

实时分析数据库 Druid,Mark 一下
本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
前言
都说现在大数据生态圈用“百花齐放”来形容真的一点也不为过。之前的文章已经分别为大家介绍了现在企业中常用的即席查询框架 —— Presto 和 Kylin。实际上,还有一个未登场的“大佬”,它就是本期内容的主角:Druid !

Druid
Druid 简介
Druid 是一个高性能的实时分析数据库。它在 PB 级数据处理、毫秒级查询、数据实时处理方面,比传统的 OLAP 系统有显著的性能提升。
Druid 特点
Druid具有如下技术特点:
- 列式存储格式
Druid使用面向列的存储,这意味着它只需要加载特定查询所需的精确列。这为仅查看几列的查询提供了巨大的速度提升。此外,每列都针对其特定数据类型进行了优化,支持快速扫描和聚合。
- 高可用性与高可拓展性
Druid采用分布式、SN(share-nothing)架构,管理类节点可配置HA,工作节点功能单一,不相互依赖,这些特性都使得Druid集群在管理、容错、灾备、扩容等方面变得十分简单。Druid通常部署在数十到数百台服务器的集群中,并且可以提供数百万条记录/秒的摄取率,保留数万亿条记录,以及亚秒级到几秒钟的查询延迟。
- 大规模的并行查询
Druid可以在整个集群中进行大规模的并行查询。
- 实时摄取或批量处理
实时流数据分析。区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure-merge)-Tree结构使 Druid 拥有极高的实时写入性能;同时实现了实时数据在亚秒级内的可视化。
- 自愈、自平衡、易操作
作为运营商,要将群集扩展或缩小,只需添加或删除服务器,群集将在后台自动重新平衡,无需任何停机时间。如果任何Druid服务器发生故障,系统将自动路由损坏,直到可以更换这些服务器。Druid旨在全天候运行,无需任何原因计划停机,包括配置更改和软件更新。
- 云原生,容错的架构,不会丢失数据
一旦 Druid 摄取了您的数据,副本就会安全地存储在深层存储(通常是云存储,HDFS或共享文件系统)中。即使每个Druid服务器都出现故障,您的数据也可以从深层存储中恢复。对于仅影响少数 Druid 服务器的更有限的故障,复制可确保在系统恢复时仍可进行查询。
- 亚秒级的OLAP查询分析
Druid采用了列式存储、倒排索引、位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作。
- 丰富的数据分析功能
针对不同用户群体,Druid提供了友好的可视化界面、类SQL查询语言以及REST 查询接口。
Druid 的使用场景
了解了 Druid 有哪些常见的特点,我们还需要知道它具体的使用场景。
如果您的用例符合以下的几个描述,Druid 可能是一个不错的选择:
- 插入率非常高,但更新不常见
- 大多数查询都是聚合和报告查询(“分组依据”查询)。您可能还有搜索和扫描查询。
- 查询延迟定位为100毫秒到几秒钟
- 数据有一个时间组件(Druid包括与时间特别相关的优化和设计选择)。
- 可能有多个表,但每个查询只能访问一个大的分布式表。查询可能会触发多个较小的“查找”表。
- 有高基数数据列(例如URL,用户ID),需要对它们进行快速计数和排名。
- 希望从 Kafka,HDFS,平面文件或对象存储(如Amazon S3)加载数据。
要是感觉看的不是很懂,简洁地总结一下:
- 适用于将清洗好的记录实时录入,但不需要更新操作的场景
- 适用于支持宽表,不用join的场景(换句话说就是一张单表)
- 适用于实时性要求高的场景
- 适用于对数据质量的敏感度不高的场景
当然以上列举的都是 Druid 的适用情况,为了方便我们之后做技术选型,我们还需要知道它不支持哪些操作。
- 不支持精确去重
- 不支持 Join(只能进行 semi-join)
- 不支持根据主键的单条记录更新
所以如果不能接受这几点,则可以考虑放弃使用 Druid 了。
那 Druid 的常见应用领域有哪些呢 ?
- 点击流分析(网络和移动分析)
- 风险/欺诈分析
- 网络遥测分析(网络性能监控)
- 服务器指标存储
- 供应链分析(制造指标)
- 应用程序性能指标
- 商业智能/ OLAP
关于更详细的描述,建议大家去多浏览官网https://druid.apache.org/use-cases,这里不做过多赘述 。
下面来侃侃 Druid 的 架构 ~
Druid架构
Druid 采用多进程,分布式的架构;其架构易于运维及部署,便于部署在云环境中。每个 Druid 进程都可以被独立地配置和横向扩展,这种设计一方面赋予了Druid集群 最大的灵活性和可扩展性,另一方面以提供了更高的容错性:避免了个别组件的失效影响了系统的其他模块。
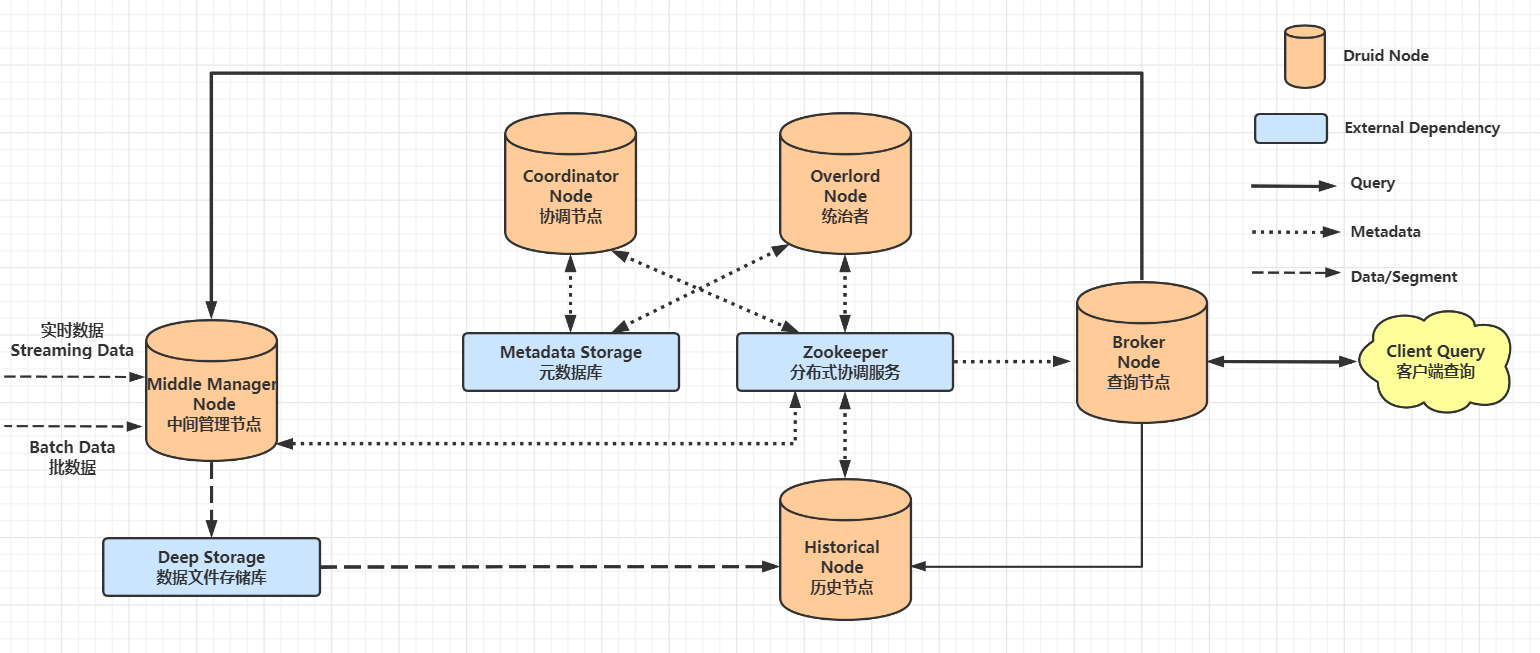
Druid的总体架构包含如下四类节点。
- 中间管理节点(MiddleManager Node):及时摄入实时数据,并生成 Segment 数据文件。
- 历史节点(Historical Node):加载已生成的数据文件,以供用户查询数据。
- 查询节点(Broker Node):对外提供数据查询服务,并同时从中间管理节点与历史节点中查询数据,合并后返回调用方。
- 协调节点(Coordinator Node):负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期。
集群还包含如下三类外部依赖:
-
元数据库(Metadata Storage):存储Druid 集群的元数据信息,比如,Segment 的相关信息,一般使用 MySQL 或 PostgreSQL 存储。
-
分布式协调服务(Zookeeper):为 Druid 集群提供一致性协调服务的组件,通常为 Zookeeper。
-
数据文件存储库(Deep Storage):存放生成的 Segment 数据文件,并提供历史服务器下载功能,对于单节点集群,可以是本地磁盘,而对于分布式集群,一般是 HDFS 或 NFS 。
Druid 数据结构
基于 DataSource 和 Segment 的 Druid 数据结构与 Druid 架构相辅相成,它们共同成就了 Druid 的高性能优势。
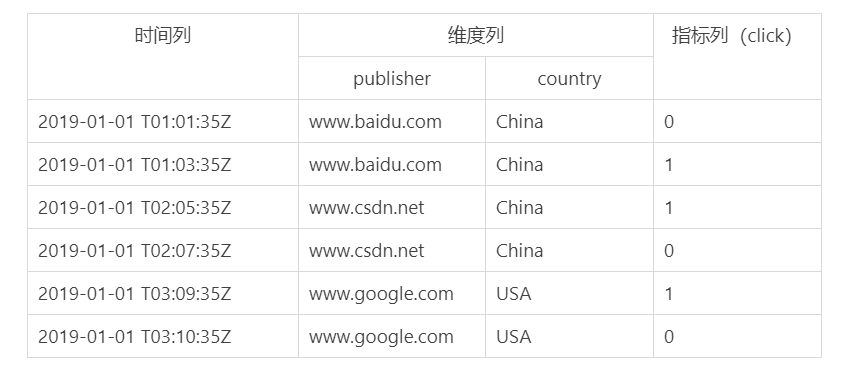
DataSource相当于关系型数据库中的表(Table)。DataSource的结构如下。
- 时间列:表明每行数据的时间值,默认使用UTC时间格式且精确到毫秒级。
- 维度列:维度来自OLAP的概念,用来标识数据行的各个类别信息。
- 指标列:用于聚合和计算的列。通常是一些数字,计算操作包括Count、Sum等。
DataSource 结构如表所示:
无论是实时摄取数据还是批量处理数据,Druid 在基于 DataSource 结构存储数据时,可选择对任意的指标列进行聚合操作。该聚合操作主要基于维度列与时间列。表显示的是 DataSource 聚合后的数据结构。
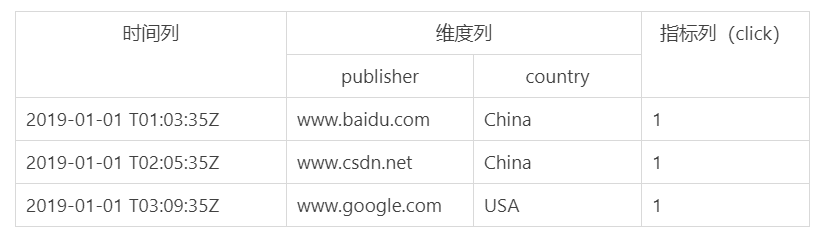
在数据存储时便可对数据进行聚合操作是 Druid 的特点,该特点使得 Druid 不仅能够节省存储空间,而且能够提高聚合查询的效率。
DataSource是一个逻辑概念,Segment是数据的实际物理存储格式。Druid将不同时间范围内的数据存储在不同的 Segment 数据块中,这便是所谓的数据横向切割。按照时间横向切割数据,避免了全表查询,极大地提高了效率。
在Segment中,采用列式存储格式对数据进行压缩存储(Bitmap压缩技术),这便是所谓的数据纵向切割。
Druid 安装
接下来为大家介绍如何安装 Druid,本次我们演示安装的是单机版。
安装部署
我们可以选择去官网 https://druid.apache.org/下载
另外我们也可以选择https://imply.io/,从 imply页面下载 Druid 最新版本的安装包。因为 imply 集成了Druid ,提供了 Druid 从部署到配置再到各种可视化工具的完整解决方案,所以这里我们使用了第 2 种方法 ~
(1)将 imply-2.7.10.tar.gz上传到 node01 节点的的 /opt/software 目录下,并解压到/export/servers目录下。
[root@node01 software]# tar -zxvf imply-2.7.10.tar.gz -C ../servers/(2)修改imply-2.7.10的名称为imply。
[root@node01 servers]# mv imply-2.7.10 imply(3)修改配置文件
① 修改 Druid 的 ZK 配置
[root@node01 servers]# vim imply/conf/druid/_common/common.runtime.properties需要修改的内容如下
druid.zk.service.host=node01:2181,node02:2181,node03:2181② 修改启动命令参数,使其不校验、不启动内置ZK。
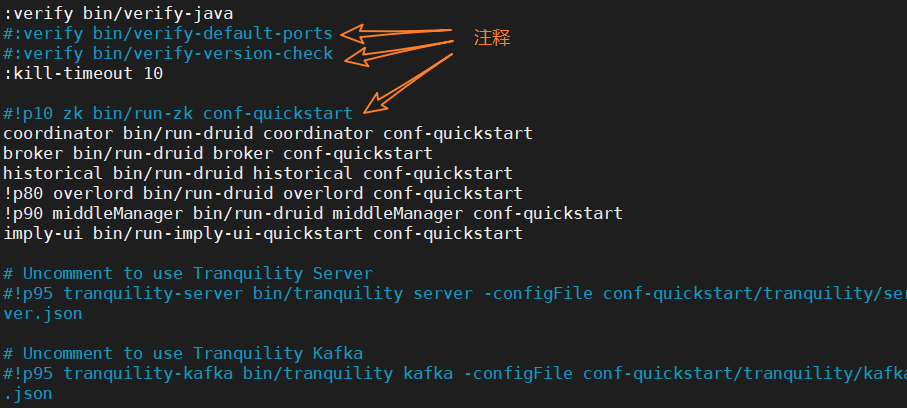
(4)启动
① 启动 Zookeeper
[root@node01 imply]# zk_startall.sh② 通过 bin 目录下的 supervise 命令启动 imply
[root@node01 imply]$ bin/supervise -c conf/supervise/quickstart.conf说明:每启动一个服务均会打印出一条日志。我们可以在/opt/module/imply/var/sv/目录下查看服务启动时的日志信息。
(1)启动成功之后呢,我们可以通过 ip:端口的方式进行访问,以我当前所安装 Druid 的节点 node01 为例,当我访问node01:9095/datasets,便可以在网页上看到如下界面:
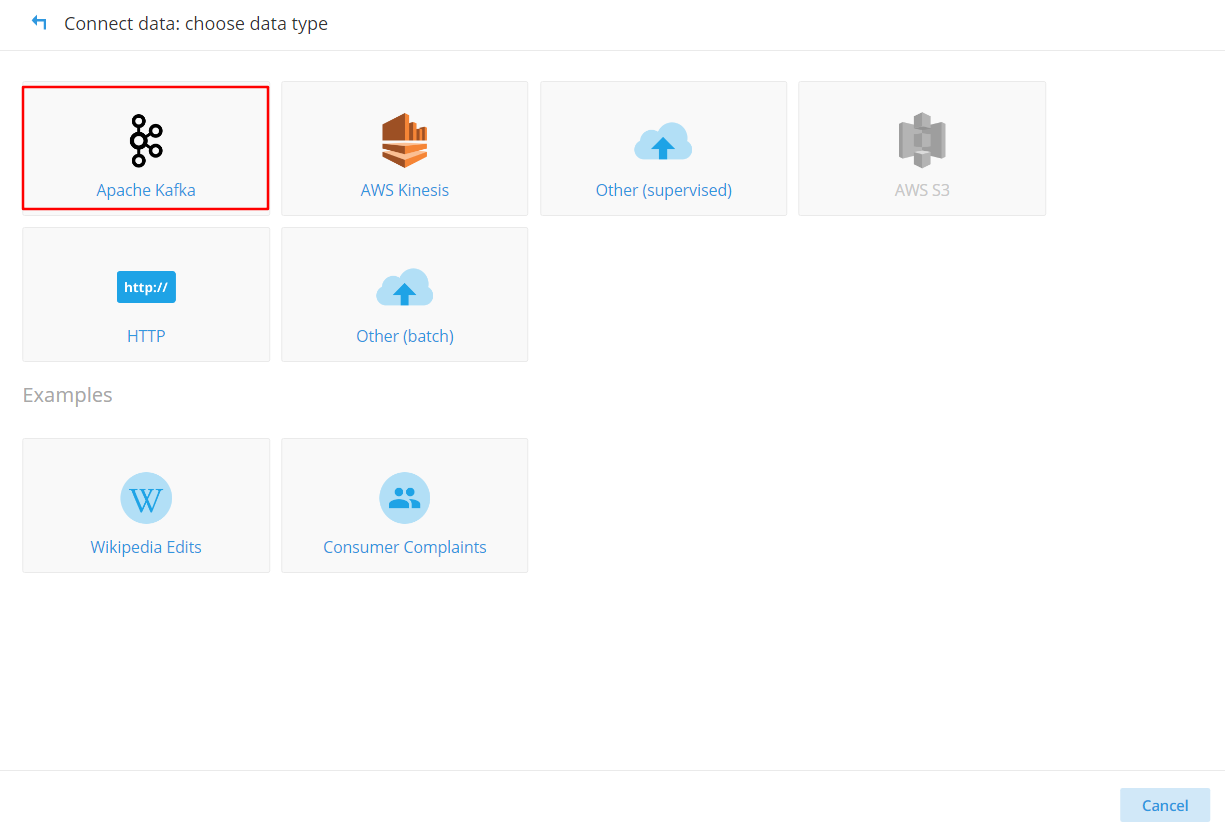
(2)单击“Load data”按钮,然后单击“Apache Kafka”按钮:
(3)添加 Kafka 集群和主题信息,并选择合适的格式化形式
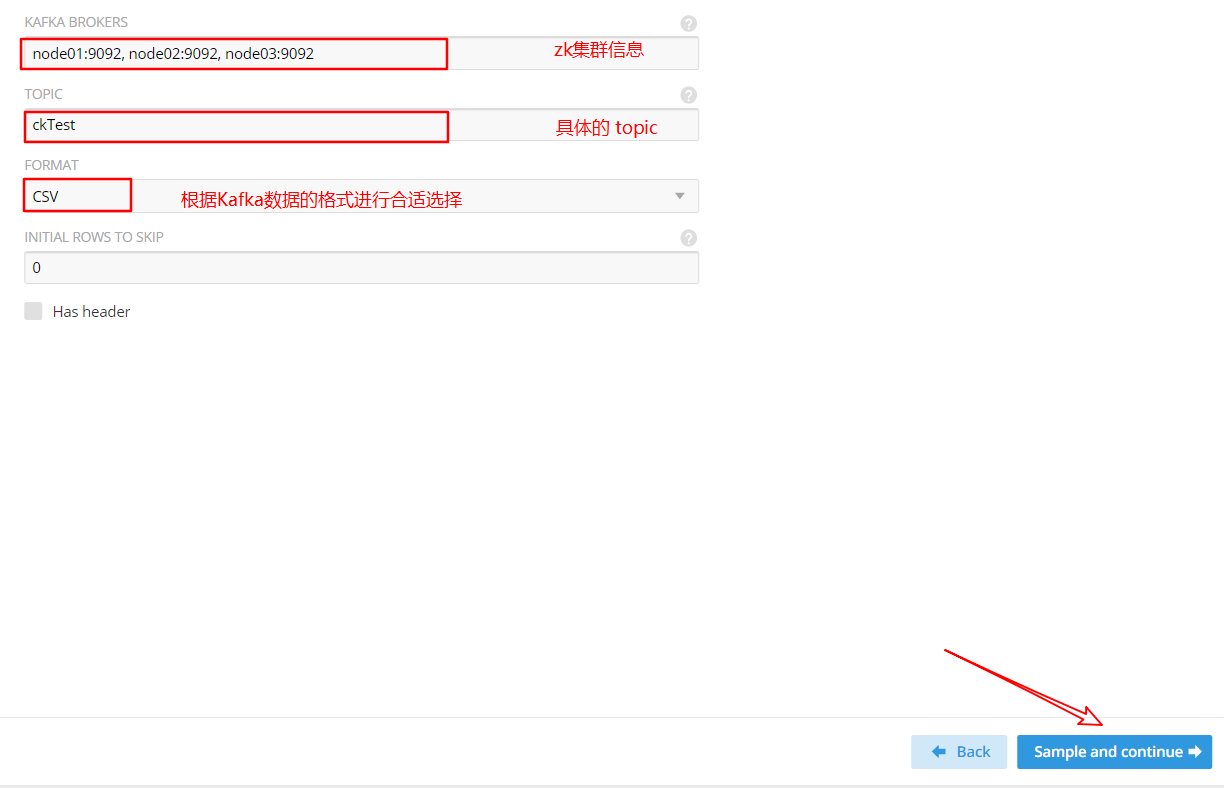
(4)确认数据样本格式
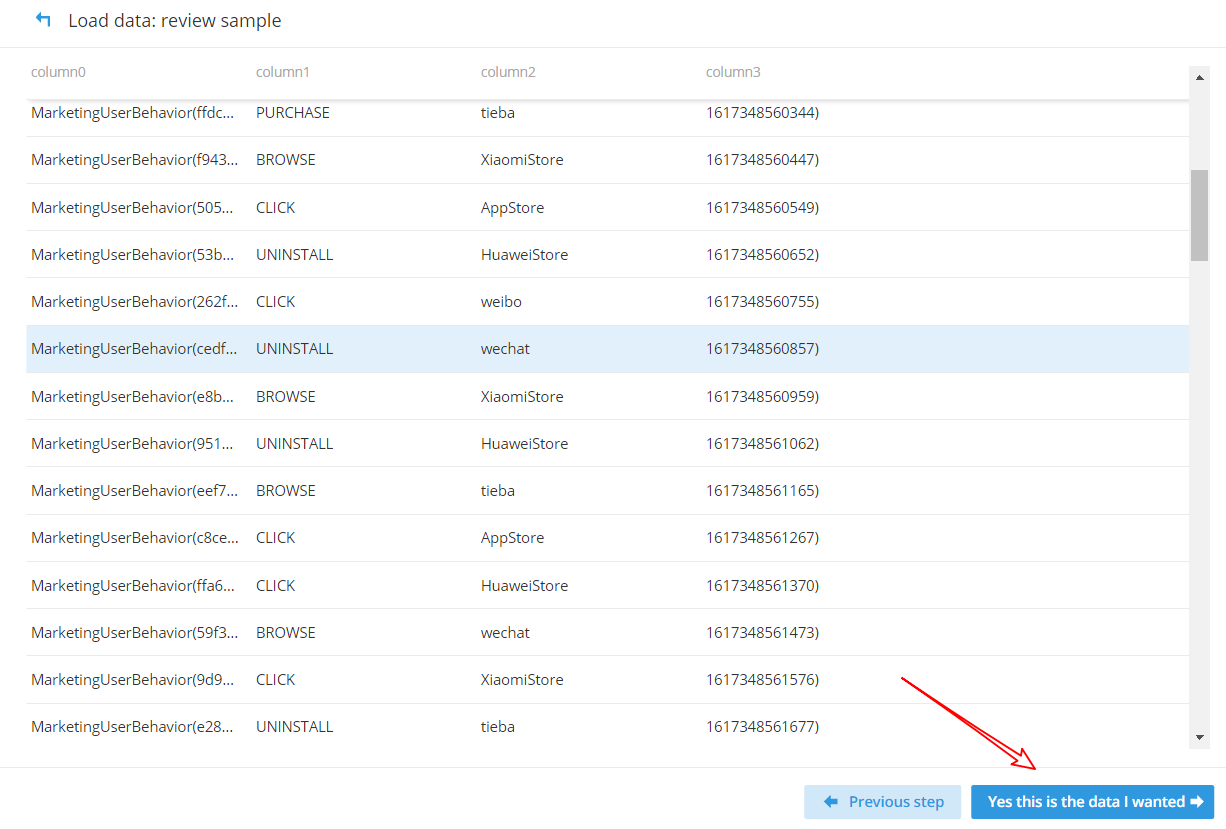
(5)加载数据,必须要有时间字段
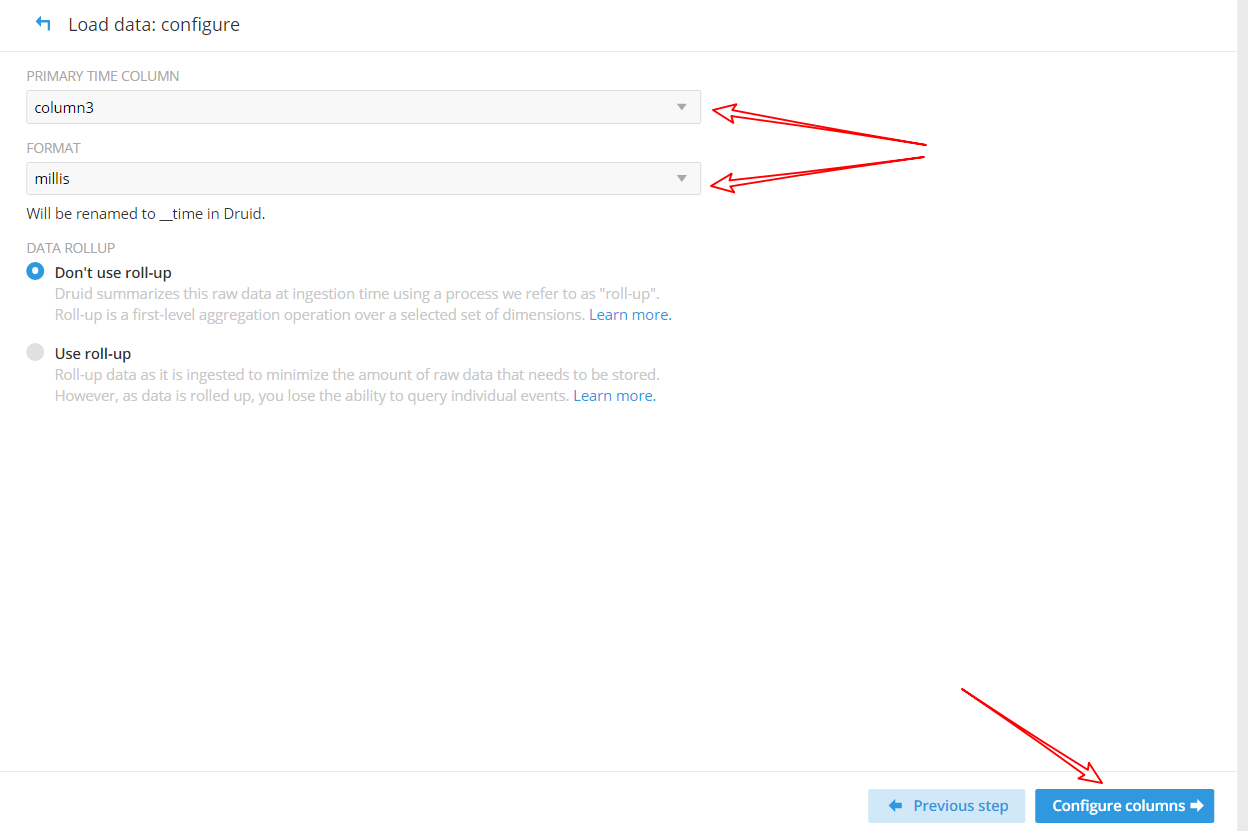
(6)配置要加载的列
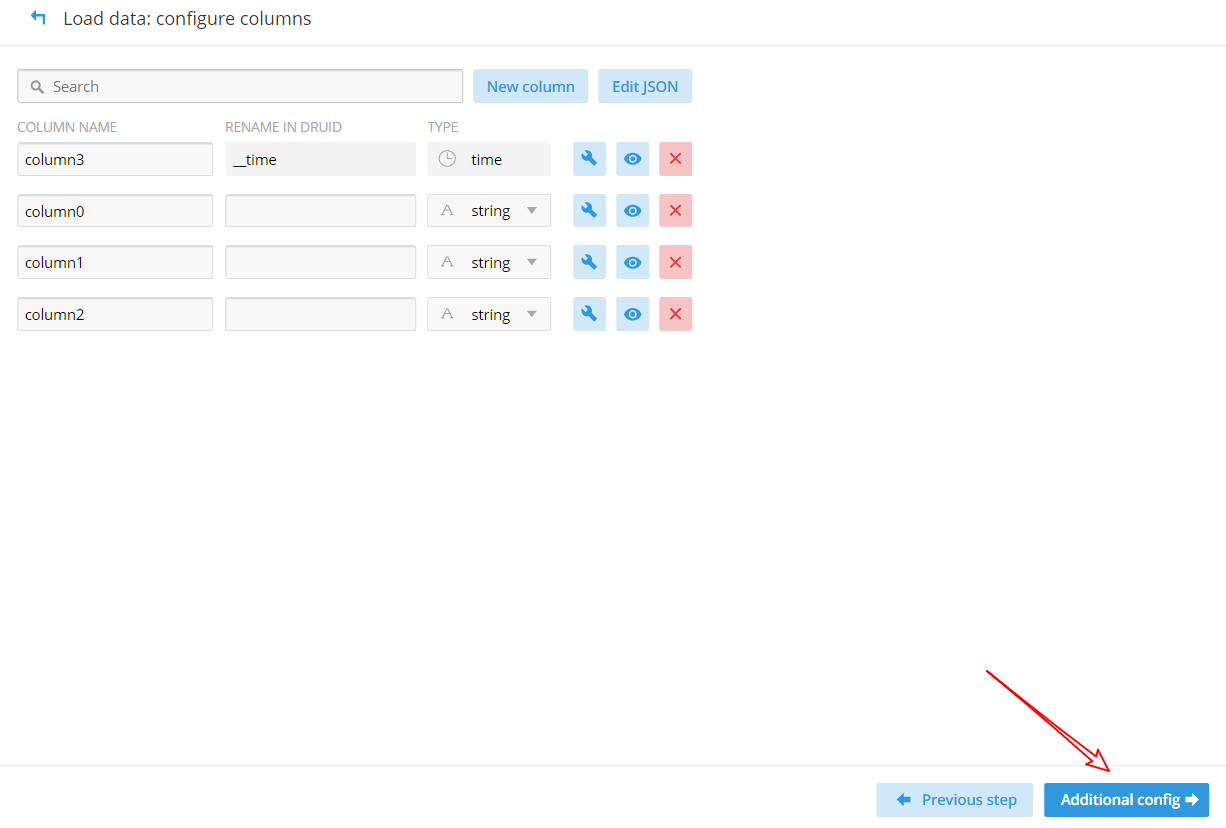
(7)配置 Kafka 数据源
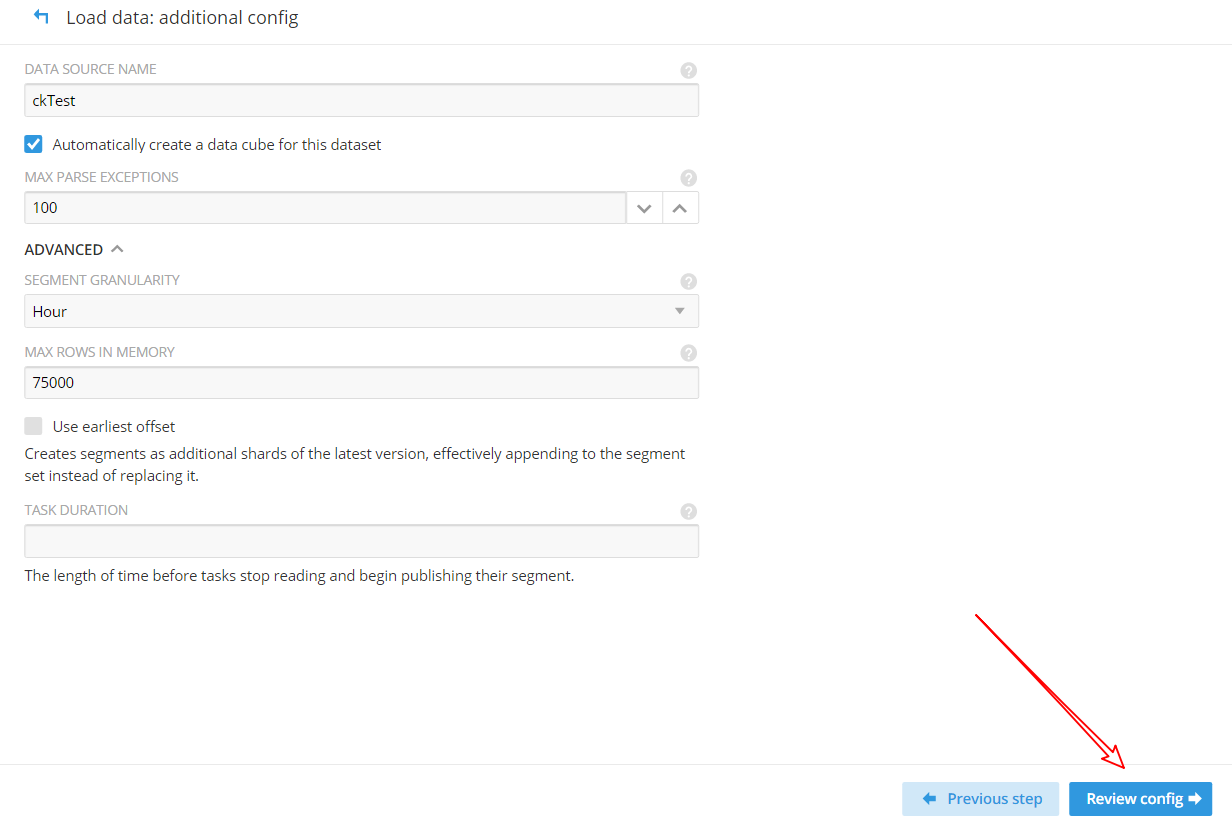
(8)确认加载数据的配置
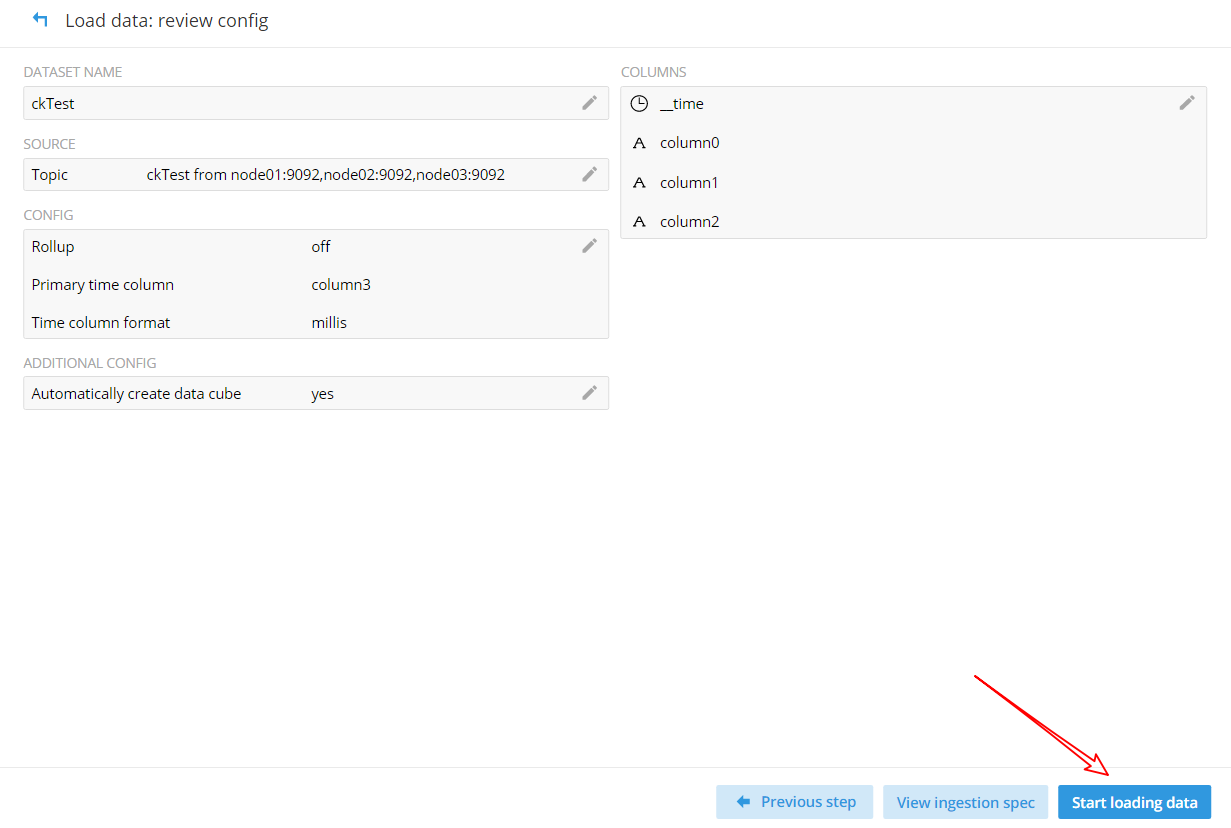
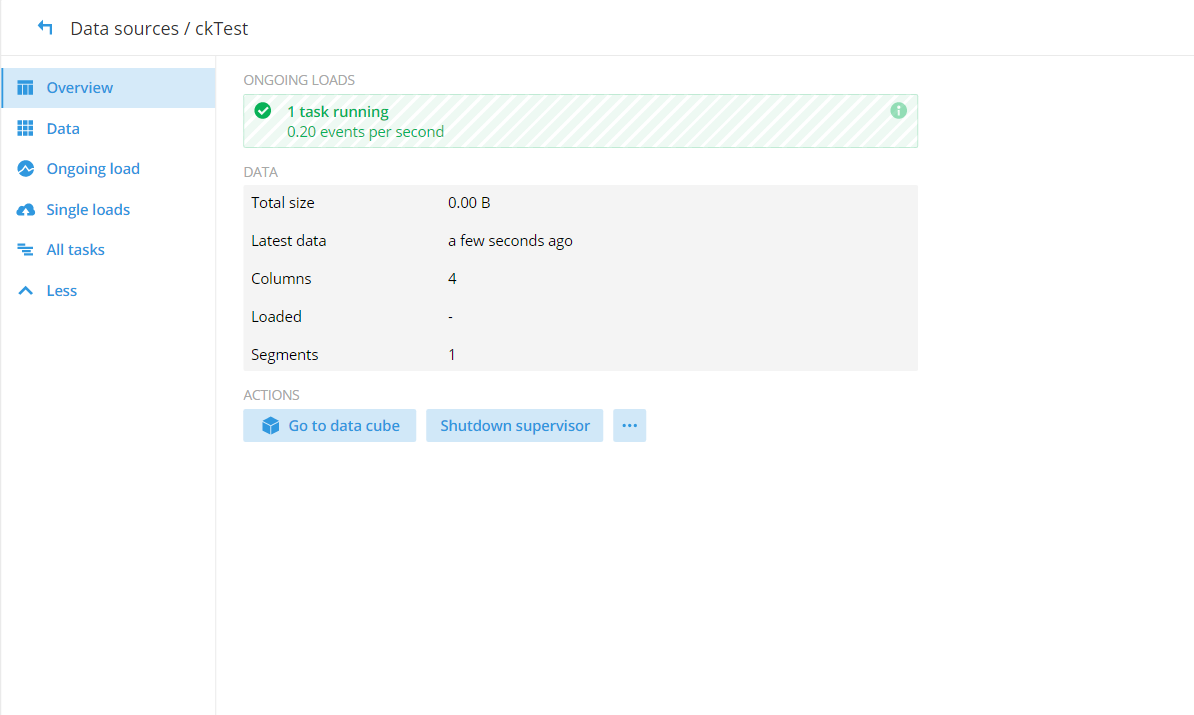
(9)连接 Kafka 的 topics_start,刚开始会显示 Connecting,加载完成之后便会显示如下图所示:
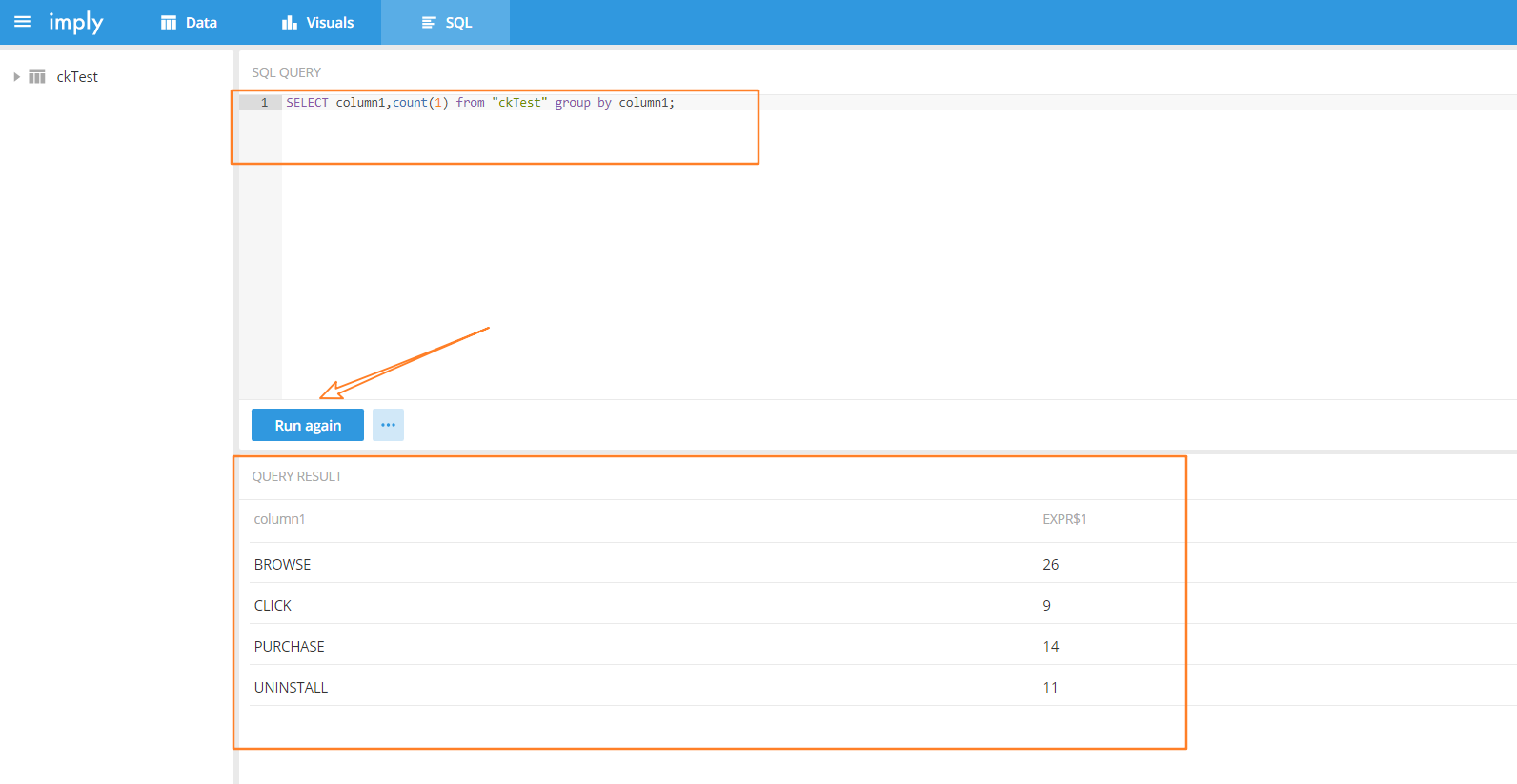
(10)选择 SQL
因为 topic 为ckTest里存储的都是用户行为数据,这里我写了一个 SQL 获取每种渠道所对应的数据量,如下所示:
巨人的肩膀
1、hhttps://druid.apache.org/ Druid 官网
2、https://www.jianshu.com/p/6f822e0f538c《Druid基本概念及架构介绍》
3、https://zhuanlan.zhihu.com/p/82038648《Apache Druid 简介》
小结
本期文章为大家介绍了 Druid 的简介,特点,使用场景,架构与数据结构,并用一个简单的 demo 为大家演示了 Druid 的具体使用。当然关于 Druid 值得探索的内容还有很多,限于文章篇幅不作过多介绍,希望大家能看完之后养成一种“自我驱动型学习”的能力,这才是最重要的!有疑问也欢迎找我探讨 ~ 你知道的越多,你不知道的也越多 ~ 我是 梦想家,我们下一期见!
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4306次2020-08-30 10:56:46
-
浏览量:1174次2023-03-14 10:09:41
-
浏览量:2795次2020-07-30 18:41:41
-
浏览量:9662次2020-12-12 14:56:13
-
浏览量:8282次2020-12-11 10:42:42
-
浏览量:2670次2017-11-23 18:22:37
-
浏览量:9166次2017-12-01 16:55:09
-
2020-02-19 14:15:02
-
2020-02-18 13:28:40
-
浏览量:1332次2023-11-23 11:04:00
-
浏览量:5304次2021-09-08 09:26:22
-
浏览量:5552次2021-03-18 09:43:14
-
浏览量:1766次2023-05-24 11:27:22
-
浏览量:8604次2019-09-26 16:29:28
-
浏览量:2101次2019-11-05 18:04:02
-
浏览量:1282次2023-01-12 17:08:25
-
浏览量:2167次2020-09-24 14:27:41
-
浏览量:1909次2020-07-13 19:27:07
-
2020-12-12 22:07:09
大数据梦想家
一枚有趣的程序员,更多精彩内容请移步公众号@大数据梦想家

-
8篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
大数据梦想家

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
