次2023-03-29 10:55:15
-
浏览量:6393次2021-06-07 09:26:53
-
浏览量:4245次2021-06-30 11:34:00
-
浏览量:1690次2023-05-18 22:55:16
-
浏览量:563次2023-09-05 10:02:44
-
浏览量:5828次2021-04-14 16:24:29
-
浏览量:5245次2021-06-07 09:28:15
-
浏览量:1230次2023-01-28 13:55:15
-
浏览量:197次2023-08-15 22:50:27
-
浏览量:1117次2022-12-15 14:05:42
-
浏览量:6517次2021-04-14 16:23:53
-
浏览量:174次2023-08-16 18:28:43

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
